
- Google DeepMind vừa công bố Vision Banana — một model unified được fine-tune nhẹ từ Nano Banana Pro, giải mọi bài toán vision (segmentation, depth, surface normal) bằng cách coi chúng là bài toán sinh ảnh.
- Và nó vượt qua cả Segment Anything lẫn Depth Anything.
TL;DR
Ngày 22/04/2026, Google DeepMind công bố Vision Banana — model unified đầu tiên đánh bại hoặc ngang tầm các specialist hàng đầu như Segment Anything và Depth Anything trên hàng loạt tác vụ 2D và 3D, chỉ bằng cách reframing vision tasks thành image generation. Base model là Nano Banana Pro, chỉ instruction-tuning nhẹ trên một lượng nhỏ vision data. Paper: arXiv:2604.20329.
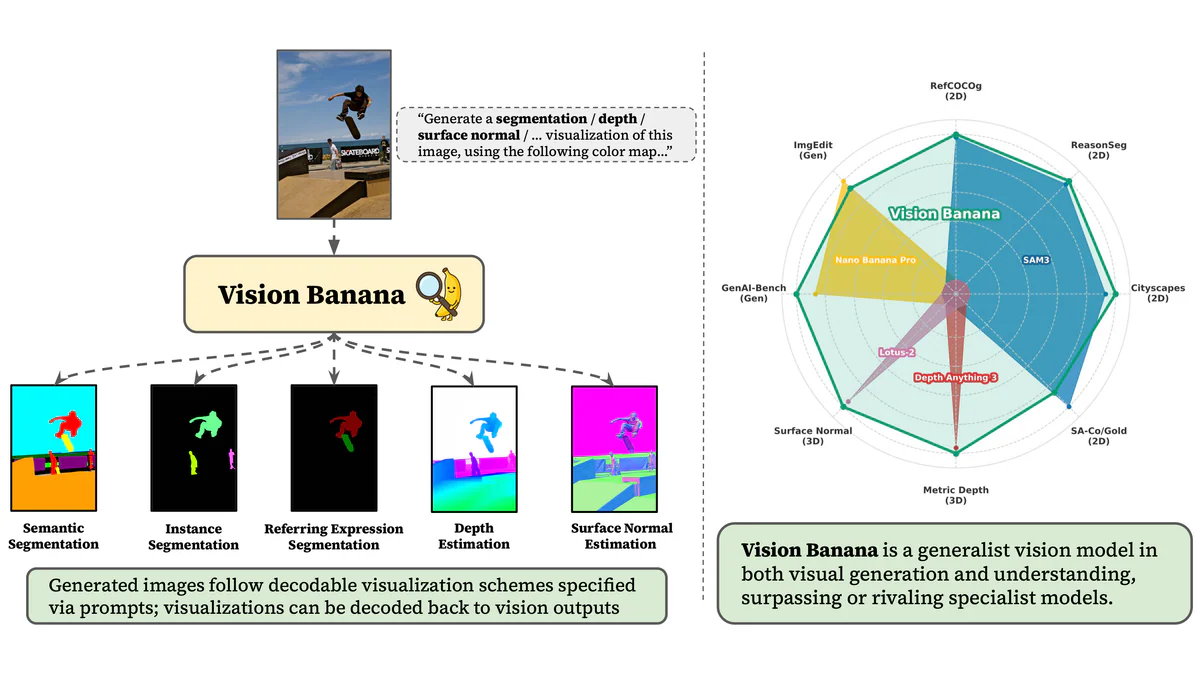
Vision Banana có gì mới
Ý tưởng trung tâm rất gọn: nếu image generation đủ tốt, mọi output của vision task đều có thể parameterize thành một ảnh RGB. Semantic mask? Ảnh với color map. Depth map? Ảnh grayscale encode độ sâu. Surface normal? Ảnh RGB encode hướng pháp tuyến. Thay vì huấn luyện từng specialist cho từng task, Vision Banana dùng image generation như một universal interface — đúng vai trò mà text generation đã đóng cho NLP trong kỷ nguyên LLM.
Model được build trên Nano Banana Pro (Gemini 3 Pro Image model), sau đó instruction-tune trên mixture của (1) dữ liệu gốc NBP và (2) một lượng nhỏ vision task data. Không train từ đầu, không thay kiến trúc backbone — một cú fine-tune nhẹ là đủ để biến một image generator trở thành generalist vision learner.
Vì sao đây là bước ngoặt
Trong 5 năm qua, CV đã chứng kiến sự thống trị của các specialist foundation model: SAM / SAM 2 cho segmentation, Depth Anything cho depth. Mỗi cái xuất sắc ở một lane. Vision Banana nói rằng một model generative duy nhất có thể ăn hết các lane đó — đồng thời vẫn giữ được khả năng sinh ảnh gốc. Đây là khoảnh khắc "LLM" của computer vision: một backbone, nhiều tác vụ, chất lượng SoTA, prompt bằng ngôn ngữ tự nhiên.
Hệ quả kéo theo: stack tool cho robotics, AR/VR, auto-editing, autonomous driving có thể thu gọn đáng kể. Thay vì chạy 3–4 model cho cùng một frame ảnh, chỉ cần một inference call.
Technical facts
Vision Banana đạt state-of-the-art trong zero-shot transfer trên 3 nhóm tác vụ:
| Tác vụ | Benchmark | Kết quả |
|---|---|---|
| Semantic segmentation (2D) | Cityscapes | 0.842 mIoU |
| Metric depth (3D) | Average 6 benchmarks | 0.882 δ₁ |
| Surface normal (3D) | Average 3 benchmarks | 15.549° mean angular error |
5 tác vụ được hỗ trợ chính thức:
- Semantic segmentation — gán nhãn per-pixel với color map tuỳ biến qua prompt
- Instance segmentation — phân biệt từng instance bằng màu khác nhau
- Referring expression segmentation — mask theo mô tả text (vd "người đang skate")
- Monocular metric depth estimation — depth map từ một ảnh duy nhất
- Surface normal estimation — bản đồ hướng pháp tuyến bề mặt

