
TL;DR
MindDR (Mind DeepResearch) là framework deep research multi-agent do MindDR Team @ Li Auto công bố trên arXiv ngày 16/04/2026. Chỉ dùng base model ~30B tham số (Qwen3-32B dense và Qwen3-30B-A3B MoE), MindDR-v1.5 đạt RACE 51.8 trên MindDR Bench — vượt qua cả Gemini 3.1 (49.65) và Gemini 2.5 Pro (48.34). Toàn bộ training chỉ tốn ~6,000 GPU card-hours, giảm 60% so với phiên bản trước. Đã deploy thực chiến trong Livis (trợ lý AI của Lý Tưởng).
Điểm mới
Trong khi các hệ thống deep research hàng đầu (OpenAI Deep Research, Gemini Deep Research) thường dựa vào foundation model >100B tham số cộng với mid-training tốn kém (thường >150B tokens), MindDR chọn hướng ngược lại: phân rã bài toán research thành nhiều agent nhỏ chuyên biệt, mỗi agent được tối ưu bằng một stage RL riêng.
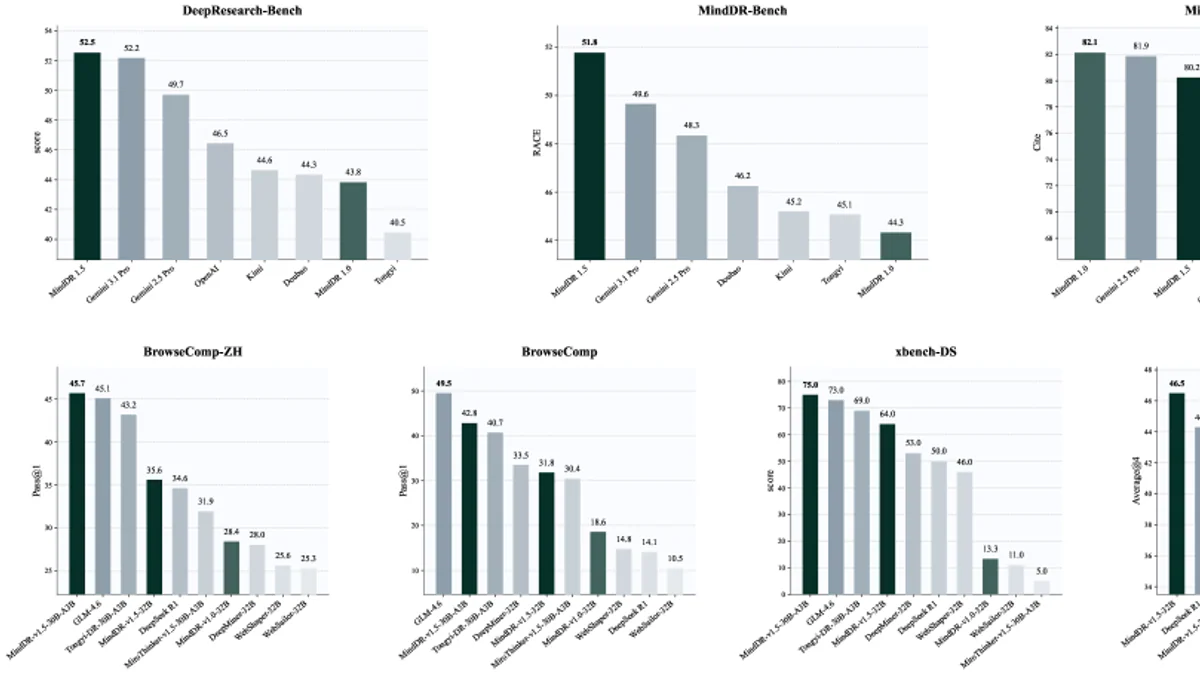
Kết quả trên 5 benchmark deep search lớn (BrowseComp, BrowseComp-ZH, xbench-DS, GAIA-DS, WideSearch) cho thấy MindDR-v1.5-30B-A3B vượt toàn bộ nhóm 30B open-source (Tongyi-DR, MiroThinker, OpenSeeker, WebSailor) — và còn thắng cả GLM-4.6, Kimi K2, DeepSeek R1, Qwen3-235B dù nhỏ hơn 5–8 lần.
