
- Bằng cách quy mọi tác vụ dense vision về một bài toán duy nhất — sinh ảnh RGB — nhóm Google DeepMind fine-tune Nano Banana Pro thành Vision Banana, một mô hình đa nhiệm đạt SOTA trên depth, normals và segmentation, vượt mặt cả SAM 3 và Depth Anything mà vẫn giữ nguyên khả năng tạo ảnh.
TL;DR
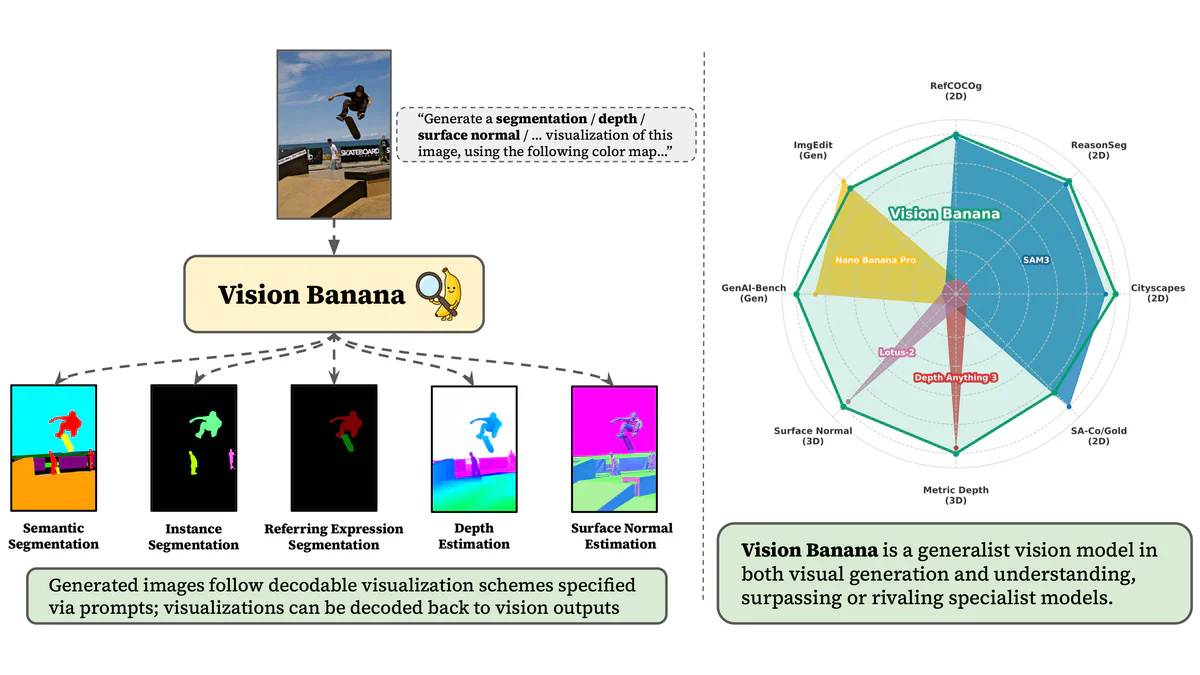
Google DeepMind vừa công bố Vision Banana — một mô hình thị giác đa nhiệm được tạo ra bằng cách instruction-tuning Nano Banana Pro (Gemini 3 Pro Image). Ý tưởng đơn giản đến mức gây sốc: thay vì xây mỗi tác vụ một head riêng, nhóm tác giả parameterize toàn bộ output (depth, normals, segmentation) thành ảnh RGB và để generator tự học. Kết quả: một model duy nhất vượt SAM 3 trên Cityscapes (+14.3 mIoU), vượt UniK3D / Depth Anything trên metric depth, mà không hề mất khả năng sinh ảnh của model gốc.
Có gì mới
Bài báo Image Generators are Generalist Vision Learners (arXiv 2604.20329, post 22/04/2026) đưa ra một quan điểm khá khiêu khích: generative pretraining đối với vision đóng vai trò tương đương như next-token pretraining đối với LLM. Một frontier image generator đã "hiểu" hình học, ngữ nghĩa, vật liệu, ánh sáng — chỉ cần dạy nó cách vẽ ra câu trả lời.
Vision Banana xử lý 5 tác vụ trong cùng một mô hình:
- Semantic segmentation
- Instance segmentation
- Referring expression segmentation
- Monocular metric depth estimation
- Surface normal estimation
Mọi đầu ra đều được encode thành ảnh RGB theo color-map quy ước trong prompt — segmentation map, depth map, normal map. Model nhìn ảnh, đọc prompt, "vẽ" câu trả lời ra dưới dạng ảnh.
Vì sao quan trọng
Suốt 5 năm qua, computer vision đi theo hướng specialist: một backbone (DINOv2, SAM, Depth Anything) cho mỗi họ tác vụ, mỗi cái có decoder, loss, dataset riêng. Vision Banana cho thấy không cần kiến trúc đặc thù — một image generator đủ mạnh có thể nuốt trọn cả pipeline. Điều này gợi ý một đổi ngôi: trong tương lai, perception backbone tốt nhất có thể chính là image generator tốt nhất.
Với robotics, AR/VR và 3D reconstruction, hệ quả thực tế là: bạn có thể bỏ ba mô hình rời rạc (depth + normals + seg) để chạy một model duy nhất, đồng thời được luôn khả năng generative để edit, inpaint, hay round-trip ảnh.
Số liệu kỹ thuật
Vision Banana được instruction-tune lightweight trên hỗn hợp data gốc của NBP + dataset của các vision task. Khả năng sinh ảnh nền được giữ nguyên (không catastrophic forgetting).
| Benchmark | Vision Banana | Specialist SOTA |
|---|---|---|
| Cityscapes semantic seg (mIoU) | 0.842 | SAM 3 — 0.699 |
| SA-Co/Gold instance seg (pmF1) | 0.552 | DINO-X — 0.540 |
| RefCOCOg referring seg (cIoU) | 0.794 | — |
| ReasonSeg (gIoU) | 0.793 | — |
| Metric depth (δ₁) | 0.882 | UniK3D — 0.823 |
| Surface normals (mean angular err) | 15.549° | — |