So với các specialist hiện tại
| Mô hình | Phạm vi | Kiến trúc | Đối đầu Vision Banana |
|---|---|---|---|
| SAM / SAM 2 | Segmentation (prompt-based) | Specialist | Vision Banana rival hoặc beat trên nhiều seg benchmark |
| Depth Anything v2 | Monocular depth | Specialist | Vision Banana rival hoặc beat ở metric depth |
| Vision Banana | 5 tác vụ 2D + 3D + gen | Generalist từ image generator | — |
Điểm đắt giá: Vision Banana vẫn giữ nguyên năng lực sinh ảnh của Nano Banana Pro. Một tool duy nhất cover cả creative generation lẫn structured understanding.
Use cases thực tế
- Robotics / AR/VR: depth + normal + segmentation từ một camera qua một model duy nhất.
- Image editing: mask tự động qua prompt ngôn ngữ tự nhiên — "segment cái áo đỏ" là xong.
- Autonomous driving R&D: prototype nhanh với Cityscapes-grade segmentation mà không cần train specialist.
- Creative tools: cùng một model vừa generate, vừa hiểu ảnh — giảm số API call, giảm latency pipeline.

Limitations & pricing
- Paper nhấn mạnh zero-shot transfer — chưa công bố kết quả fine-tune per-dataset.
- Weights và API chưa public tại thời điểm announcement; trang project thuần research disclosure, không có download hay bảng giá.
- Inference cost thừa kế backbone Nano Banana Pro — nặng hơn SAM hoặc Depth Anything V2 khi xét per-image throughput.
- Độ chính xác bị chặn trên bởi resolution và tokenization fidelity của image output — không tuyệt đối phù hợp cho các use case cần pixel-accurate mask (vd medical segmentation).

What's next
Framing "image generation as universal interface" mở cửa cho nhiều tác vụ vision khác: optical flow, keypoints, pose, object tracking, thậm chí là video understanding. Nếu DeepMind thương mại hoá qua Gemini API hoặc Vercel AI Gateway, ranh giới giữa "generate" và "understand" trong tool chain CV sẽ biến mất — y như cách mà chat completion đã nuốt cả classification, summarization, extraction ở phía NLP.
Nguồn: vision-banana.github.io, Google DeepMind publications, arXiv:2604.20329.



