
TL;DR
MOSS-TTS-Nano là model text-to-speech mã nguồn mở chỉ 100M tham số, vừa được team MOSI.AI + OpenMOSS (Fudan NLP Lab) release ngày 10/4/2026 dưới giấy phép Apache-2.0. Nó stream giọng nói 48kHz stereo realtime trên CPU 4-core — không cần GPU. Hỗ trợ 20 ngôn ngữ, voice cloning zero-shot từ 1 clip ngắn. Ngày 17/4/2026 team tung tiếp bản ONNX chạy được trên đúng 1 core MacBook Air M4, nhanh gấp 2× bản PyTorch.

What's new
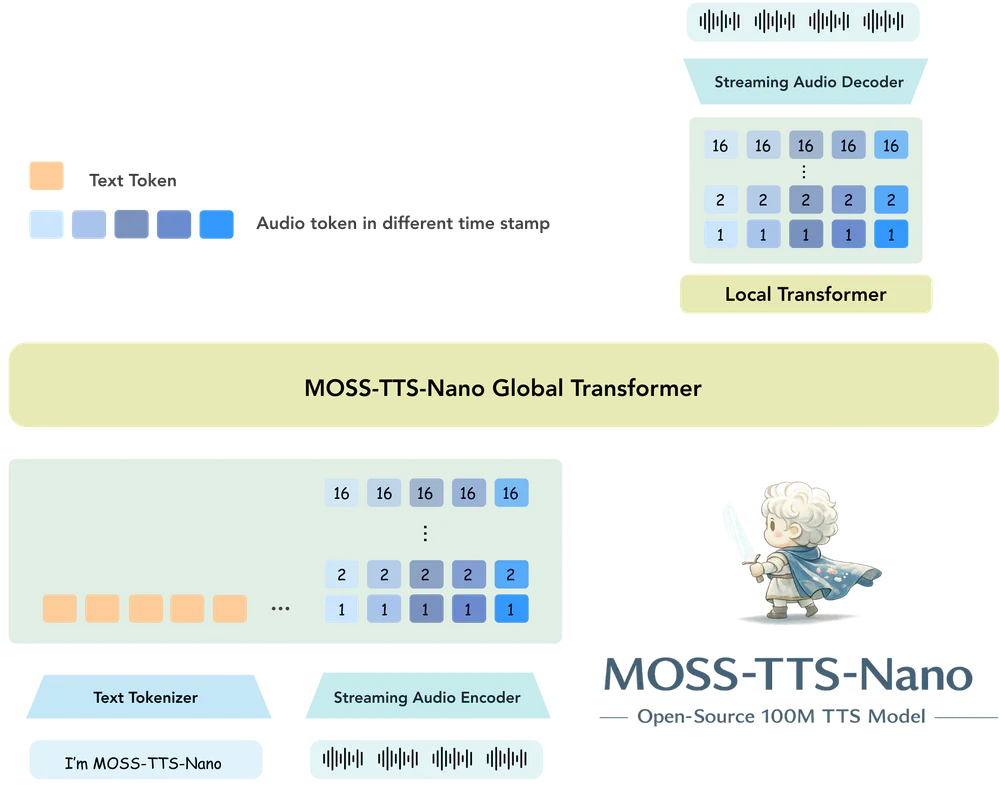
Hầu hết model TTS hiện đại (F5-TTS 0.3B, CosyVoice2 0.5B, XTTS…) vẫn cần GPU để đạt tốc độ realtime streaming. MOSS-TTS-Nano viết lại luật chơi: nhét toàn bộ pipeline Audio Tokenizer + LLM autoregressive xuống 100M params và chạy mượt trên CPU thường.
- Model chính: 0.1B params, pure autoregressive, Apache-2.0
- Tokenizer riêng: MOSS-Audio-Tokenizer-Nano ~20M params, CNN-free causal Transformer với sliding-window attention
- Audio: native 48 kHz, stereo 2-channel — hiếm thấy ở micro-TTS
- Voice cloning zero-shot: cần đúng 1 clip reference ngắn, không fine-tune
- Streaming: auto-chunking cho long-text, first-token latency thấp
- Triển khai:
python infer.py,python app.py(FastAPI web demo), CLImoss-tts-nano generate/moss-tts-nano serve
Why it matters
Trong landscape TTS đang phình size về billion-params, đi ngược xuống 100M mà vẫn giữ 48kHz stereo + 20 ngôn ngữ là một đánh cược kỹ thuật thú vị. Nó mở ra 3 hướng sản phẩm mà trước đây bị chặn bởi chi phí GPU:
- Browser-native TTS: chạy thẳng trong extension/web worker — không gọi cloud API
- On-device voice cho edge/IoT: synthesize offline trên server nhỏ hoặc thiết bị nhúng
- Indie dev prototyping:
moss-tts-nano servebật HTTP API trong 1 dòng lệnh, không cần thuê GPU
Và quan trọng: Apache-2.0 nghĩa là dùng thương mại thoải mái, không phí license, không điều khoản non-commercial.
