
- DeepSeek vừa mở mã nguồn V4-Pro (1.6T total / 49B active) và V4-Flash (284B / 13B), cả hai đều có context 1 triệu token.
- Output token V4-Pro chỉ $3.48/M — rẻ hơn GPT-5.5 8.6× và Claude Opus 4.7 21×.
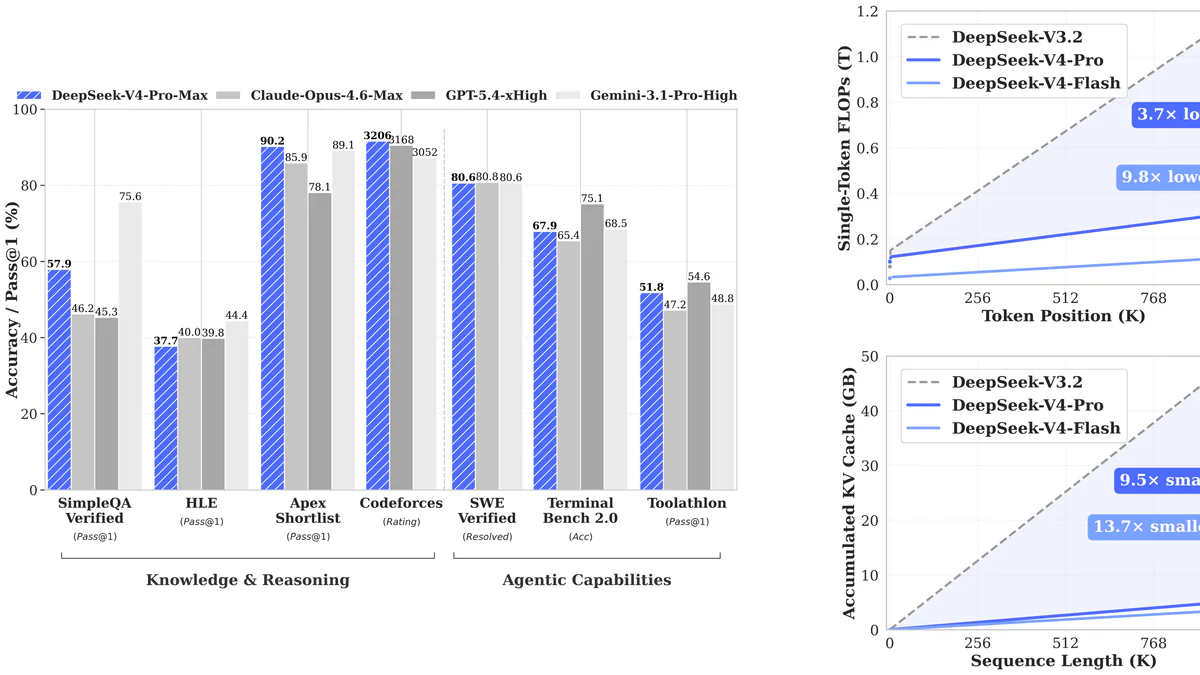
- Codeforces 3206, LiveCodeBench 93.5.
- Đã live trên API và chat.deepseek.com hôm nay.
TL;DR
Ngày 24/04/2026, DeepSeek công bố preview V4-Pro (1.6T total / 49B active params) và V4-Flash (284B / 13B), cả hai đều là Mixture-of-Experts với cửa sổ ngữ cảnh 1 triệu token và max output 384K. Trọng số mở trên Hugging Face, API live ngay trong ngày. Giá output V4-Pro $3.48/M token — rẻ hơn GPT-5.5 8.6 lần, rẻ hơn Claude Opus 4.7 21 lần. V4-Pro-Max chiếm SOTA mã nguồn mở trên LiveCodeBench (93.5), Codeforces rating 3206, vượt cả GPT-5.4 (3168) và Gemini 3.1 Pro (3052) ở đấu trường lập trình thi đấu.
