
- Elliot Arledge công bố benchmark single-stream: Qwen3.6-35B-A3B (3B active) + DFlash drafter ở c=1 đạt 164 tokens/sec decode trên prompt creative writing — vượt xa con số 60-90 tok/s mà DGX Spark báo cáo, cho thấy combo MoE sparse + block-diffusion speculative decoding đang mở ra một trần tốc độ mới cho LLM 35B chạy local.
TL;DR
- Qwen3.6-35B-A3B + drafter DFlash ở concurrency=1 chạm 164 tokens/sec decode trên creative writing — báo cáo của Elliot Arledge trên X.
- Đây là single-stream nhanh hơn cả benchmark chính thức trên DGX Spark (median 83.9 tok/s, p95 127.5 tok/s) — chứng tỏ combo MoE 3B-active + block diffusion drafter còn dư tiềm năng tuỳ rig.
- DFlash là speculative decoding bằng block diffusion: thay vì draft tuần tự như EAGLE-3, nó sinh K token trong 1 forward pass, đạt 6× lossless speedup so với decode thường, 2.5× so với EAGLE-3.
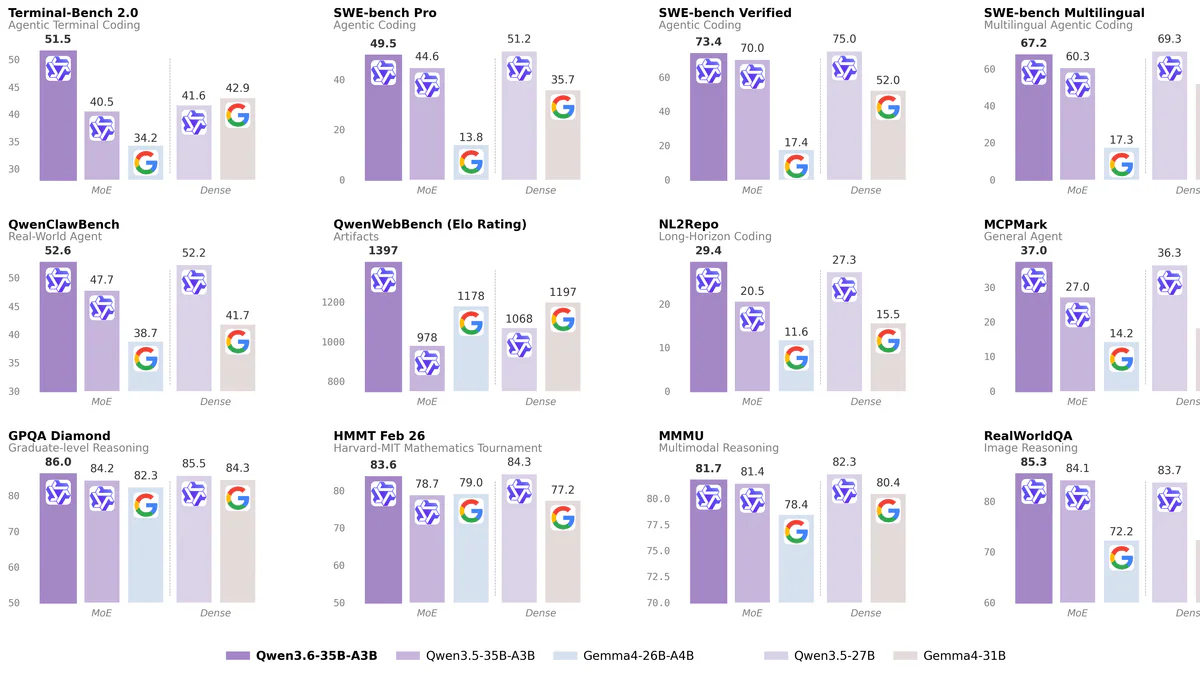
- Qwen3.6-35B-A3B chỉ active 3B/35B params, vượt Qwen3.5-27B dense trên Terminal-Bench 2.0 (51.5 vs 41.6) và đạt 73.4 SWE-bench Verified.
- Open weights Apache 2.0, drafter MIT — chạy được trên vLLM, SGLang, Transformers, MLX, KTransformers.