Vì sao quan trọng
Deep research agent đang trở thành sản phẩm AI tiêu biểu nhất sau chatbot. Nhưng chi phí inference quá cao: mỗi truy vấn ngốn hàng ngàn token và hàng chục tool call. MindDR chứng minh rằng kiến trúc thông minh đánh bại quy mô brute-force. Khi một mô hình ~30B chạy hiệu quả gấp đôi mà vẫn vượt Gemini 3.1, các startup không cần GPU cluster khổng lồ vẫn có thể cạnh tranh được trong cuộc đua deep research.
Chi tiết kỹ thuật
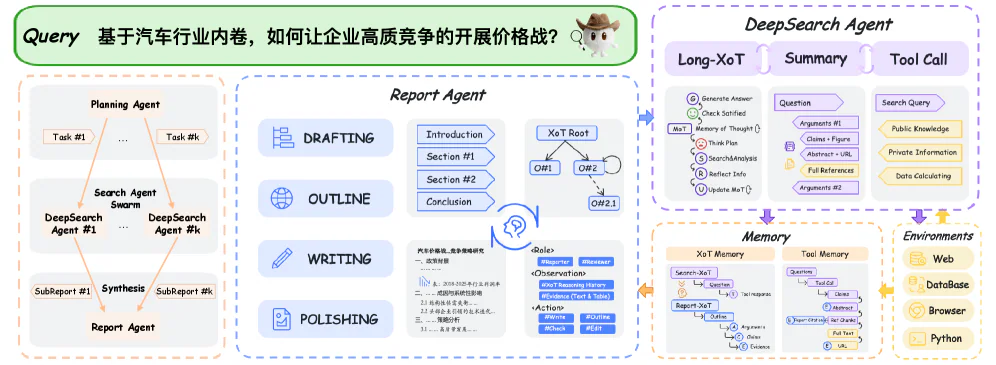
Three-agent architecture (inference time):
- Planning Agent — phân rã yêu cầu, lập kế hoạch search.
- DeepSearch Agent — multi-step retrieval, song song hoá search, cô lập context để giảm gánh nặng long-context.
- Report Agent — giải quyết xung đột thông tin, sinh báo cáo dài human-aligned.
Ba agent phối hợp qua cơ chế Extended Chain-of-Thought, cho phép thực thi search song song trong khi mỗi agent giữ context riêng — vừa nhanh vừa giảm nhiễu.
Four-stage training pipeline:
- SFT cold-start (~0.18B tokens) — học hành vi tool-use, format, multi-turn reasoning theo paradigm ReAct.
- Search-RL — tối ưu accuracy đồng thời giảm token và tool-call. Dùng GSPO (sequence-level importance ratio) ổn định hơn DAPO/GRPO trên backbone MoE.
- Report-RL — resolve information conflict, tăng RACE score cho long-form report.
- Preference alignment — DPO + Self-SFT, sửa các lỗi format và temporal defects còn sót.
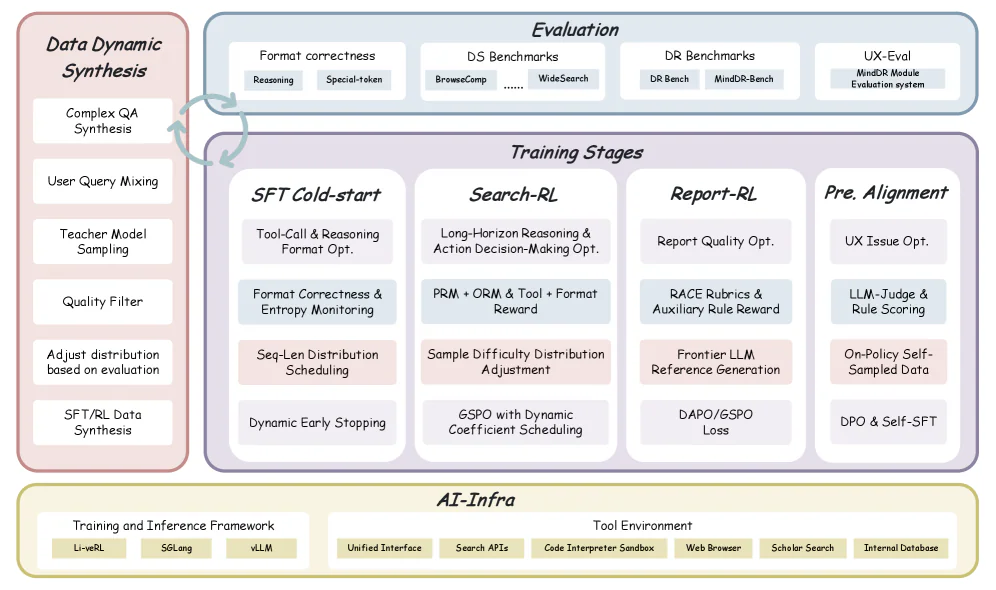
Hiệu quả training: chỉ ~1.03B training tokens và ~6,000 GPU card-hours — giảm 60% so với MindDR-v1.0 (15K card-hours, 3.6B tokens).
