
- Alibaba vừa open-source Qwen3.6-35B-A3B theo Apache 2.0: 35B tham số tổng, chỉ 3B kích hoạt mỗi token, context 262K, đa phương thức gốc, đạt 73.4 SWE-bench Verified và 51.5 Terminal-Bench 2.0 — vượt nhiều mô hình dense lớn gấp 10 lần.
TL;DR
Ngày 16/04/2026, nhóm Qwen của Alibaba đã open-source Qwen3.6-35B-A3B dưới giấy phép Apache 2.0. Đây là mô hình sparse Mixture-of-Experts với 35 tỉ tham số tổng nhưng chỉ 3 tỉ tham số được kích hoạt mỗi token, context gốc 262.144 tokens (mở rộng ~1.01M với YaRN), đa phương thức gốc (text, ảnh, video). Điểm số nổi bật: 73.4 SWE-bench Verified, 51.5 Terminal-Bench 2.0 (cao nhất trong nhóm so sánh), 85.3 RealWorldQA — vượt Claude Sonnet 4.5 và Gemma4-31B trên nhiều benchmark đa phương thức. Chạy được bản 4-bit GGUF trên RTX 3090/4090 hoặc Mac Apple Silicon 24 GB.
Có gì mới
Qwen3.6-35B-A3B là bản open-weight đầu tiên trong thế hệ Qwen3.6, kế tục Qwen3.5-35B-A3B nhưng được tái thiết kế tập trung vào agentic coding và multimodal reasoning. Model đã có mặt trên Hugging Face, ModelScope, Ollama, Unsloth GGUF, và chạy được trực tiếp trên Qwen Studio. API chính thức sẽ tiếp theo trên Alibaba Cloud Model Studio với tên qwen3.6-flash, tương thích spec của OpenAI và Anthropic.
Một tính năng đáng chú ý là Thinking Preservation: giữ lại các chuỗi suy luận (thinking traces) từ các lượt hội thoại trước để tái sử dụng trong các workflow agent dài hơi, giảm suy luận dư thừa và tối ưu KV cache.
Tại sao quan trọng
MoE 35B/3B-active nghĩa là: bạn có dung lượng kiến thức tương đương một mô hình dense cỡ lớn, nhưng chi phí suy luận chỉ bằng một mô hình 3B. Tức là Qwen3.6-35B-A3B cho phép chạy một model coding/multimodal cấp frontier ngay trên máy cá nhân — không cần datacenter, không phụ thuộc API đám mây, không lộ dữ liệu. Với giấy phép Apache 2.0 (không royalty, dùng thương mại thoải mái), đây là một trong những lựa chọn open-source mạnh và cởi mở nhất ở thời điểm hiện tại.
Thông số kỹ thuật
- Kiến trúc MoE: 256 expert tổng cộng, mỗi token kích hoạt 8 routed expert + 1 shared expert → 3B active params.
- 40 layers với pattern 10 khối lặp: 3×(Gated DeltaNet → MoE) + 1×(Gated Attention → MoE). Gated DeltaNet dùng linear attention (rẻ hơn self-attention). Gated Attention dùng Grouped Query Attention: 16 Q-head / 2 KV-head — giảm áp lực KV cache.
- Hidden dim 2048, expert intermediate dim chỉ 512 → compute per-token thấp.
- Huấn luyện với Multi-Token Prediction (MTP) — speculative decoding nhanh hơn khi infer.
- Context: 262.144 tokens native, mở rộng ~1.01M tokens qua YaRN.
