
- Google DeepMind ra Gemma 4 ngày 2/4/2026 dưới giấy phép Apache 2.0.
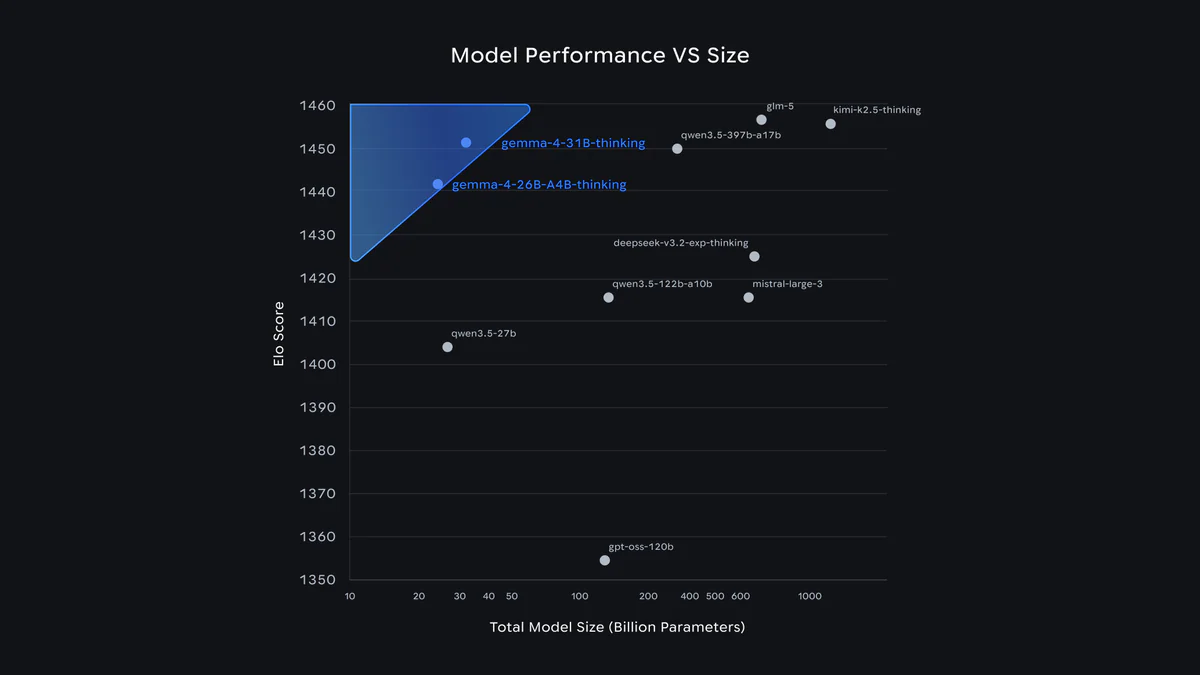
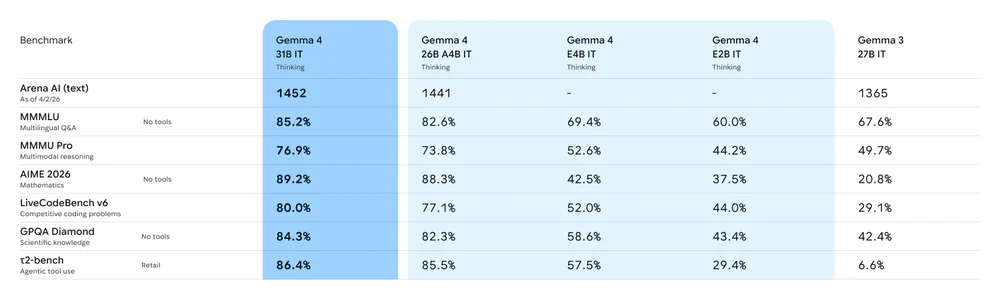
- Bản 31B Dense đạt 89,2% AIME 2026, 80% LiveCodeBench v6, Elo 1452 trên Arena AI và đứng #3 bảng xếp hạng open model — trong khi bản E2B chạy offline trên Raspberry Pi, điện thoại với context 256k cho các dòng MoE/Dense.