So sánh benchmark
Trên DeepSearch benchmark (BrowseComp-ZH, BrowseComp, xbench-DS), MindDR-v1.5-30B-A3B đạt SOTA trong nhóm 30B:
| Model | BrowseComp-ZH | BrowseComp | xbench-DS |
|---|---|---|---|
| MindDR-v1.5-30B-A3B | 45.7 | 42.8 | 75.0 |
| Tongyi-DR-30B-A3B | 43.2 | — | — |
| MiroThinker-v1.5-30B-A3B | 31.9 | — | — |
| OpenSeeker-30B-A3B | 26.4 | — | — |
| WebSailor-32B | 25.6 | — | — |
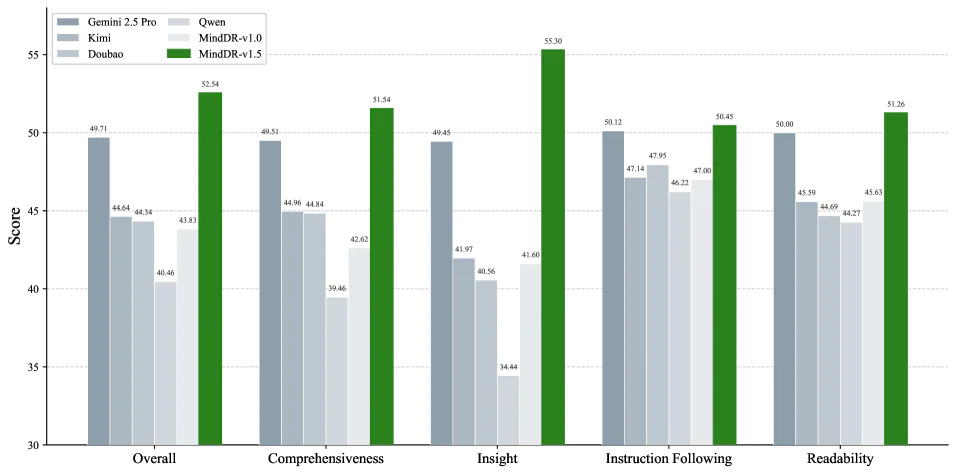
Trên MindDR Bench (RACE rubric), MindDR-v1.5 vượt Gemini 3.1 và 2.5 Pro ở 4/5 hạng mục:
| Model | RACE | Comp. | Insight | Inst. | Read. | C.Acc. |
|---|---|---|---|---|---|---|
| MindDR-v1.5 | 51.77 | 52.17 | 51.77 | 50.55 | 52.18 | 80.25% |
| Gemini 3.1 | 49.65 | 49.83 | 50.75 | 49.32 | 46.89 | 77.20% |
| Gemini 2.5 Pro | 48.34 | 47.56 | 46.88 | 49.47 | 50.23 | 81.86% |
| Doubao | 46.25 | 48.21 | 40.88 | 48.71 | 48.18 | 68.43% |
Điểm vượt trội thứ hai: temporal error rate chỉ 2.0% so với Gemini 10.2% và Doubao 14.0% — báo cáo MindDR ít sai mốc thời gian nhất nhóm.