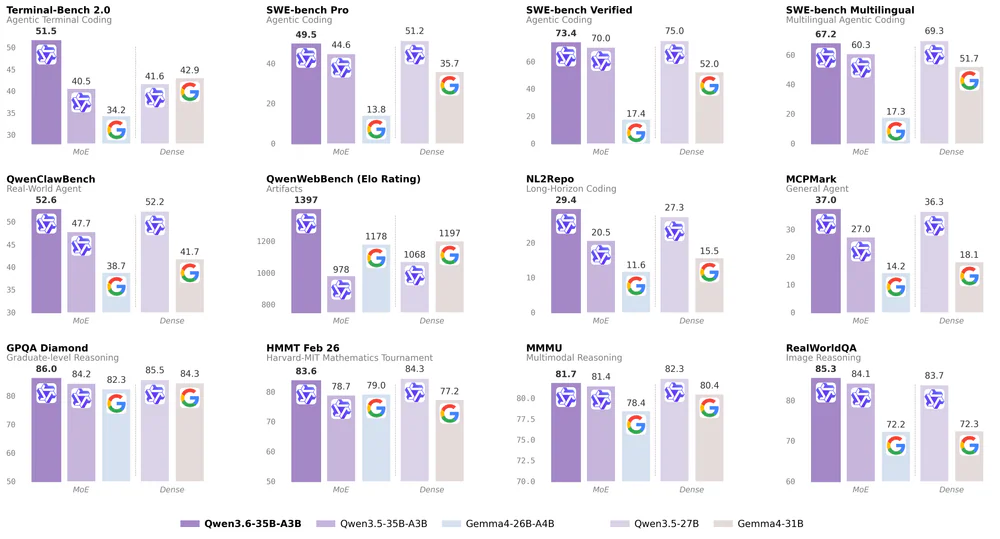
- Coding benchmarks: SWE-bench Verified 73.4, SWE-bench Pro 49.5, Terminal-Bench 2.0 51.5, QwenWebBench 1397.
- Reasoning: AIME 2026 92.7, GPQA Diamond 86.0.
- Multimodal: MMMU 81.7, RealWorldQA 85.3, VideoMMMU 83.7, ODInW13 50.8, RefCOCO 92.0.
So sánh với đối thủ
| Benchmark | Qwen3.6-35B-A3B | Qwen3.5-35B-A3B | Gemma4-31B | Claude Sonnet 4.5 |
|---|---|---|---|---|
| SWE-bench Verified (agentic coding) | 73.4 | 70.0 | 52.0 | — |
| Terminal-Bench 2.0 | 51.5 | 40.5 | 42.9 | — |
| SWE-bench Pro | 49.5 | — | 35.7 | — |
| MMMU (đa phương thức) | 81.7 | — | 80.4 | 79.6 |
| RealWorldQA | 85.3 | — | 72.3 | 70.3 |
| VideoMMMU | 83.7 | — | 81.6 | 77.6 |
Đáng chú ý: với chỉ 3B active params, Qwen3.6-35B-A3B vượt các mô hình dense gấp ~10 lần kích thước active — và trên multimodal thậm chí vượt Claude Sonnet 4.5 ở nhiều bài test.
Dùng cho việc gì
- Agentic coding local: ghép với Claude Code, Qwen Code, Continue.dev, Cursor để chạy agent đọc-hiểu repo, chỉnh code đa file, gọi tool, chạy lệnh terminal.
- Repository-scale reasoning: 262K context đủ nuốt trọn repo vừa/nhỏ trong một prompt — trace dependency, tìm bug xuyên file, refactor.
- Multimodal workflows: đọc screenshot UI, chart, tài liệu PDF có hình, phân tích video ngắn.
- Private / offline deployments: dữ liệu nhạy cảm không ra khỏi máy; giấy phép Apache 2.0 cho phép nhúng trong sản phẩm thương mại không royalty.
Hạn chế & chi phí phần cứng
- Full F16: ~72 GB VRAM (cần 2× A100 hoặc workstation cao cấp).
- 8-bit: ~36 GB VRAM (A100 40 GB một chiếc đủ).
- 4-bit GGUF của Unsloth: ~18–20 GB VRAM (RTX 3090/4090, hoặc Mac Apple Silicon 24 GB như M3 Max / M2 Ultra).
- Không còn hỗ trợ soft-switch inline
/think/nothinknhư Qwen3 — phải bật/tắt reasoning qua API paramenable_thinking: False. - Với các tác vụ reasoning ngoài coding, vẫn chưa đạt mức GPT-4 / Claude Opus.
Tiếp theo
Alibaba cho biết dòng Qwen3.6 open-source sẽ tiếp tục mở rộng với nhiều kích cỡ khác, cùng với việc phát hành API qwen3.6-flash trên Alibaba Cloud Model Studio và open-source benchmark nội bộ QwenClawBench. Nếu bạn đang tìm một mô hình đủ mạnh để làm coding agent chạy local mà không tốn chi phí inference đám mây — đây là thời điểm tốt để thử.
Nguồn: Alibaba Cloud, QwenLM/Qwen3.6 (GitHub), MarkTechPost.

