
TL;DR

Ollama vừa bật công tắc open-source cho Qwen 3.6 — dòng agentic coding frontier của Alibaba Qwen series 3.6 giờ chạy local được, miễn phí vô thời hạn. Không phải distill, không phải cut-down — là MoE 35B-A3B (35B total / 3B active) mang full stack post-training 3.6: Agent RL long-horizon, multi-turn tool use, thinking preservation. Điểm đáng chú ý nhất không nằm ở benchmark mà ở workflow: một lệnh ollama launch claude --model qwen3.6 là Claude Code CLI chuyển hoàn toàn sang model local. Tương tự với OpenClaw — MIT-license AI coding assistant bridge Telegram/Slack/Discord — cũng chỉ cần ollama launch openclaw --model qwen3.6. Zero API cost, zero data leaving your box.
What's new
Tweet từ @ollama ngắn gọn: "Qwen 3.6 is here, and open-source! Run it locally with improved agentic coding capabilities." Kèm ba command chính:
ollama launch claude --model qwen3.6— khởi Claude Code với backend localollama launch openclaw --model qwen3.6— khởi OpenClaw bridge agentollama run qwen3.6— chạy standalone (REPL)
Background tối thiểu để hiểu tại sao command này work: từ Ollama v0.14 (tháng 1/2026), runtime đã mở Anthropic-compatible API layer — Claude Code tưởng đang gọi Anthropic Messages API nhưng thực chất trỏ về localhost:11434. Không proxy, không sửa config tay. OpenClaw (MIT license) cũng dùng native /api/chat của Ollama cho streaming + tool-call đồng thời.
8 variants: từ 22GB đến 71GB
Ollama library publish 8 format, cover được từ laptop consumer GPU cho tới workstation multi-GPU:
| Format | Size | Target hardware |
|---|---|---|
| nvfp4 | 22 GB | NVIDIA FP4 (H100 / Blackwell) — fastest |
| q4_K_M | 24 GB | RTX 4090 / 3090 / A5000 (consumer) |
| q8_0 | 39 GB | A100 40GB / 2× RTX 4090 |
| bf16 | 71 GB | 2× A100 80GB / H100 — research full-precision |
Mọi variant share: 256K context native, multimodal text + images, license Apache 2.0. Kiến trúc kế thừa Qwen 3.5-35B-A3B: 256 experts, 8 routed + 1 shared per token, hybrid Gated DeltaNet + Gated Attention, 201 languages.
Why it matters: indie Claude Code experience
Setup hoàn chỉnh cho indie dev chạy coding agent thuần local giờ rút về 3 dòng:
ollama pull qwen3.6:q4_K_M
ollama launch claude --model qwen3.6
claude # Claude Code CLI tự connect localhostKhông phải trả tiền API, không có rate-limit, code không rời máy. Với developer ở thị trường bị Anthropic API restrict (một số region) hoặc team không muốn gửi repo proprietary ra cloud, đây là option đầu tiên gần như ngang tier flagship closed-source. Chữ "gần như" quan trọng — open-weight 35B-A3B không bằng Qwen 3.6-Plus (flagship API) hoặc Claude Opus 4.5/4.6, nhưng gap đã đủ hẹp để production workflow thực sự chạy được.