Technical facts
| Property | Value |
|---|---|
| Tổng params | ~100M (0.1B) |
| Tokenizer | MOSS-Audio-Tokenizer-Nano, ~20M params |
| Kiến trúc tokenizer | CNN-free causal Transformer, 12 encoder + 12 decoder blocks, sliding-window attention |
| Sampling rate | 48 kHz native |
| Kênh | Stereo (2-channel) |
| Token stream | 12.5 Hz |
| Codebooks | 16 RVQ |
| Bitrate | 0.125 – 2 kbps variable |
| Số ngôn ngữ | 20 |
| License | Apache-2.0 |
| CPU yêu cầu | 4 core (ONNX: 1 core đủ trên MBA M4) |
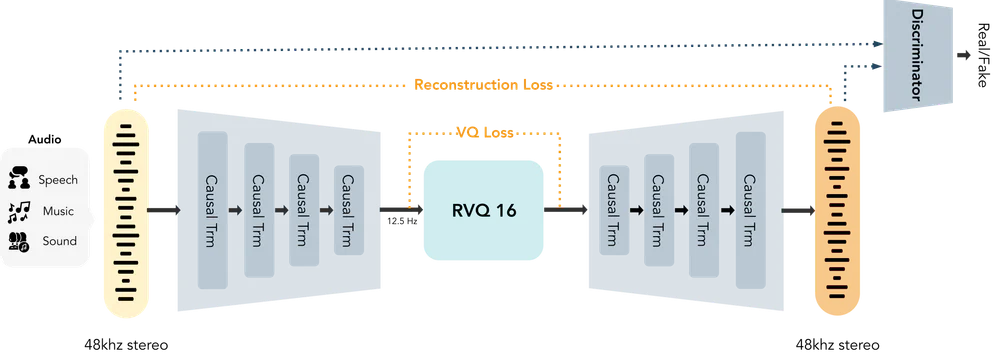
Audio tokenizer — quả tim của hiệu suất
Lý do Nano nhét được 48kHz stereo vào model nhỏ là tokenizer cực gọn. Nó nén audio 48kHz stereo thành token stream chỉ 12.5 frames/second qua 16 codebooks RVQ, đạt bitrate biến thiên 0.125–2 kbps mà vẫn tái tạo âm thanh high-fidelity. Nhờ token sequence siêu ngắn, autoregressive LLM 100M không bị nghẹt context khi sinh long-form speech.
Comparison
Đặt cạnh các open TTS khác:
| Model | Params | GPU-free? | 48kHz stereo? | Languages | License |
|---|---|---|---|---|---|
| MOSS-TTS-Nano | 0.1B | Có (4-core, ONNX 1-core) | Có | 20 | Apache-2.0 |
| Kokoro (~82M) | 0.08B | Có | 24kHz | ~9 | Apache-2.0 |
| F5-TTS | 0.3B | Không realtime | 24kHz | ~2 | MIT |
| CosyVoice2 | 0.5B | Không realtime | 24kHz | Multi | Apache-2.0 |
| XTTS v2 (Coqui) | ~0.5B | Cần GPU | 24kHz | 17 | CPML (non-commercial) |
| MOSS-TTS-Realtime (family) | — | Cần GPU | 48kHz | Multi | Apache-2.0 |
Niche của Nano là giao điểm cực hiếm: sub-100M + 48kHz stereo + 20 ngôn ngữ + CPU streaming + giấy phép thương mại. Nếu bạn cần đúng combo này, hiện không có đối thủ.
Use cases
- Browser reader (MOSS-TTS-Nano-Reader): team đã release app đọc trang web ngay trong browser. Bản update 17/4 chạy thẳng model trong extension qua ONNX Runtime — không cần local inference server.
- Edge / IoT device: TTS offline trên server nhỏ, Raspberry Pi, thiết bị nhúng.
- Voice assistant demo: indie dev build prototype không phải thuê GPU.
- Long-document narration: auto-chunking xử lý text dài, stream ra audio theo đoạn.
- Multilingual app: 1 model cover tiếng Việt chưa có (chưa support tiếng Việt — xem limitations), nhưng cover EN/JA/KO/ZH/ES/FR/DE/AR cùng lúc.
Limitations & pricing
Giá: Miễn phí 100%. Weights trên GitHub, Hugging Face (OpenMOSS-Team/MOSS-TTS-Nano-100M, MOSS-Audio-Tokenizer-Nano, và bản ONNX), ModelScope. Apache-2.0 cho phép thương mại hoá.
Những hạn chế thực tế theo independent testing (sonusahani):
- Voice cloning không ổn định cho non-English: clone Arabic thất bại, German không giống source voice, Spanish chỉ faint resemblance
- Một số preset voice mismatch giới tính (Chinese preset output sai gender)
- Latency dao động mạnh theo ngôn ngữ — German input dài mất ~30–40s trên CPU
- Chưa support tiếng Việt trong 20 ngôn ngữ chính thức
- Cross-language consistency chưa tới mức production cho cloning
Khuyến nghị: dùng cho preset voice + synthesis nhẹ + prototyping. Voice cloning production nên đợi bản tiếp theo hoặc dùng MOSS-TTS flagship (1.7B–8B) trên GPU.
What's next
Timeline release dày đặc trong tháng 4/2026:
- 10/4: Nano base release
- 13/4: Tích hợp vào MOSS-TTS Family repo
- 14/4: MOSS-TTS-Nano-Reader (browser app)
- 16/4: Finetuning code
- 17/4: ONNX CPU version — 2× nhanh hơn, chạy trên 1 core MBA M4; Reader update chạy thẳng trong browser extension
Team đã nhắc tới 2-bit quantization như hướng tiếp theo để tiết kiệm tài nguyên hơn nữa. Với nhịp ship 1 update/2 ngày, kỳ vọng bản kế sẽ vá cloning reliability và mở rộng ngôn ngữ — tiếng Việt rất có thể nằm trong pipeline.
Nguồn: GitHub OpenMOSS/MOSS-TTS-Nano, Hugging Face, Demo page, Communeify guide, Sonusahani review.