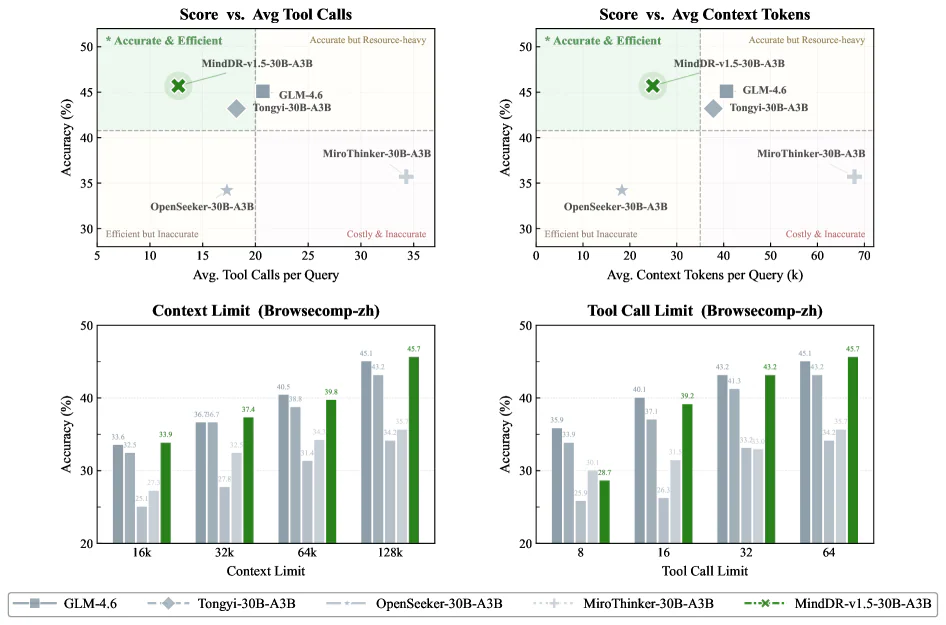
Về hiệu quả test-time, MindDR-v1.5-30B-A3B nằm trong vùng "Accurate & Efficient" — accuracy cao nhất BrowseComp-ZH với số token và tool call ít nhất trong nhóm top-performing.
Use cases
MindDR đã production trong Livis — trợ lý AI tích hợp trên xe điện Lý Tưởng (Li Auto). MindDR Bench gồm 500 truy vấn thật từ user, trải dài 16 lĩnh vực: ô tô, du lịch, công nghệ, tài chính, pháp luật...
Tasks chính: open-domain retrieval, kiểm chéo nhiều nguồn, long-horizon reasoning, sinh báo cáo dài có cấu trúc. Đối thủ trực tiếp: OpenAI Deep Research, Gemini Deep Research, Tongyi DeepResearch, MiroThinker.
Hạn chế & chi phí
Hạn chế:
- Context dài hơn 128K vẫn là bài toán mở (94% format correctness ở 128K).
- Citation accuracy 80.25% vẫn thua Gemini 2.5 Pro (81.86%).
- Đánh giá chiều sâu (methodological soundness, novelty) chưa bắt được bằng RACE rubric, cần human eval.
Chi phí & license: Paper public CC BY-NC-ND 4.0, MindDR Bench (500 query) cũng public. Tuy nhiên trọng số model chưa release ra công chúng — hiện chỉ chạy nội bộ Li Auto. Đây là điểm khác biệt với Tongyi DeepResearch và MiroThinker đã open weight.
Hướng tiếp theo
Paper nêu hai hướng nghiên cứu kế tiếp: (1) chiến lược context dài hơn — hierarchical memory, selective context compression, adaptive attention; (2) human evaluation protocol cho methodological soundness và argument novelty mà rubric tự động chưa nắm được.
Với việc một mô hình 30B production vượt được Gemini 3.1, kỳ vọng tiếp theo là cộng đồng open-source sẽ tái lập kết quả này trên các backbone khác (Llama, Mistral, Qwen3 tiếp theo). Cuộc đua deep research từ giờ sẽ là cuộc đua kiến trúc + training pipeline, không còn là cuộc đua scale tham số.
Nguồn: arXiv 2604.14518, alphaXiv overview, DeepResearch Bench Leaderboard.