
- Một chiếc RTX 4090 24GB vừa chạy được 256K context với Qwen3.6-27B nhờ 48/64 lớp là Gated DeltaNet linear attention.
- Model 16.8GB + KV 4.6GB = 22GB, sinh 37 tok/s, còn hạ 397B MoE trên nhiều benchmark coding.
TL;DR
Ngày 22/4/2026, Alibaba Qwen Team tung Qwen3.6-27B — model dense 27B open-weight, Apache 2.0, kiến trúc hybrid Gated DeltaNet + Gated Attention. 48 trên 64 sublayer dùng linear attention, KV cache co lại còn ~1/4 so với Dense 27B thông thường. Kết quả: cộng đồng xác nhận chạy được 256K context trên một RTX 4090 24GB với quant Q4_K_M (model 16.8GB + KV 4.6GB = 22GB), generation 37 tok/s. Benchmark thì ngang Claude 4.5 Opus ở Terminal-Bench 2.0 (59.3) và beat luôn Qwen3.5-397B MoE trên SWE-bench Verified (77.2 vs 76.2).

What's new
Qwen3.6-27B là model dense đầu tiên trong họ Qwen3.6 (trước đó chỉ có bản MoE 35B-A3B ra ngày 16/4 và bản proprietary Max-Preview). Hai điểm đáng chú ý:
- Hybrid layout. 64 layer với pattern lặp 16 block, mỗi block là
3 × (Gated DeltaNet → FFN) + 1 × (Gated Attention → FFN). Ba phần tư sublayer là linear attention O(n), chỉ một phần tư là full attention. - Thinking Preservation. Tính năng mới — giữ chain-of-thought của các turn trước trong lịch sử hội thoại, bật bằng
preserve_thinking: Truetrong chat template. Agent multi-turn khỏi phải re-derive reasoning mỗi lần, token tiêu hao giảm, KV cache hiệu quả hơn.
Why it matters
Dense 27B kiểu truyền thống thường đụng trần 64K–128K context trên 24GB VRAM vì KV cache phình theo độ dài sequence. Qwen3.6-27B ép được 256K lên RTX 4090 vì Gated DeltaNet là linear attention: mỗi token chỉ cần state cố định thay vì ma trận attention O(n²). Riêng 16 lớp Gated Attention còn xài tỉ lệ GQA cực lệch — 24 Q head nhưng chỉ 4 KV head, head dim 256 — giảm thêm một bậc nữa dung lượng KV cache.
Hệ quả thực tế: agent coding chạy local có thể nuốt cả repo lớn, giữ 1,000+ vòng tool call, không phải cắt context. Đây là lần đầu một model open-weight trong tầm 18–24GB VRAM làm được điều mà trước đây cần API đám mây.
Technical facts
| Property | Giá trị |
|---|---|
| Params (dense, all active) | 27B |
| Layers / hidden dim / FFN dim | 64 / 5120 / 17,408 |
| Gated DeltaNet heads | 48 V + 16 QK, head dim 128 |
| Gated Attention heads | 24 Q + 4 KV, head dim 256, RoPE dim 64 |
| Context native / extended | 262,144 / 1,010,000 (YaRN) |
| Q4_K_M GGUF size | 16.8 GB |
| BF16 full size | 55.6 GB |
| RAM/VRAM @ Q4_K_M | ~18 GB |
| @luta_ai (RTX 4090, 256K ctx) | 16.8 GB model + 4.6 GB KV = 22 GB, 37 tok/s |
| Simon Willison (llama-server) | ~25 tok/s gen, 54 tok/s prompt |
| License / release date | Apache 2.0 / 22-04-2026 |
Comparison
Qwen team công bố ma trận benchmark so với Qwen3.5-27B (predecessor), Qwen3.5-397B-A17B (MoE 14.8× to hơn), Gemma4-31B, và Claude 4.5 Opus:
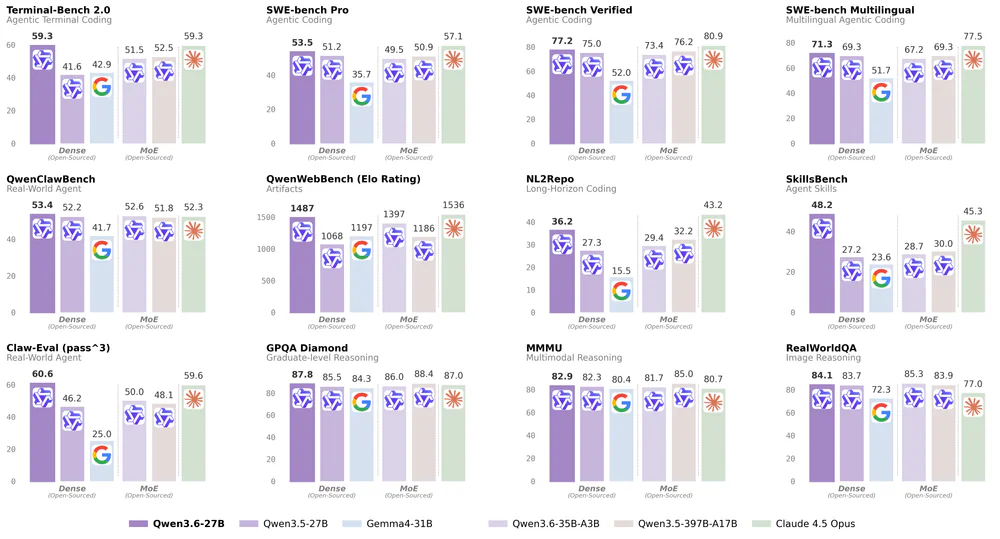
| Benchmark | Qwen3.5-27B | Qwen3.5-397B MoE | Claude 4.5 Opus | Qwen3.6-27B |
|---|---|---|---|---|
| SWE-bench Verified | 75.0 | 76.2 | 80.9 | 77.2 |
| SWE-bench Pro | 51.2 | 50.9 | 57.1 | 53.5 |
| Terminal-Bench 2.0 | 41.6 | 52.5 | 59.3 | 59.3 |
| SkillsBench | 27.2 | 30.0 | 45.3 | 48.2 |
| QwenWebBench | 1068 | 1186 | 1536 | 1487 |
| GPQA Diamond | 85.5 | — | — | 87.8 |
Hai điểm đáng chú ý: (1) 27B dense vượt 397B MoE trên SWE-bench Pro, Terminal-Bench 2.0 và SkillsBench — tức 55.6GB thắng 807GB file size; (2) ngang Claude 4.5 Opus trên Terminal-Bench 2.0 và vượt trên SkillsBench (48.2 vs 45.3). Caveat: benchmark dùng scaffold nội bộ của Qwen, verification độc lập vẫn đang emerge.
Use cases
- Agent coding local. Repository-level reasoning, multi-file edit, frontend workflows — chạy offline trên 4090 hoặc Mac 24GB unified. Tích hợp Claude Code / OpenCode / Qwen Code qua OpenAI-compatible endpoint ở
localhost:8080. - Long-context RAG. 262K native đủ nhét nguyên codebase hoặc sách dài; YaRN lên 1M cho tác vụ long-doc thực sự.
- Compliance-sensitive dev. Apache 2.0, self-host, không cần gửi code proprietary lên API ngoài.
- Multimodal agent. Vision encoder native (image/video); nhưng nếu dùng kèm mmproj thì nên hạ context về ~192K để an toàn — @luta_ai xác nhận ảnh chạy ngon ở 128K.
Limitations & pricing
- Miễn phí — Apache 2.0 trên HF Hub / ModelScope. API: Qwen Studio (web free), Alibaba Cloud Model Studio (DashScope), OpenRouter.
- Min context 128K. Qwen khuyến cáo giữ ≥128K token để không suy giảm thinking coherence.
- Ollama chưa chạy được GGUF Qwen3.6 vì cần file mmproj vision riêng. Dùng
llama.cpphoặc Unsloth Studio. - CUDA 13.2 bug — output gibberish. Dùng CUDA cũ hơn cho đến khi NVIDIA fix.
- Quant sâu phá tool calling. JSON tool grammar brittle; nếu VRAM chật thì default FP8 checkpoint thay vì GGUF thấp bit.
- YaRN trên text ngắn — scaling factor static, để bật YaRN cho short prompt sẽ hại perf. Chỉ bật khi thật sự cần long-doc.
What's next
Roadmap Qwen chuyển hướng rõ: thay vì đua benchmark, team prioritize "stability & real-world utility" theo feedback cộng đồng. Cả FP8 variant, GGUF Unsloth Dynamic 2.0, và support SGLang/vLLM/KTransformers đã có day-zero. Câu hỏi còn mở: (1) khi nào có verification độc lập ngoài scaffold nội bộ cho các con số SWE-bench; (2) mô hình dense nhỏ hơn (9B/4B) của Qwen3.6 liệu có giữ được trick hybrid này không; (3) Thinking Preservation có trở thành chuẩn ngành trong 6 tháng tới như Simon Willison dự đoán.
Nếu bạn có RTX 4090 hoặc Mac 24GB unified, đây là model local coding mạnh nhất ở tier này tính đến 23/4/2026.
Nguồn: Qwen blog, HF model card, Simon Willison, Unsloth docs, @luta_ai.