Có gì mới
Ngày 14/04/2026, Alibaba mở source Qwen3.6-35B-A3B — một MoE 35B tổng tham số nhưng chỉ active 3B mỗi token. Cùng thời điểm, z-lab phát hành drafter Qwen3.6-35B-A3B-DFlash đi kèm framework DFlash — block diffusion drafter cho speculative decoding.
Mới đây, Elliot Arledge (@elliotarledge) báo cáo trên X: cấu hình DFlash c=1 chạy single-stream 164 tokens/sec trên prompt creative writing với target Qwen3.6 35B (3B active). Con số này đáng chú ý vì nó nằm trên cận trên của các benchmark đã công bố — DGX Spark NVFP4 + DFlash trong cấu hình production chỉ đạt p95 127.5 tok/s trên math/code, còn open-ended prompt thường về 60-90 tok/s.
Tại sao quan trọng
164 tok/s single-stream trên một model 35B nghe quen thuộc với ai từng theo dõi LLM inference: đó là tốc độ trước đây chỉ thấy ở model dense 7-13B chạy quantize. Sự khác biệt nằm ở hai yếu tố cộng hưởng:
- MoE sparse: Qwen3.6 chỉ kích hoạt 8 routed experts + 1 shared expert trên 256 experts mỗi token. Compute cost = 3B params, không phải 35B.
- Block diffusion drafter: DFlash sinh K mask token cùng lúc trong 1 denoising step, sau đó target model verify K token đó song song. So với EAGLE-3 (draft tuần tự từng token), DFlash bỏ hoàn toàn bottleneck sequential ở phase draft.
Tích cộng hai cái: chạy 35B-class quality ở compute footprint của 3B, draft song song bằng diffusion → tốc độ decode bị đẩy lên ngưỡng vốn không khả thi với autoregressive thuần.
Kỹ thuật cốt lõi
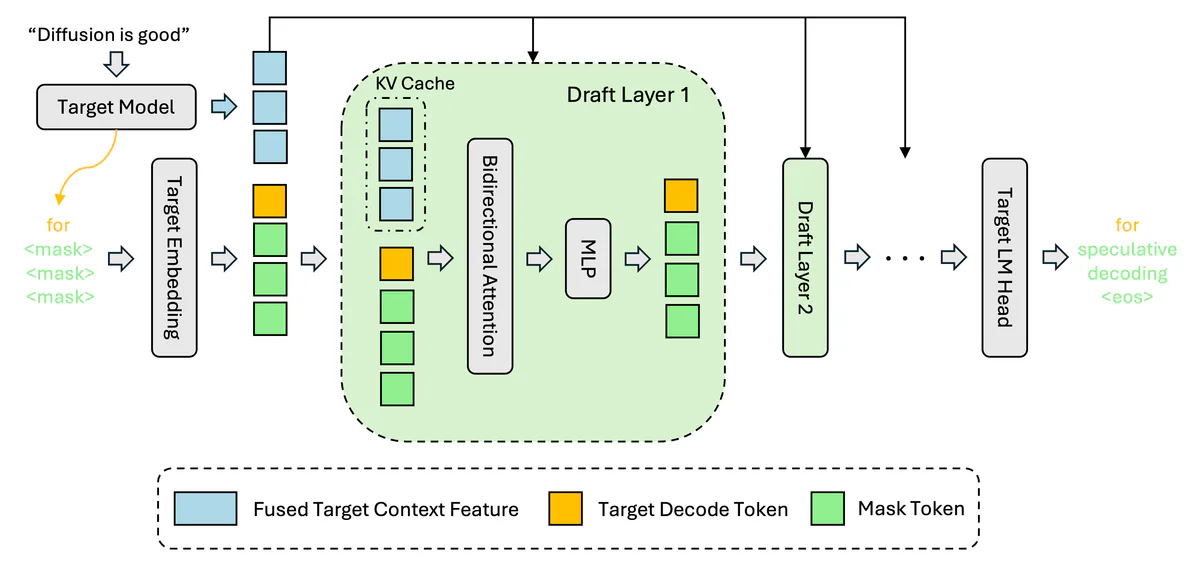
Kiến trúc Qwen3.6-35B-A3B:
| Thành phần | Giá trị |
|---|---|
| Total / Active params | 35B / 3B |
| Layers | 40 |
| Experts | 256 (8 routed + 1 shared / token) |
| Attention | Gated DeltaNet (linear) + Gated Attention (16 Q heads / 2 KV heads) |
| Native context | 262,144 tokens |
| YaRN extended | 1,010,000 tokens |
Đo thực tế trên DGX Spark (NVIDIA GB10) với NVFP4 + DFlash (k=15):
- Single-stream decode (T=0): median 83.9 tok/s, p95 127.5 tok/s.
