
- Unsloth vừa ra mắt Studio (beta) — web UI no-code wrap toàn bộ engine Triton kernel tự viết.
- Train Qwen3.5, Gemma 4, DeepSeek, gpt-oss local, nhanh gấp 2×, ít 70% VRAM, không mất accuracy.
- Phân tích kỹ lý do vì sao custom kernel + GRPO + Data Recipes thay đổi cuộc chơi fine-tuning.
TL;DR
Ngày 17/03/2026, UnslothAI ra mắt Unsloth Studio (beta) — web UI no-code chạy 100% local, bọc lên thư viện Unsloth vốn đã nổi tiếng với custom Triton kernel thay thế PyTorch autograd. Kết quả: train 500+ model nhanh gấp 2×, tiết kiệm 70% VRAM, không mất accuracy. Loss curve khớp baseline đến chữ số thập phân thứ 3 vì math là exact, không phải approximation. Studio còn gói GRPO (kỹ thuật RL phía sau DeepSeek-R1), sandboxed code execution, self-healing tool calling và Data Recipes (dựa trên NVIDIA Nemo Data Designer) trong một app duy nhất.
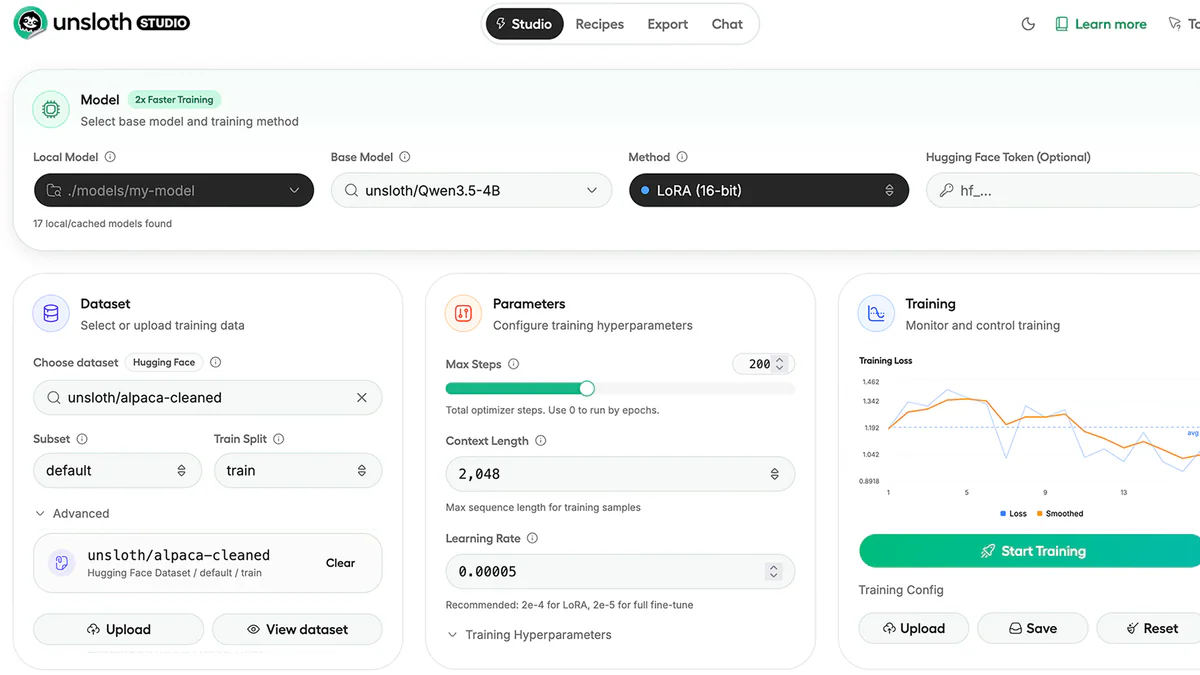
Cái gì mới?
Engine Unsloth đã có từ lâu trong thư viện Python. Điểm mới của unsloth studio là no-code web UI bọc lên cùng engine đó. Cài bằng 3 lệnh:
pip install unsloth
unsloth studio setup
unsloth studioSau khi setup, bạn có giao diện thống nhất để: chọn base model, tải dataset (HF hoặc file local), cấu hình hyperparameter, monitor loss curve real-time, chat với model, rồi export sang GGUF / safetensors / LoRA merged. Toàn bộ chạy offline, không telemetry.
Tại sao đáng quan tâm?
PyTorch autograd mặc định chạy mỗi op thành một GPU call riêng, và mỗi call phải đọc-ghi về global memory trước khi op kế tiếp bắt đầu. Với Transformer hàng chục layer, cái back-and-forth này mới là bottleneck thật sự — không phải compute mà là memory bandwidth.
Unsloth viết tay backprop kernel bằng OpenAI Triton (ngôn ngữ Python-based để viết GPU kernel không cần đụng CUDA C++). Các kernel này:
- Fuse QKV projection + RoPE thành một GPU call duy nhất. Kernel QK rotary embedding fused chạy 2.3× nhanh hơn trên long-sequence, 1.9× trên short. In-place, bỏ hoàn toàn clone/transpose — không tốn VRAM phụ.