Technical facts: Qwen 3.6-Plus benchmarks (upper bound)
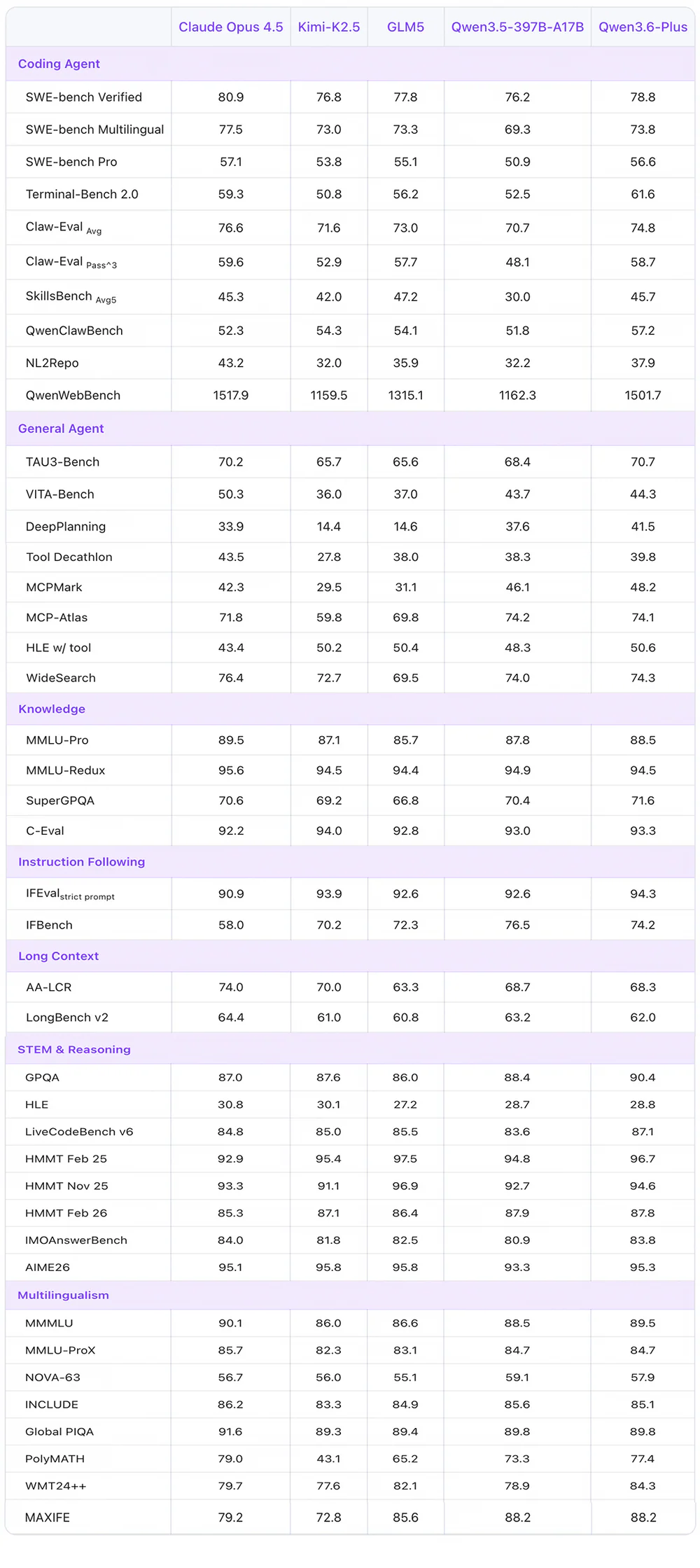
Open-weight 35B-A3B sẽ thấp hơn Plus đôi chút, nhưng số của Plus là trần capability cho biết dòng 3.6 đang ở đâu. Theo MindStudio review và Digital Applied benchmark:
| Benchmark | Qwen 3.6 Plus | Claude 4.5 Opus | GLM-5 | Kimi K2.5 | Qwen 3.5 |
|---|---|---|---|---|---|
| SWE-bench Verified | 78.8 | 80.9 | 77.8 | — | — |
| Terminal-Bench 2.0 | 61.6 | 59.3 | 56.2 | 50.8 | 52.5 |
Terminal-Bench 2.0 là điểm đáng chú ý nhất: Qwen 3.6 Plus thắng cả Claude Opus 4.5 ở agentic terminal coding (sửa bug, chạy CLI, multi-step tool use). SWE-bench Verified chỉ kém Opus 2.1 điểm — khoảng cách hẹp nhất lịch sử Qwen vs Claude tier flagship.