Có gì mới
DeepSeek chọn đúng ngày OpenAI ship GPT-5.5 để công bố V4 — chia đôi news cycle. Đây không phải V3.2 phình to mà là kiến trúc khác hẳn, đường cong chi phí khác hẳn:
- Hai biến thể MoE:
deepseek-v4-pro1.6T/49B vàdeepseek-v4-flash284B/13B. Flash không phải Pro bị cắt — đây là MoE huấn luyện riêng từ đầu. - 1M token context native trên cả hai, max output 384K token.
- Open-weight trên Hugging Face — community đọc là Apache 2.0 (V3 là MIT, lên Apache 2.0 mở khoá patent protection cho doanh nghiệp).
- Dual mode: Thinking / Non-thinking, ba mức effort (high, max, non-think). Mặc định bật thinking ở mức high.
- API live ngay — base URL
https://api.deepseek.comhỗ trợ đồng thời protocol OpenAI ChatCompletions và Anthropic. Web app: V4-Pro = Expert Mode, V4-Flash = Instant Mode. - Alias cũ
deepseek-chatvàdeepseek-reasonersẽ retire ngày 24/07/2026 — hiện route về V4-Flash.
Vì sao đáng quan tâm
Cú đột phá thực sự của V4 nằm ở chi phí phục vụ context dài. Trước V4, chạy 1M-token window trên model open-weight là cơn ác mộng tài chính: KV cache phình to gấp nhiều lần bộ nhớ inference. V4 đập vỡ rào cản đó.
V4-Pro chỉ dùng 27% FLOPs và 10% KV cache của V3.2 ở context 1M token. Cụ thể: V4-Pro 3.7× lower FLOPs / 9.5× smaller KV cache; V4-Flash 9.8× lower FLOPs / 13.7× smaller KV cache.
Hệ quả thực tế: bạn có thể chạy mô hình reasoning tier Codeforces-3200 với 1M context trong production bằng ngân sách ngày xưa chỉ đủ trả cho một chat endpoint tầm trung. Đó là sự dịch chuyển thực sự của đường cong chi phí.
Technical facts
Ba thay đổi kiến trúc lớn so với V3.2:
- Hybrid long-context attention: kết hợp Compressed Sparse Attention (CSA) — nén KV cache theo chiều sequence rồi sparse-select top-k (Flash: rate=4, top-k=512; Pro: top-k=1024) — với Heavily Compressed Attention (HCA) ở compression rate 128 cho global memory path giá rẻ. Hai mechanism này xen kẽ qua các tầng.
- Manifold-Constrained Hyper-Connections (mHC) thay residual connection truyền thống. Expansion factor 4, 20 vòng Sinkhorn-Knopp, ràng buộc residual mapping vào doubly stochastic matrices để ổn định signal propagation.
- Muon optimizer dùng cho hầu hết module (AdamW giữ lại cho embedding, prediction head, RMSNorm).
Pre-train trên 32T+ token, mixed precision FP4 + FP8 (MoE expert weights ở FP4, các tham số khác FP8). Engineering bonus: fused MoE kernel, TileLang, FP4 quantization-aware training, batch-invariant deterministic kernels, 2-stage contextual parallelism, heterogeneous KV cache có tầng on-disk.
Engram Memory System — selective context retention: model tự xác định phần lịch sử nào còn relevant và giữ lại ở fidelity cao thay vì xử lý đồng đều. Theo các nguồn đánh giá, đây là production deployment đầu tiên của selective attention ở quy mô này.
So sánh với top frontier
Bảng head-to-head V4-Pro-Max vs các frontier model (số càng cao càng tốt, trừ Codeforces là rating Elo):
| Benchmark | V4-Pro-Max | GPT-5.4 xHigh | Opus 4.6 Max | Gemini 3.1 Pro |
|---|---|---|---|---|
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 |
| Codeforces (rating) | 3206 | 3168 | — | 3052 |
| Apex Shortlist | 90.2 | 78.1 | 85.9 | 89.1 |
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| GPQA Diamond | 90.1 | 93.0 | 91.3 | 94.3 |
| SWE-Verified | 80.6 | — | 80.8 | 80.6 |
| Terminal Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 |
| MRCR 1M (long-context recall) | 83.5 | — | 92.9 | 76.3 |
| Chinese-SimpleQA | 84.4 | 76.8 | 76.2 | 85.9 |
V4-Pro-Max dẫn đầu coding competitive (LiveCodeBench, Codeforces) và Apex Shortlist; bám sát closed frontier ở GPQA/HLE/SWE-Verified; thua Claude Opus 4.6 ở MRCR 1M (long-context recall thực sự) và thua Gemini 3.1 Pro ở world knowledge (SimpleQA-Verified 57.9 vs 75.6).