TL;DR
Ngày 2/4/2026, Google DeepMind công bố Gemma 4 — họ mô hình mở 4 kích cỡ (E2B, E4B, 26B A4B MoE, 31B Dense), cấp phép Apache 2.0 không ràng buộc số MAU. Bản 31B Dense đạt 89,2% trên AIME 2026 math, 80,0% LiveCodeBench v6, 84,3% GPQA Diamond và Elo 1452 trên Arena AI — vượt Llama 4 (~400B MoE) ở cả bốn benchmark với kích thước nhỏ hơn ~20 lần. Hai bản edge E2B/E4B chạy offline trên điện thoại, Raspberry Pi, Jetson Nano và hỗ trợ audio native. Dòng 26B/31B có context 256K token — đủ để nhét nguyên repo vào một prompt.
Điểm mới chính
- Bốn kích cỡ, một DNA: E2B (2,3B effective), E4B (4,5B effective), 26B A4B MoE (25,2B tổng / 3,8B active) và 31B Dense (30,7B).
- Thinking mode cấu hình được: bật token
<|think|>trong system prompt để mô hình suy luận từng bước trước khi trả lời. Có thể tắt để tiết kiệm token. - Function calling bake sẵn: 6 token đặc biệt cho tool declaration/call/response, structured JSON output, system role — đủ xịn cho agentic workflow mà không cần prompt engineering phức tạp.
- Đa phương tiện native: tất cả bản đều xử lý text + ảnh (biến đổi aspect ratio, visual token budget 70/140/280/560/1120) + video. E2B/E4B bổ sung audio input (ASR + speech-to-translated-text).
- Kiến trúc: xen kẽ local sliding-window (512/1024 token) và global full-context attention; dual RoPE; Per-Layer Embeddings; Shared KV Cache.
- Giấy phép Apache 2.0: thương mại không giới hạn, bỏ ràng buộc MAU kiểu Llama.
Vì sao quan trọng
Gemma 4 là minh chứng rõ nhất đến nay cho việc kỷ nguyên "đua số tham số" đã đến hồi lợi nhuận giảm dần. Jim Fan (NVIDIA) gọi kết quả này là "paradigm shift — đường cong intelligence-per-FLOP vừa cong đột ngột. Điều này thay đổi kinh tế triển khai AI cho tất cả mọi người." Percy Liang (Stanford CRFM) đồng tình: đổi mới kiến trúc và hiệu quả huấn luyện đã thay thế việc nhân đôi tham số làm động lực tăng trưởng.
Với enterprise, ý nghĩa trực tiếp: bản 31B Dense chạy lọt vào một RTX 4090 24GB VRAM, bỏ qua được cụm multi-GPU trị giá $30.000 trở lên. Bản bfloat16 unquantized vẫn vừa một H100 80GB. Andrew Ng tóm gọn: "Đa số doanh nghiệp không cần mô hình nghìn tỷ tham số — họ cần mô hình tin cậy, an toàn, hiệu quả và kiểm soát được. Gemma 4 đúng như vậy."
Số liệu kỹ thuật
| Benchmark | Gemma 4 31B | 26B A4B | E4B | E2B | Gemma 3 27B |
|---|---|---|---|---|---|
| Arena AI (text) 4/2/26 | 1452 | 1441 | — | — | 1365 |
| MMLU Pro | 85,2% | 82,6% | 69,4% | 60,0% | 67,6% |
| AIME 2026 (no tools) | 89,2% | 88,3% | 42,5% | 37,5% | 20,8% |
| LiveCodeBench v6 | 80,0% | 77,1% | 52,0% | 44,0% | 29,1% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 | 110 |
| GPQA Diamond | 84,3% | 82,3% | 58,6% | 43,4% | 42,4% |
| MRCR v2 128K | 66,4% | 44,1% | 25,4% | 19,1% | 13,5% |
Bản 31B Dense xếp #3 open model trên Arena AI text leaderboard, bản 26B MoE xếp #6 — và hai mô hình này chỉ cần context 256K token, chạy được trên GPU tiêu dùng. Codeforces ELO 2150 của 31B là ngưỡng master competitive coder.
