
- Microsoft huấn luyện LLM với trọng số ternary {-1, 0, 1} từ đầu — ma trận nhân biến thành cộng/trừ/bỏ qua trên số nguyên.
- Kết quả: 2B4T nhỏ 0.4GB, nhanh 29ms/token CPU, tốn 0.028J/token, và bitnet.cpp có thể vận hành mô hình 100B trên 1 CPU ở tốc độ 5–7 token/giây.
- Đây không phải nén mô hình, đây là đổi nguyên lý tính toán.
TL;DR
Microsoft Research đã chứng minh một điều mà bình thường nghe như trò đùa: một LLM 100 tỷ tham số chạy được trên một CPU đơn lẻ ở tốc độ đọc của con người (5–7 token/giây). Chìa khoá là kiến trúc BitNet b1.58 — mọi trọng số chỉ nhận 3 giá trị {-1, 0, +1}, tức log₂(3) ≈ 1.58 bit mỗi tham số. Phép nhân ma trận — gánh nặng chính của suy luận LLM — biến thành cộng, trừ và bỏ qua. Không còn float. Không cần GPU đắt tiền. Microsoft đã mở nguồn framework bitnet.cpp và mô hình thực BitNet b1.58 2B4T (2 tỷ tham số, huấn luyện trên 4 nghìn tỷ token) — ngang ngửa LLaMA/Qwen/Gemma cùng cỡ nhưng chỉ cần 0.4 GB RAM và 0.028 J/token.
What's new — Microsoft công bố gì?
Gói công bố của Microsoft Research gồm hai mảnh ghép quan trọng, miễn phí, giấy phép MIT:
- bitnet.cpp — framework suy luận C++ chính thức cho LLM 1-bit. Kernel tuỳ biến cho phép nhân ma trận
W1.58 × A8chạy trực tiếp trên CPU (x86 + ARM) và GPU. Repo GitHub đã đạt 38.5k sao. NPU hỗ trợ đang trong roadmap. - BitNet b1.58 2B4T — LLM 1-bit đầu tiên được huấn luyện từ đầu ở cỡ tỷ tham số, không phải kết quả nén một mô hình float. Trọng số có sẵn trên Hugging Face trong 3 dạng: packed 1.58-bit (suy luận), BF16 (fine-tune), GGUF (cho bitnet.cpp).
Điểm quan trọng cần nhấn mạnh: đây không phải post-training quantization. Hầu hết mô hình "nén xuống 4-bit" hiện tại được huấn luyện ở độ chính xác đầy đủ rồi mới cắt bit — gần như luôn mất điểm trên benchmark. BitNet học bên trong ràng buộc ternary ngay từ token đầu tiên. Kết quả: không hao hụt.
Why it matters — vì sao đây là thay đổi nguyên lý
Mô hình LLM truyền thống dùng trọng số BF16/FP16 — mỗi giá trị là một số thực (ví dụ -1.4721). Suy luận nghĩa là hàng tỷ phép nhân số thực mỗi token, và đó là lý do GPU tồn tại.
BitNet đảo ngược bản chất của phép toán:
- ×1 → giữ nguyên giá trị
- ×(-1) → đảo dấu
- ×0 → bỏ qua
Không còn phép nhân số thực. Chỉ còn cộng, trừ, và skip — tất cả trên số nguyên. GPU mất đi lợi thế cố hữu: phần cứng CPU đã dư sức xử lý loại phép toán này, ở mức điện năng thấp hơn một cách đáng kể.
Đây không phải tối ưu nén. Đây là một primitive tính toán khác.
Technical facts — những con số
Cấu hình lượng tử hoá được gọi là W1.58A8: trọng số ternary (absmean quantization) + activation 8-bit (absmax, per-token). Bốn giá trị ternary được đóng gói vào một int8 lưu trong HBM theo chiến lược pack-store-load-unpack-compute.
Hiệu năng suy luận trên phần cứng thương mại, so với llama.cpp chạy cùng mô hình:
| Phần cứng | Speedup | Năng lượng tiết kiệm |
|---|---|---|
| Intel i7-13700H (x86) | 2.37× → 6.17× (tới 6.46× khi giới hạn thread) | 71.9% → 82.2% |
| Apple M2 Ultra (ARM) | 1.37× → 5.07× | 55.4% → 70.0% |
Và con số đáng nhớ nhất: một BitNet b1.58 100 tỷ tham số chạy trên một CPU đạt 6.58 token/giây trên Apple M2 Ultra và 1.70 token/giây trên Intel i7-13700H — tương đương tốc độ đọc của người.