- Recompute activation on-the-fly thay vì store, giảm 30–90% VRAM tuỳ model.
- Custom kernel cho SwiGLU / GEGLU, autograd tay cho MLP + self-attention, fuse và tái sử dụng tensor giữa forward và backward.
Và vì không có approximation, loss curve của Unsloth khớp PyTorch tới 3 chữ số thập phân. Đây là điểm phân biệt với nhiều framework tăng tốc khác — speed không đến từ việc hy sinh độ chính xác.
Số liệu kỹ thuật
| Model | Speedup | VRAM reduction |
|---|---|---|
| Gemma 4 (E2B) | 1.5× | 50% |
| Qwen3.5 (4B) | 1.5× | 60% |
| gpt-oss (20B) | 2× | 70% |
| gpt-oss (20B) GRPO | 2× | 80% |
| Llama 3.1 (8B) Alpaca | 2× | 70% |
| embeddinggemma (300M) | 2× | 20% |
| Orpheus-TTS (3B) | 1.5× | 50% |
Install cũng nhanh hơn 6× và nhỏ hơn 50% nhờ precompiled llama.cpp binary.
So sánh: GRPO vs PPO, Unsloth vs autograd thuần
PPO truyền thống cần critic model chạy song song policy model trong lúc train. Critic thường bằng kích thước policy → VRAM gần như gấp đôi. GRPO (Group Relative Policy Optimization, kỹ thuật phía sau DeepSeek-R1) bỏ hẳn critic: sinh nhiều completion cho mỗi prompt, tính advantage từ chất lượng tương đối trong group đó.
- GRPO cắt 40–60% VRAM so với PPO.
- Kết hợp với Triton kernel + QLoRA 4-bit → train reasoning model trên RTX 3090/4090 (hardware consumer) trở nên khả thi.
- Studio đã bọc GRPO vào UI — không còn phải viết loop RL tay.
Use case
Ba kịch bản Studio shine rõ nhất:
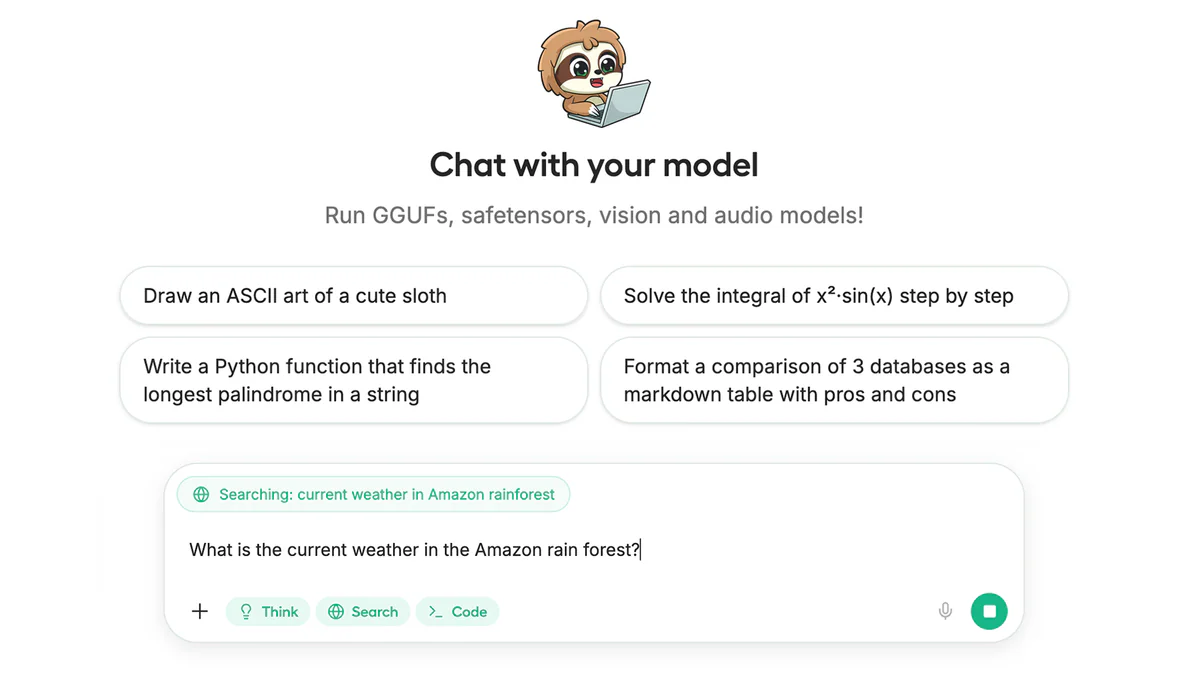
1. Sandboxed inference với verification thực sự. Inference engine trong Studio có sandbox Python + bash — model có thể thật sự chạy code, tính kết quả, verify output trước khi trả lời. Khác hẳn việc chỉ predict code output theo ngữ cảnh. Tool calling còn có self-healing: call fail → auto-correct → retry. Pattern rất thực dụng cho agentic workflow.
