
- Tencent's Hunyuan team just shipped Hy3 preview — a 295B MoE with only 21B active per token, 256K context, SWE-bench Verified 74.4, and a 40% efficiency gain over HY 2.0.
- The pitch is cheap, fast, agent-ready inference, not a leaderboard crown.
TL;DR
On April 23, 2026 Tencent open-sourced Hy3 preview — a 295B-parameter Mixture-of-Experts model with 21B active parameters per token, a 256K context window, and a stated 40% reasoning-efficiency gain over the previous HY 2.0 flagship. It scores 74.4 on SWE-bench Verified, 54.4 on Terminal-Bench 2.0, 67.1 on BrowseComp, and 70.2 on WideSearch. Weights are live on Hugging Face, ModelScope, and GitCode. Tencent is explicit that this is a reset, not a frontier-model claim — the bet is cheaper inference plus product feedback, with the model already wired into Yuanbao, CodeBuddy, WorkBuddy, QQ, and Tencent Cloud.

What's new
Hy3 preview is the first model out of a three-month rebuild of Tencent Hunyuan's pre-training and reinforcement-learning infrastructure, led by chief AI scientist Yao Shunyu — the former OpenAI researcher behind ReAct, the original reasoning-and-action framework for tool-using LLMs. The architecture is a dense-MoE hybrid: 192 routed experts with top-8 activated, plus one shared expert per MoE layer and a 3.8B Multi-Token-Prediction layer.
Tencent also shipped a separate Hy3 preview-Base checkpoint for fine-tuning, an AngelSlim quantization toolkit, and full vLLM and SGLang deployment recipes. The release coincides with the international beta of QClaw, Tencent's consumer agent that talks to users via WhatsApp, Telegram, and email.
Why it matters
Most 2025 frontier announcements pushed past 1T parameters. Hy3 preview goes the other way: HY 2.0 had 400B+ total params; Hy3 preview drops to 295B and only fires ~7% of weights per token. That makes the whole model quantizable to a single node — the "engineering sweet spot" for teams that want to actually run frontier-class agents in production without multi-node inference plumbing.
Translation: this is a model designed to be used all day, not benchmarked once. Tencent is pricing it like infrastructure (¥1.2 per million input tokens) and shoving it straight into apps that already have hundreds of millions of users.
Technical facts
| Property | Value |
|---|---|
| Architecture | Dense + MoE hybrid (192 experts, top-8) |
| Total parameters | 295B |
| Active per token | 21B (~7%) |
| MTP layer | 3.8B (1 layer) |
| Layers | 80 (excluding MTP) |
| Attention | 64 heads, GQA with 8 KV heads, head dim 128 |
| Hidden / intermediate | 4096 / 13312 |
| Vocabulary | 120,832 |
| Context length | 256K |
| Precision | BF16 |
| License | Tencent Hy Community License Agreement |
Recommended sampling: temperature=0.9, top_p=1.0. Reasoning controls expose two modes via reasoning_effort: "high" for math / code / multi-step reasoning, "no_think" for fast direct answers — a clean fast-and-slow-thinking switch baked into the API surface.