Mô hình 2B4T thật (không phải dummy) có thông số thực tế:
- Bộ nhớ non-embedding: 0.4 GB
- Latency giải mã CPU: 29 ms/token
- Năng lượng ước tính: 0.028 J/token
- Kiến trúc: Transformer với BitLinear, RoPE, squared-ReLU FFN, subln norm, không bias. Tokenizer LLaMA 3 (128,256 vocab). Context 4,096 token.
- Pipeline huấn luyện: pre-train trên 4T token → SFT → DPO.
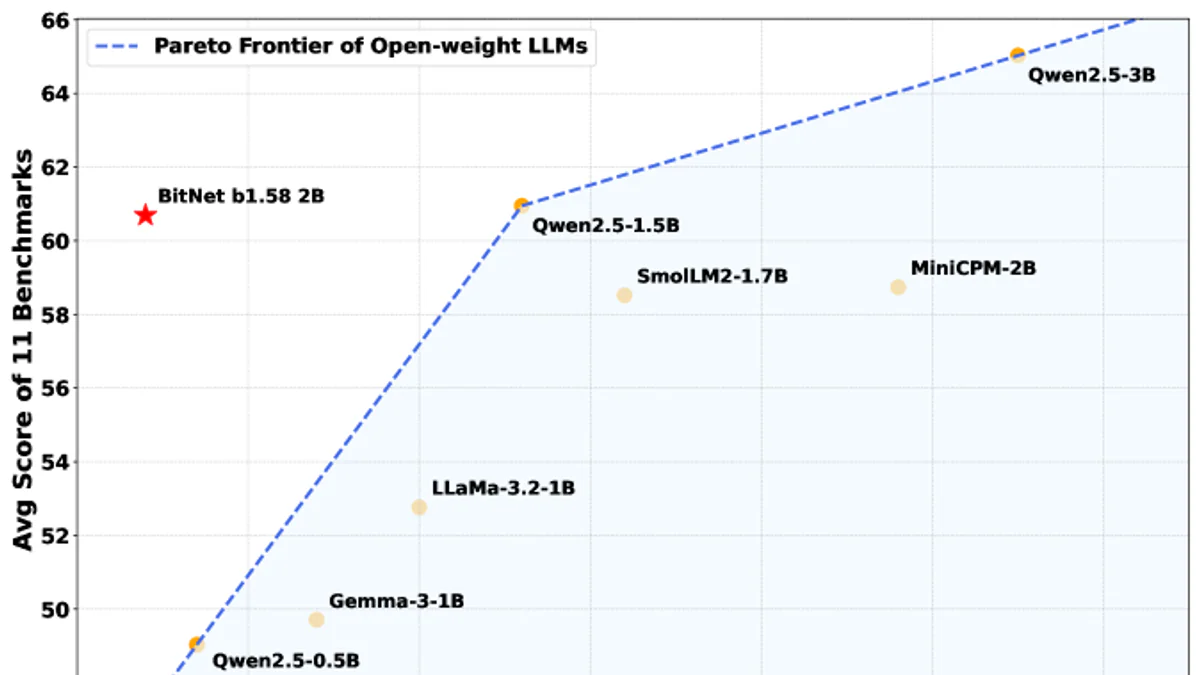
Comparison — so với LLaMA, Qwen, Gemma
Bảng dưới so sánh BitNet 2B4T với các mô hình open-weight full-precision cùng hạng cân:
| Metric | LLaMA 3.2 1B | Gemma-3 1B | Qwen2.5 1.5B | SmolLM2 1.7B | MiniCPM 2B | BitNet b1.58 2B |
|---|---|---|---|---|---|---|
| Bộ nhớ (non-emb) | 2.0 GB | 1.4 GB | 2.6 GB | 3.2 GB | 4.8 GB | 0.4 GB |
| Latency CPU | 48 ms | 41 ms | 65 ms | 67 ms | 124 ms | 29 ms |
| Năng lượng | 0.258 J | 0.186 J | 0.347 J | 0.425 J | 0.649 J | 0.028 J |
| MMLU | 45.58 | 39.91 | 60.25 | 49.24 | 51.82 | 53.17 |
| GSM8K | 38.21 | 31.16 | 56.79 | 45.11 | 4.40 | 58.38 |
| ARC-Challenge | 37.80 | 38.40 | 46.67 | 43.52 | 44.80 | 49.91 |
| WinoGrande | 59.51 | 58.48 | 62.83 | 68.98 | 61.80 | 71.90 |
| Average 11 tasks | 44.90 | 43.74 | 55.23 | 48.70 | 42.05 | 54.19 |
BitNet đứng thứ 2 về điểm trung bình (kém Qwen2.5 1.5B đúng ~1 điểm), thắng tuyệt đối trên GSM8K / ARC / WinoGrande, với bộ nhớ nhỏ 1/6 đến 1/12 và năng lượng thấp ~9× đến 23×. So với quantization INT4 chuẩn (GPTQ, AWQ) áp dụng lên Qwen2.5, BitNet cũng vượt về trung bình (55.01 vs 52.15) ở footprint nhỏ hơn nữa.