V4-Flash-Max bám rất sát Pro: MMLU-Pro 86.2 (Pro 87.5), LiveCodeBench 91.6 (Pro 93.5), SWE-Verified 79.0 (Pro 80.6). Khoảng cách thường 1–3 điểm — nhưng Flash rẻ hơn Pro 12 lần ở output token.
Giá API & cost
| Model | Input cache miss | Input cache hit | Output |
|---|---|---|---|
| deepseek-v4-flash | $0.14 / M | $0.028 / M | $0.28 / M |
| deepseek-v4-pro | $1.74 / M | $0.145 / M | $3.48 / M |
| GPT-5.5 | $5.00 / M | $0.50 / M | $30.00 / M |
| Claude Opus 4.7 | $5.00 / M | up to 90% cache discount | $25.00 / M |
Đối chiếu nhanh: V4-Pro output rẻ hơn GPT-5.5 8.6×, rẻ hơn Opus 4.7 21×. V4-Flash output ở $0.28/M coi như free. Context caching bật mặc định và tính phí minh bạch qua cache-hit/miss token — workload có shared system prompt dài hoặc document prefix lặp lại sẽ được hưởng lợi cực lớn.
Use cases nên dùng cái nào
- V4-Pro: agentic coding (autonomous bug fix, code review, PR generation — SWE-Verified 80.6), competitive programming, hard math (HMMT 95.2, IMOAnswerBench 89.8), workload tiếng Trung (Chinese-SimpleQA 84.4 — best open-weight).
- V4-Flash: bulk code processing, CI/CD pipeline, codebase indexing, document Q&A khối lượng lớn, summarization, data extraction. Bất kỳ workload chạy trong ngân sách $1–2 / triệu output token.
- Cả hai khai thác 1M context: review architecture toàn repository, migration planning cross-file, legal discovery, tài liệu enterprise, năm email lịch sử, hours-long audio transcript trong một pass.
- Local deployment: V4-Flash chạy được trên 2× RTX 4090 (~$3,200) hoặc 1× RTX 5090 với 4-bit quantization. V4-Pro vẫn cần multi-GPU nghiêm túc.
Limitations & cảnh báo
- Long-context recall ở rìa 1M token: degrade dần qua mốc ~128K, MRCR 1M 83.5 vs Opus 4.6's 92.9. V4 thắng về efficiency chứ không phải retrieval quality tuyệt đối.
- World knowledge: Gemini 3.1 Pro vẫn dẫn đầu SimpleQA-Verified (75.6 vs 57.9).
- Agentic tool-use phức tạp: GPT-5.5 dẫn Terminal Bench 2.0 (82.7 vs 67.9).
- Multimodal hẹp hơn GPT-5.4: chưa có native computer-use, video/audio hạn chế.
- Production hardening: vừa launch — chưa stress-test ở scale, chưa có chứng chỉ SOC 2 / GDPR enterprise.
- "Open-weight" không phải "open-source": training data, pipeline, serving stack vẫn đóng.
Bước tiếp theo
V4 đang ở phase preview, ngụ ý sẽ có vòng post-training stabilization trước GA. Aliases legacy deepseek-chat và deepseek-reasoner retire ngày 24/07/2026 — team đang dùng API cũ nên migrate sang deepseek-v4-flash hoặc deepseek-v4-pro trước thời điểm đó. Aggregator bên thứ ba (Ofox, EvoLink) đã hỗ trợ day-one.
Thử ngay tại chat.deepseek.com qua Expert Mode (Pro) hoặc Instant Mode (Flash). Trọng số: DeepSeek-V4 collection trên Hugging Face. Tech report: DeepSeek_V4.pdf.
Nguồn: @deepseek_ai (X), Hugging Face model card, Ofox release guide, Kingy AI deep-dive, OfficeChai benchmarks.