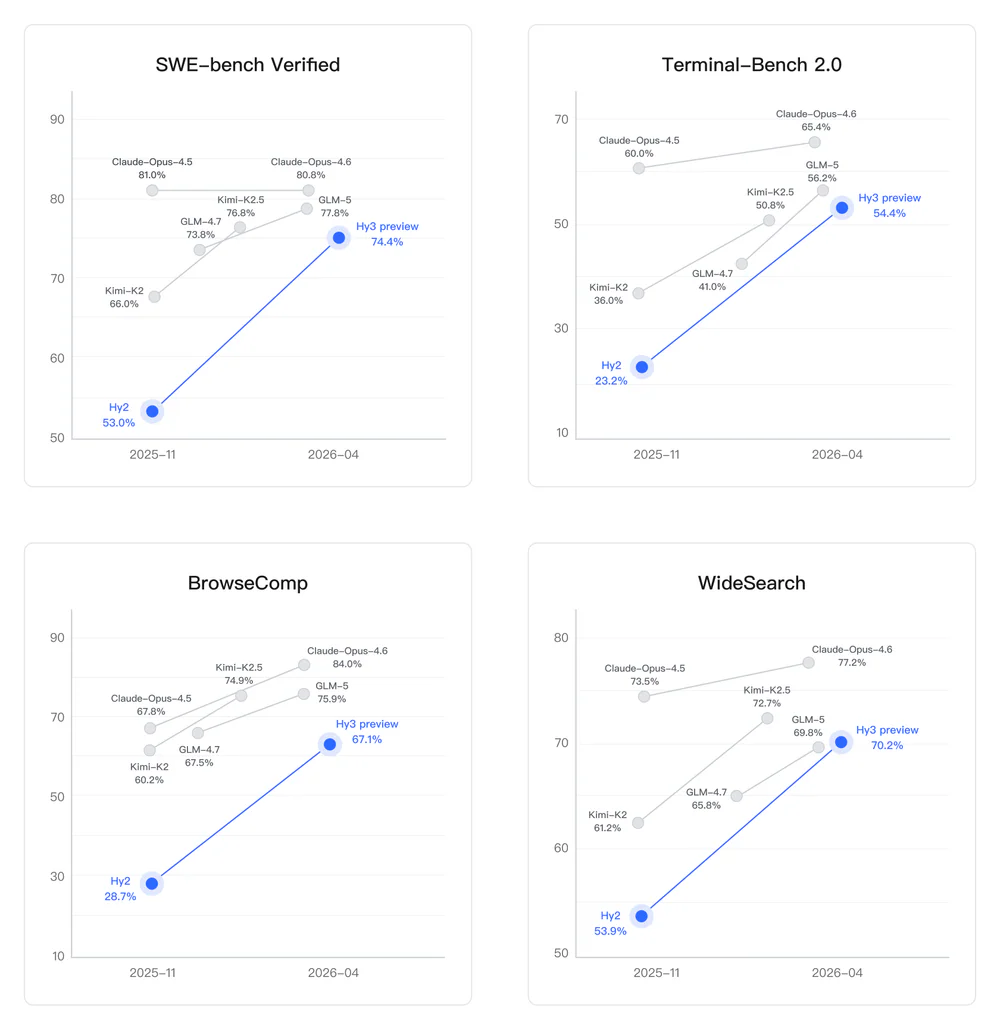
Benchmarks
Public scores from the Hugging Face model card:
| Benchmark | Hy3 preview | Hy2 (Nov 2025) | Best peer |
|---|---|---|---|
| SWE-bench Verified | 74.4 | 53.0 | Claude-Opus-4.6 — 80.8 |
| Terminal-Bench 2.0 | 54.4 | 23.2 | Claude-Opus-4.6 — 65.4 |
| BrowseComp | 67.1 | 28.7 | Claude-Opus-4.6 — 84.0 |
| WideSearch | 70.2 | 53.9 | Claude-Opus-4.5 — 73.5 |
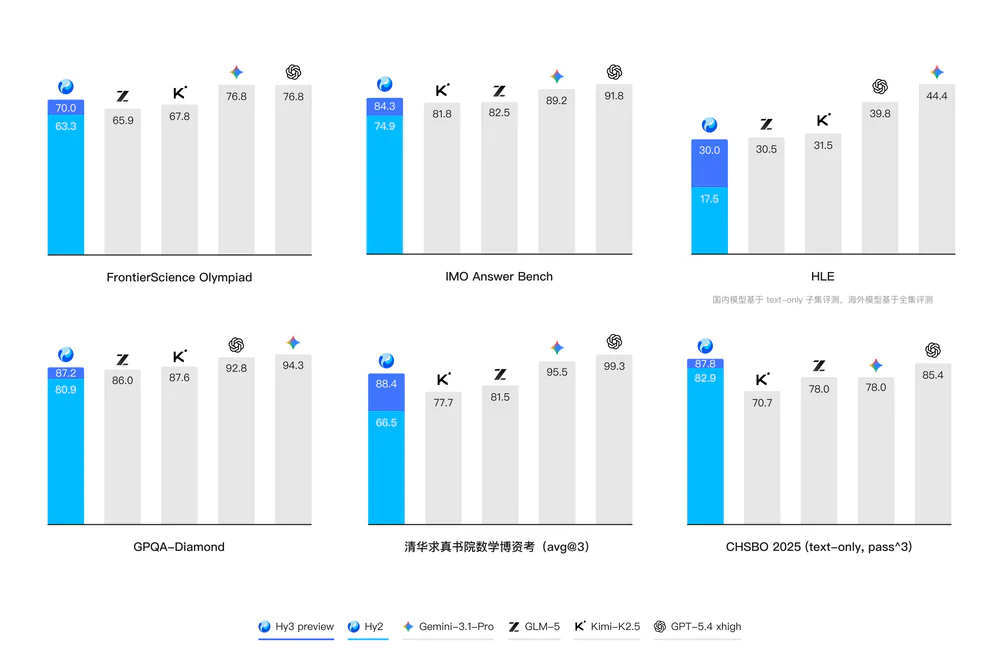
| GPQA Diamond | 87.2 | — | — |
| HLE (Humanity's Last Exam) | 30 | — | — |
The deltas vs Hy2 are the eye-catcher: +21.4 on SWE-bench, +31.2 on Terminal-Bench, +38.4 on BrowseComp. Tencent isn't beating Claude Opus 4.6 — it's catching up to the "next-best open model" tier (GLM-5, Kimi-K2.5) while undercutting them on inference price.
Comparison
| Property | HY 2.0 (Dec 2025) | Hy3 preview (Apr 2026) |
|---|---|---|
| Total params | 400B+ | 295B |
| Active per token | dense-style | 21B (sparse MoE) |
| Context | — | 256K |
| Reasoning efficiency | baseline | +40% |
| Single-node serving | no | yes (quantized) |
Versus US frontier: SCMP confirms Tencent positions Hy3 preview as "on par with top Chinese models but still lagging flagship products from OpenAI and Google DeepMind" — an unusually candid framing for a launch.
Use cases
- Code agents. CodeBuddy reports −54% first-token latency, −47% end-to-end duration, and success rates above 99.99% in internal blind tests vs the previous backbone.
- Multi-step web/browse agents. Tencent claims agent loops up to 495 steps without losing the thread. Strong BrowseComp / WideSearch numbers back the design intent.
- Knowledge-worker copilots. WorkBuddy ships 20+ skill packs with MCP support, integrates with WeCom / QQ / Feishu / DingTalk, and lets users explicitly switch between Hy and external models like GLM, Kimi, MiniMax — neutral-orchestrator positioning.