- Greedy
qwen36-fast(T=0): 78% DFlash acceptance, 117 tok/s. - Sampled
qwen36-deep(T=0.7): acceptance giảm, ~50 tok/s. - Aggregate plateau ở 64 concurrent: 313 tok/s.
- Acceptance rate tổng quát: 62-78% position-0, 2.7-4.4 mean accepted tokens / target step.
Kết quả 164 tok/s của Arledge chưa kèm hardware spec đầy đủ, nhưng cao hơn p95 DGX Spark 1.3× — có thể do prompt class thuận lợi (creative writing với pattern lặp), batch=1 không có draft contention, và rig của anh có bandwidth tốt hơn cấu hình production NVFP4.
So sánh
| Mode | Drafter | Speedup vs vanilla |
|---|---|---|
| Standard autoregressive | — | 1.0× |
| EAGLE-3 | Autoregressive head | ~3× (draft tuần tự) |
| DFlash | Block diffusion | ~6× lossless, 2.5× vs EAGLE-3 |
Trên benchmark coding agent, Qwen3.6-35B-A3B đạt SWE-bench Verified 73.4 (vs Qwen3.5-35B-A3B 70.0, Gemma4-31B 52.0), Terminal-Bench 2.0 51.5 (cao nhất nhóm), QwenWebBench 1397 (vs Qwen3.5-27B 1068). Multimodal MMMU 81.7 vượt Claude-Sonnet-4.5 (79.6) và Gemma4-31B (80.4).
Ai hưởng lợi
- Indie dev / single-GPU rig: Arledge chứng minh combo này chạy single-stream cực nhanh — đủ cho local agent, code assistant, creative writing tool.
- Latency-sensitive chat (batch 1-4): DFlash high acceptance + TTFT < 500 ms.
- Multi-turn agent + SGLang RadixAttention: KV cache + block diffusion bù trừ, lý tưởng cho OpenClaw, Claude Code, Qwen Code.
- Code generation: Pattern code có cấu trúc → acceptance rate cao nhất → tốc độ tăng mạnh nhất.
Backend hỗ trợ: vLLM (nightly), SGLang, Hugging Face Transformers, MLX (Apple Silicon), KTransformers (CPU+GPU heterogeneous).
Giới hạn & chi phí
- High concurrency (batch 32+): draft overhead có thể vượt phần tiết kiệm — chuyển về standard decode.
- Output ngắn (<50 tokens): setup speculation không bù đủ.
- Drafter mismatch: Qwen2.5 chưa có DFlash drafter — fallback EAGLE-3.
- Long-context bug đã fix 2026-04-19: drafter cũ crash
cudaErrorIllegalAddresssau ~16K tokens — re-pull từ HF. - Production NVFP4 image của AEON-7 chỉ chạy GB10: Hopper/Ampere/B200 phải rebuild.
- Chi phí cloud: H100 PCIe ($2.01/h) + DFlash projected ~9,000 tok/s aggregate → ~$0.06 per 1M output tokens.
License: Qwen3.6 Apache 2.0 (commercial OK). DFlash framework MIT.
Sắp tới
z-lab thông báo sẽ open-source training recipe để cộng đồng tự train DFlash drafter cho model riêng. Drafter cho Qwen3.5-397B-A17B và GLM-5.1 đang sắp ra mắt. Một kiến trúc kế tiếp tên DTree nằm trong roadmap. Phía Qwen cam kết mở rộng family Qwen3.6 — có thể là biến thể coder hoặc dense.
Nếu bạn đang serve LLM 35B class cho agent hoặc latency-sensitive workload, kết hợp Qwen3.6-35B-A3B + DFlash là benchmark mới cần đo trên rig của bạn — kết quả có thể vượt xa con số production reference.
Nguồn: @elliotarledge tweet, Qwen blog, DFlash paper (arXiv 2602.06036), Spheron DFlash deployment guide, z-lab HF.