Comparison: vs tiền nhiệm + vs dense mid-tier
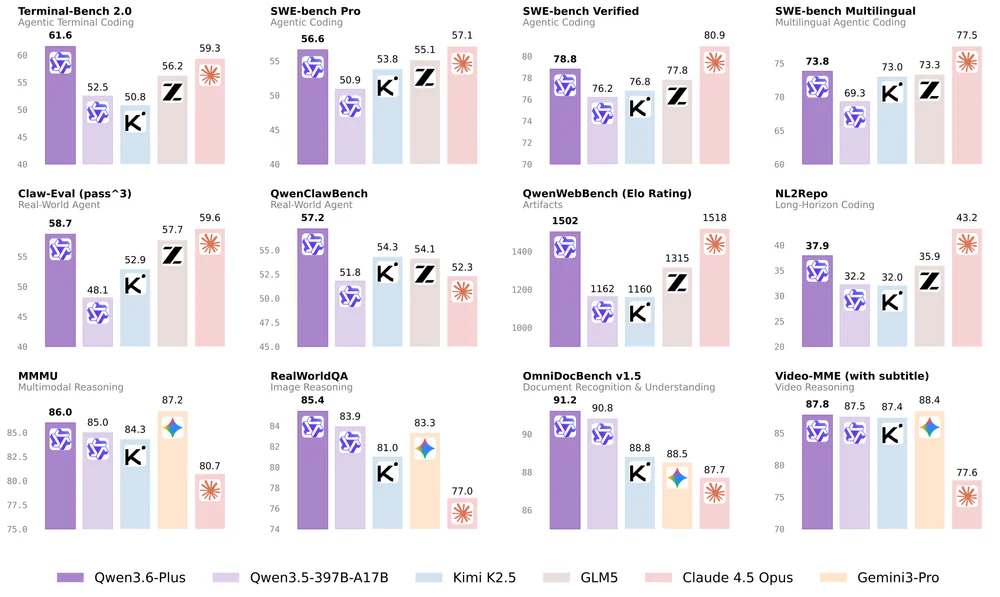
Vs Qwen 3.5-35B-A3B (cùng kiến trúc, tháng 2/2026):
- Bước nhảy không ở kiến trúc mà ở post-training stack 3.6: Agent RL long-horizon task, multi-turn tool use, data-mix coding/frontend/repo-level nâng cấp
- Giảm overthinking rõ rệt, tool-call reliability cao hơn — inherit pattern
preserve_thinkingcủa 3.6-Plus - "Dramatically surpasses" trên agentic coding theo mô tả chính thức
Vs Qwen 3.5-27B dense:
- 3B active vs 27B active → rẻ ~9× compute mỗi token
- Throughput consumer GPU: A3B ~60–100+ tok/s, dense 27B ~15–25 tok/s
- Vượt 27B dense trên several key coding benchmark — lần đầu MoE nhỏ-active open-weight beat dense mid-tier trên coding
Use cases: ai nên switch ngay
- Indie dev / solo builder: chạy Claude Code với model local, không tốn API fee. Workflow như trên: 3 lệnh là xong
- Team privacy-critical (healthcare, legal, fintech): OpenClaw + Ollama + Qwen 3.6 = full MIT/Apache stack, code không rời network. OpenClaw bridge Slack/Telegram/Discord/iMessage → nhắn tin trong Slack, bot reply bằng model local
- Agentic product builder: tool-use reliability đã first-class — build code-review bot, AI pair programmer, repo-level refactor agent
- Research / fine-tuning: Apache 2.0 cho phép distill, domain-adapt (legal code, medical software, trading systems) — trước đây phải đợi Llama hoặc Qwen 3.5
- Frontend-heavy projects: Qwen series ưu thế ở web design + SVG + data viz; 3.6 nâng cấp frontend workflow cụ thể
Limitations & pricing
- Hardware floor: ~22GB VRAM cho nvfp4, 24GB cho q4_K_M. RTX 4090 / 3090 / A5000 là entry tier. Full bf16 71GB cần 2×A100 80GB hoặc H100
- Context 1M qua YaRN: tốn RAM/VRAM đáng kể — native 256K là đủ 99% use case repo-level
- Không phải flagship: vẫn thua Qwen 3.6-Plus, Claude Opus 4.5/4.6, GPT-5.4 ở task phức tạp nhất. Best open-weight ≠ best overall
- Multimodal: có text + images nhưng không bằng Plus ở chart/doc OCR phức tạp
- Self-host cost: free (Apache 2.0). Chỉ tốn điện + GPU đã có sẵn. Commercial-friendly license
What's next
Pattern Qwen 3.x cho thấy sau tier mid (35B-A3B) thường đến:
- Qwen 3.6-Coder dedicated (theo pattern Qwen 3-Coder, Qwen 2.5-Coder) — sẽ push SWE-bench lên thêm 3–5 điểm
- Các size nhỏ/lớn khác open-weight: 0.8B – 9B cho edge/laptop, 122B-A10B cho workstation, 397B-A17B cho flagship open
- Qwen 3.6 multimodal dedicated (audio / video) theo hướng Gemini / GPT-5
Ngắn gọn: hôm nay là ngày Claude Code local thực sự usable cho production coding — khoảng cách với flagship đã đủ hẹp, setup đã đủ gọn. Xem thêm qwen3.6 trên Ollama library, OpenClaw integration blog, và Qwen 3.6-Plus announcement.