
TL;DR
Ngày 24/4/2026, DeepSeek công bố V4-Pro (1.6T params, 49B active) và V4-Flash (284B params, 13B active), đều open weights dưới MIT license. Ngay sau đó, NVIDIA đưa V4-Pro lên build.nvidia.com chạy free trên GPU Blackwell. SWE-bench Verified 80.6% (chỉ kém Claude Opus 4.6 đúng 0.2 điểm), giá output chỉ $3.48/1M token — rẻ hơn Claude 7 lần, rẻ hơn GPT-5.4 hơn 4 lần.
What's new
Đây là lần đầu một mô hình open-source vượt ngưỡng 1.6 nghìn tỷ tham số, đưa DeepSeek-V4-Pro thành mô hình mở lớn nhất thế giới tính đến thời điểm phát hành. Điểm đáng chú ý:
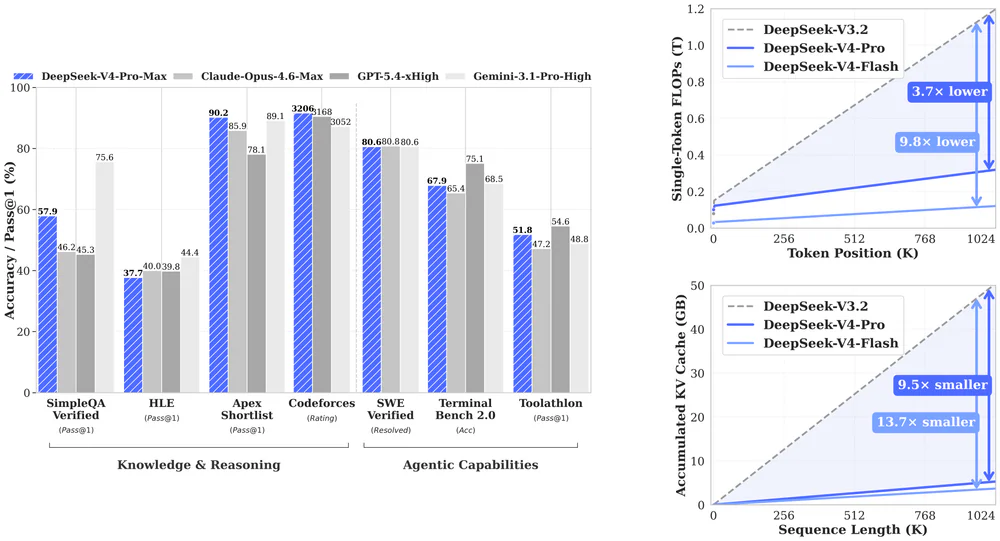
- Hybrid Attention — kết hợp Compressed Sparse Attention (CSA) và Heavily Compressed Attention (HCA). KV cache giảm còn 10% so với V3.2 ở context 1M token; FLOPs mỗi token inference chỉ còn 27%.
- Manifold-Constrained Hyper-Connections (mHC) — ràng buộc khuếch đại tín hiệu từ ~3,000× xuống 1.6×, giúp training ổn định ở quy mô 1.6T params.
- Muon optimizer thay AdamW — hội tụ nhanh hơn, ổn định hơn qua 32–33T token pre-training.
- Ba chế độ reasoning: Non-think, Think High, Think Max.
- Phát hành dưới MIT license — dùng thương mại không ràng buộc.
Why it matters
DeepSeek tiếp tục chứng minh luận điểm từ thời V3: frontier-level performance không cần frontier-level budget. V4 được huấn luyện trên ~16,000 GPU Hopper-era với tổng chi phí compute báo cáo ~$5.6 triệu — gấp đôi hiệu suất train so với V3.
Với indie hacker và team nhỏ, điều này nghĩa là: bạn có quyền truy cập miễn phí một mô hình ngang ngửa GPT-5.4 và Claude Opus 4.6 ở hầu hết task coding/agent, không khóa vendor, không giới hạn rate như API thương mại — chỉ cần login build.nvidia.com.
Technical facts
| Thuộc tính | V4-Pro | V4-Flash |
|---|---|---|
| Tổng params | 1.6T | 284B |
| Active params/token | 49B | 13B |
| Context window | 1M tokens | 1M tokens |
| Pre-training tokens | 33T | 32T |
| Precision | FP4 + FP8 mixed | FP4 + FP8 mixed |
| License | MIT | MIT |
Trọng số (Safetensors) của V4-Pro ~862B, tensor types gồm BF16, F32, F8_E8M0, F8_E4M3, I8. Với deploy local, DeepSeek khuyến nghị temperature=1.0, top_p=1.0, context window ít nhất 384K cho Think Max.