So sánh với specialist
Điều ấn tượng không nằm ở việc hơn 1–2 điểm — mà ở biên độ và độ rộng. Trên Cityscapes, Vision Banana cách SAM 3 đến 14.3 điểm mIoU, tức không chỉ "rivaling" mà đè bẹp specialist mạnh nhất của chính Meta. Trên metric depth, δ₁ 0.882 vs 0.823 của UniK3D — bước nhảy mà cộng đồng depth thường mất 1–2 năm để đạt được.
So với hướng "generative perception" trước đây (Marigold, RGB↔X), Vision Banana là mô hình đầu tiên chứng minh một frontier generator có thể làm tất cả dense vision tasks cùng lúc, mà không phải hi sinh chất lượng sinh ảnh.

Use cases
- Robotics & AR/VR: một backbone duy nhất cho perception stack, giảm chi phí infra và độ trễ.
- 3D reconstruction: depth + normals từ một forward pass — đủ để dựng mesh hoặc Gaussian Splat sơ bộ.
- Photo editing pipeline: cùng model tạo ảnh có thể trích xuất hình học/ngữ nghĩa rồi sinh lại ảnh đã edit — vòng round-trip mà trước đây cần 3–4 model rời.
- Open-vocabulary perception: tận dụng text-conditioning của generator để làm referring segmentation và reasoning segmentation zero-shot.

Hạn chế & khả dụng
Vision Banana chưa public — đây là kết quả nghiên cứu, weights/API chưa mở. Nano Banana Pro nền tảng đã có trên Gemini API và app Gemini từ tháng 11/2025, nhưng phiên bản fine-tuned cho perception thì chỉ tồn tại trong nội bộ DeepMind.
Một eval độc lập trước đó (arXiv 2512.15110) chỉ ra NBP có xu hướng "hallucinate plausible high-frequency details" — đẹp về thị giác nhưng có thể lệch trên các metric pixel-reference. Việc Vision Banana vẫn thắng trên δ₁ và mIoU cho thấy chiến thắng này không đến từ cherry-picking. Chi phí inference cũng cao hơn specialist nhỏ (mỗi tác vụ phải sinh nguyên một ảnh RGB), nhưng paper chưa công bố latency cụ thể.
Tiếp theo là gì
Nhóm tác giả (25 người, gồm Jonathan T. Barron, Saining Xie, Kaiming He, Thomas Funkhouser, Jean-Baptiste Alayrac) gợi ý sẽ scale công thức này lên video generator và 3D generator. Cộng đồng open-source nhiều khả năng sẽ thử replicate trên Flux, SD3 hoặc Qwen-Image — nếu thành công, đây sẽ là phát súng đầu tiên cho một paradigm mới: generator chính là perception backbone.
Nguồn: vision-banana.github.io, arXiv 2604.20329, @jon_barron.