So sánh với đối thủ
| Benchmark | Gemma 4 31B | Llama 4 (~400B MoE) | DeepSeek V4 | GPT |
|---|---|---|---|---|
| AIME 2026 Math | 89,2% | 88,3% | 42,5% | 37,5% |
| LiveCodeBench v6 | 80,0% | 77,1% | 52,0% | 44,0% |
| GPQA Diamond | 84,3% | 82,3% | 58,6% | 43,4% |
| τ2-bench Agentic (Retail) | 86,4% | 85,5% | 57,5% | 29,4% |
| Arena AI rank (open) | #3 | #5 | #8 | closed |
Nathan Lambert (Interconnects) ghi nhận 31B Dense ngang ngửa Qwen 3.5 27B — mô hình mở dẫn đầu phân khúc ~30B trước đó. So với thế hệ trước, bước nhảy sinh học: AIME 20,8% → 89,2%, LiveCodeBench 29,1% → 80,0%, GPQA 42,4% → 84,3%.
Ứng dụng thực tế
- Agent offline trên điện thoại: E2B là nền tảng cho Gemini Nano 4 trên Android. Kết hợp audio input native, dev có thể dựng voice assistant chạy hoàn toàn local, không round-trip cloud.
- Coding assistant local-first: 26B MoE ở quantization Q4_K_M chỉ chiếm ~18GB VRAM nhưng active param chỉ 3,8B → tốc độ sinh gần bằng mô hình 4B. 256K context cho phép đưa nguyên repo vào một prompt.
- Agentic workflow: function calling với 6 token đặc biệt ghép tốt với MCP server (ví dụ SearXNG) và harness như Pi. Ít trường hợp "mô hình nhỏ không biết khi nào gọi tool" thường thấy ở open model khác.
- Fine-tune chuyên ngành: Yale đã fine-tune cho Cell2Sentence-Scale để tìm pathway trị ung thư; INSAIT tạo BgGPT — LLM tiếng Bulgaria đầu tiên. TRL có example dạy Gemma 4 lái xe tránh người đi bộ trong sim CARLA.
Hạn chế & giá
Miễn phí dưới Apache 2.0, không giới hạn MAU. Yêu cầu phần cứng:
- E2B/E4B: smartphone, Raspberry Pi 5, Jetson Orin Nano.
- 26B MoE: GPU tiêu dùng 16GB+ VRAM.
- 31B Dense: 24GB+ VRAM (RTX 4090) hoặc H100 80GB cho bfloat16, hoặc Cloud TPU.
Bất cập lớn nhất hiện tại: Google strip bỏ Multi-Token Prediction heads khỏi open weights (chỉ có trong LiteRT proprietary), khiến 31B bị giới hạn ~11 tok/s trên một số máy trong khi các mô hình lớn gấp đôi chạy tới 50+ tok/s. Cộng đồng đã có workaround: EAGLE3 draft head (+277MB, ~2× speedup, acceptance 0,75–0,82) và speculative decoding dùng E2B làm draft model cho 31B. Ngoài ra, 26B và 31B không hỗ trợ audio input — audio chỉ có ở E2B/E4B.
Tiếp theo
Weights đã có ngày đầu trên Hugging Face, Kaggle, Ollama, LM Studio, Docker, Vertex AI, Google AI Studio, vLLM, llama.cpp, MLX, Mistral.rs, NVIDIA NIM/NeMo, Unsloth, SGLang. Android developer có thể prototype agentic flow qua AICore Developer Preview để tương thích sẵn với Gemini Nano 4. Android Studio bật Agent Mode chạy trên Gemma 4. Interconnects úp mở rằng một bản MoE >100B total params đang được chuẩn bị nhưng chưa ra. Kaggle đã mở Gemma 4 Good Challenge cho cộng đồng.
Nguồn: blog.google, Google DeepMind, Hugging Face, Model Card, Interconnects, XDA Developers.