Use cases — ai hưởng lợi
- Laptop & máy để bàn: chạy LLM 2B–7B ngay trên Intel/AMD/Apple Silicon, không cần card rời.
- Edge & mobile: bitnet.cpp đã hỗ trợ Windows, Linux, macOS, Android. iPhone và NPU đang trong roadmap.
- GPU-poor: developers không tiếp cận được CUDA GPU giờ có lựa chọn mô hình cỡ tỷ tham số chạy được ở tốc độ hợp lý.
- Thiết bị pin: tiết kiệm 55–82% năng lượng quan trọng với mobile, IoT, wearable, robot.
- Riêng tư: suy luận hoàn toàn cục bộ — prompt và dữ liệu không rời thiết bị.
Limitations & pricing
Vài điểm cần thẳng thắn:
- Mô hình 100B chưa tồn tại trong thực tế. Đó là cấu hình dummy dùng để chứng minh framework bitnet.cpp có thể mở rộng tới size đó. Mô hình 1-bit thật được huấn luyện đầy đủ lớn nhất hiện tại là 2B4T.
- Phải dùng bitnet.cpp để có tốc độ. Chạy thẳng qua HuggingFace
transformerskhông cho lợi ích nào — kernel mặc định không biết xử lý W1.58A8. - GPU hiện tại vẫn chưa tối ưu cho phép toán 1-bit. Kernel CUDA custom có sẵn từ 05/2025, nhưng để giải phóng hết tiềm năng cần hardware co-design.
- Context 4,096 token. Không phù hợp long-context chưa có bản mở rộng.
- Chủ yếu tiếng Anh, đa ngôn ngữ còn đang nghiên cứu.
- Microsoft disclaim thương mại hoá: mô hình nhận được flag "elevated defect rate" trên truy vấn liên quan bầu cử — hiện được định vị là research/development.
- Giá: miễn phí. MIT license cho cả weights lẫn framework.
What's next
Nhìn vào nhật ký phát triển: bài báo đầu về 1.58-bit công bố 27/02/2024, bitnet.cpp 1.0 ra 17/10/2024, mô hình 2B4T lên Hugging Face 14/04/2025, GPU kernel chính thức 20/05/2025. Bản cập nhật 15/01/2026 mới nhất thêm parallel kernel + configurable tiling + embedding quantization, cho thêm 1.15× đến 2.1× speedup trên CPU.
Roadmap công khai: mô hình lớn hơn (7B, 13B+), NPU, mobile (iPhone/Android), context dài hơn, đa ngôn ngữ, đa phương thức, và — quan trọng nhất — hardware co-design cho low-bit ops. Nếu thế hệ chip tiếp theo có mạch riêng cho phép toán ternary, lợi thế năng lượng và tốc độ có thể tăng thêm hàng bậc.
Kết luận: AI không đang nhỏ đi. Toán đang thông minh hơn. Một năm nữa, chạy LLM cục bộ sẽ không còn ấn tượng — không chạy cục bộ mới là cái lạ.
Nguồn: Microsoft/BitNet (GitHub), BitNet b1.58 2B4T (Hugging Face), Technical Report arXiv:2504.12285, 1-bit AI Infra arXiv:2410.16144, InfoQ coverage.