- Consumer agents. QClaw, the international beta, wraps the OpenClaw framework in zero-config WhatsApp / Telegram / email frontends. Tencent says 99% of the international app's code was generated autonomously by QClaw itself in five days.
Limitations & pricing
- Trails OpenAI / Google DeepMind on raw foundational capability — Tencent admits it.
- The 99.99% success and 495-step figures are Tencent's internal measurements; outside reproductions don't exist yet.
- Self-hosting needs serious metal: 8× H20-3e (or equivalent large-memory GPUs) recommended.
- vLLM and SGLang must be built from source with MTP enabled — upstream releases don't carry the patches yet.
- License is the custom Tencent Hy Community License Agreement, not Apache or MIT — read it before building a commercial product on top.
Tencent Cloud TokenHub pricing: ¥1.2 / 1M input tokens, ¥0.4 / 1M cached input, ¥4 / 1M output. A monthly Token Plan starts at ¥28/month.
What's next
Hy3 preview is, as the name says, a preview. Yao Shunyu calls it "the first step in rebuilding the Hunyuan large model" — the goal of this phase is to harvest community plus product feedback to ship the official Hy3 release. Tencent says it will keep scaling pre-training and RL to raise the "intelligence ceiling" and explore distinctive new capabilities.
Operationally, the model is rolling further into Tencent's product surface: WeChat Official Accounts, Peacekeeper Elite, Tencent News, and WeChat Reading are next, on top of the already-live Yuanbao, IMA, CodeBuddy, WorkBuddy, QQ, QQ Browser, Tencent Docs, and Tencent Cloud.
Nguồn: Tencent-Hunyuan/Hy3-preview on GitHub, Hugging Face model card, SCMP, Implicator.ai.