Comparison
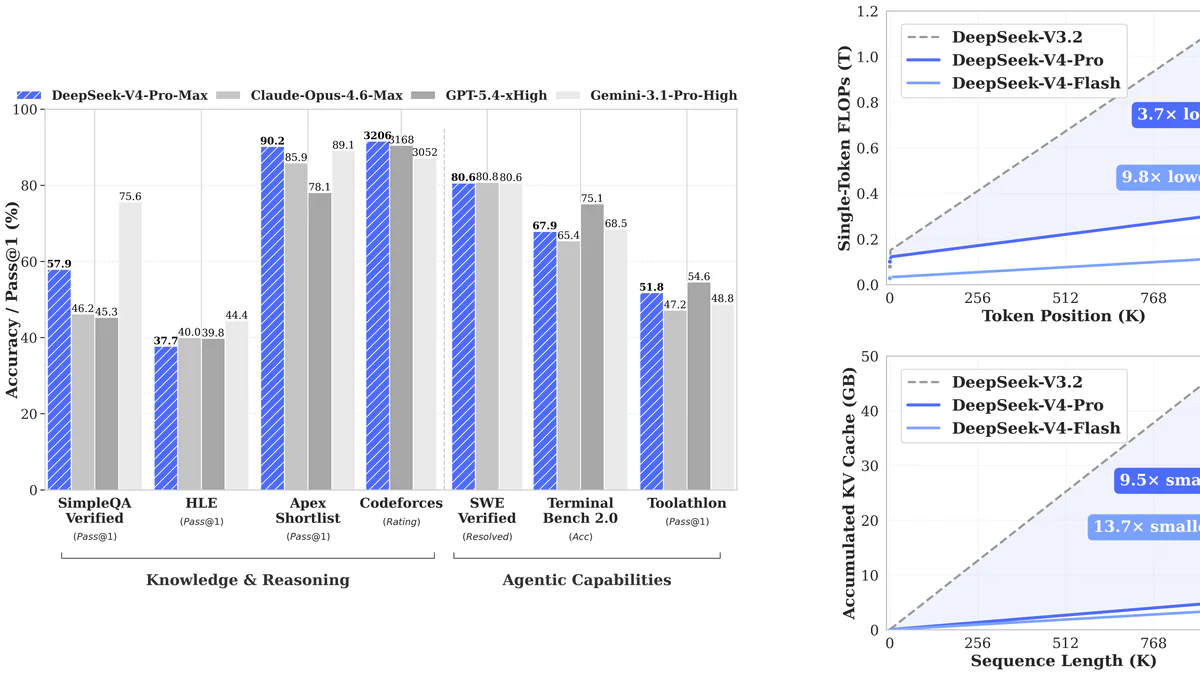
V4-Pro so với các frontier model khác (cao hơn = tốt hơn):
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini-3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 |
| Codeforces (rating) | 3206 | 3168 | — | 3052 |
| SWE-bench Verified | 80.6 | — | 80.8 | 80.6 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
| HLE | 37.7 | 39.8 | 40.0 | 44.4 |
| Terminal-Bench 2.0 | 67.9 | — | — | — |
V4-Pro dẫn đầu LiveCodeBench và Codeforces, bám sát Claude Opus ở SWE-bench. Trail ở HLE (reasoning chuyên gia đa lĩnh vực) và SimpleQA (factual recall — 57.9 vs Gemini 75.6).
Use cases
- Coding agent & IDE copilot — LiveCodeBench 93.5 và Codeforces 3206 là top class; Terminal-Bench 2.0 67.9 cho autonomous shell agent.
- Long-context analysis — 1M token với KV cache hiệu quả cho phép nhai nguyên repo hoặc bộ tài liệu hàng trăm trang trong một lần gọi.
- Production cost-sensitive — với $3.48/M output, app high-volume có thể chạy reasoning model cao cấp mà không đốt budget như Claude Opus ($25/M).
- Enterprise self-host — MIT license, FP4/FP8 chạy được trên H100/H200/Blackwell, không lock vào provider.
- Task đơn giản & volume lớn — chuyển xuống V4-Flash ($0.28/M output, rẻ hơn Claude Opus ~89 lần) với SWE-bench vẫn 79.0.
Limitations & pricing
Giá chính thức (per 1M tokens):
- V4-Pro: $0.145 input cache-hit · $1.74 cache-miss · $3.48 output
- V4-Flash: $0.028 · $0.14 · $0.28 output
- So sánh: GPT-5.4 $2.50 / $15 · Claude Opus 4.6 $5 / $25
Giới hạn cần cân nhắc:
- Factual recall yếu hơn đáng kể (SimpleQA 57.9 vs Gemini 75.6) — task Q&A fact nên ghép RAG.
- HLE 37.7 thấp hơn cả ba đối thủ — reasoning chuyên sâu đa lĩnh vực chưa ngang tầm.
- Hardware đòi hỏi hỗ trợ FP4/FP8 để chạy hiệu quả ở scale đầy đủ.
- Căng thẳng địa chính trị: quan chức Mỹ từng cáo buộc DeepSeek dùng Blackwell bị cấm để train; Huawei Ascend 950 được công bố hỗ trợ đầy đủ V4 — có thể ảnh hưởng lựa chọn enterprise ở một số thị trường.
What's next
V4 hiện là bản preview; bản final và các biến thể (nghe đồn V4-Pro-Max) sẽ theo sau trong vài tuần tới. Với NVIDIA chủ động host free trên NIM và Huawei hậu thuẫn phần cứng phía Trung Quốc, V4 có thể trở thành baseline mặc định cho mô hình mở trong nửa cuối 2026 — tương tự vai trò của Llama 3 năm ngoái.
Thử ngay miễn phí tại build.nvidia.com/deepseek-ai/deepseek-v4-pro. Tải weights tại Hugging Face.
Nguồn: NVIDIA NIM, Hugging Face, OfficeChai, CNBC.