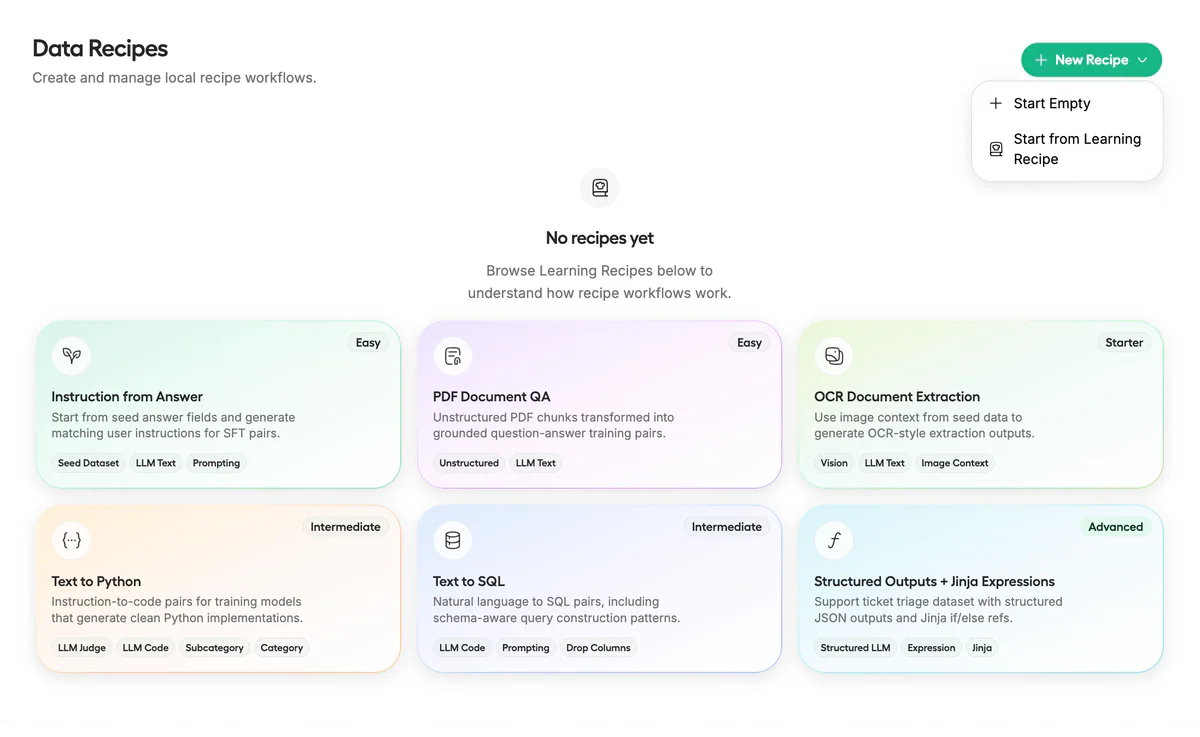
2. Data Recipes thay thế script parse tay. Xây dataset mới là chỗ tốn thời gian nhất của mọi workflow fine-tune. Studio có Data Recipes (dựng trên NVIDIA Nemo Data Designer) — node-based visual workflow: kéo thả PDF/CSV/DOCX/JSONL, transform thành synthetic dataset có cấu trúc, tự format ChatML hoặc Alpaca. Kiến trúc chia tách: React editor (Recipe Studio) + Python backend (DataDesigner).
3. Export & deploy mượt. Train xong → export thẳng ra GGUF / 16-bit safetensors, tự merge LoRA adapter vào base weights. Deploy sang llama.cpp, Ollama, vLLM, LM Studio không cần script trung gian.
Hạn chế & giá
- Beta — bug là chuyện bình thường, không nên cắm vào production pipeline ngay.
- Free, open-source. Core Unsloth package giữ
Apache 2.0; Studio UI dùngAGPL-3.0— nếu fork Studio rồi host SaaS thì phải publish source. - Training cần GPU NVIDIA hoặc Intel. MacOS hiện chỉ chat-only, chưa train được. Chat + Data Recipes chạy trên CPU/Mac OK.
- Multi-GPU và MLX training cho Mac đang trong roadmap, chưa có ở bản beta.
Tiếp theo
Với bản beta hiện tại, Unsloth đã ở top 1–2 trong số các tool open-source hoàn chỉnh cho fine-tune local. Roadmap next: MLX training cho Apple Silicon + multi-GPU Studio. Ai đang làm việc với open-source model local — đặc biệt RTX 3090/4090 user muốn train reasoning model — đây là công cụ đáng bỏ một buổi chiều thử.
Nguồn: Unsloth docs, Substack announcement, MarkTechPost, GitHub.

