
- Moonshot AI tung Kimi K2.6 (GA 21/04/2026) — model open-weight 1T MoE chạy autonomous 12+ giờ, điều phối 300 sub-agent.
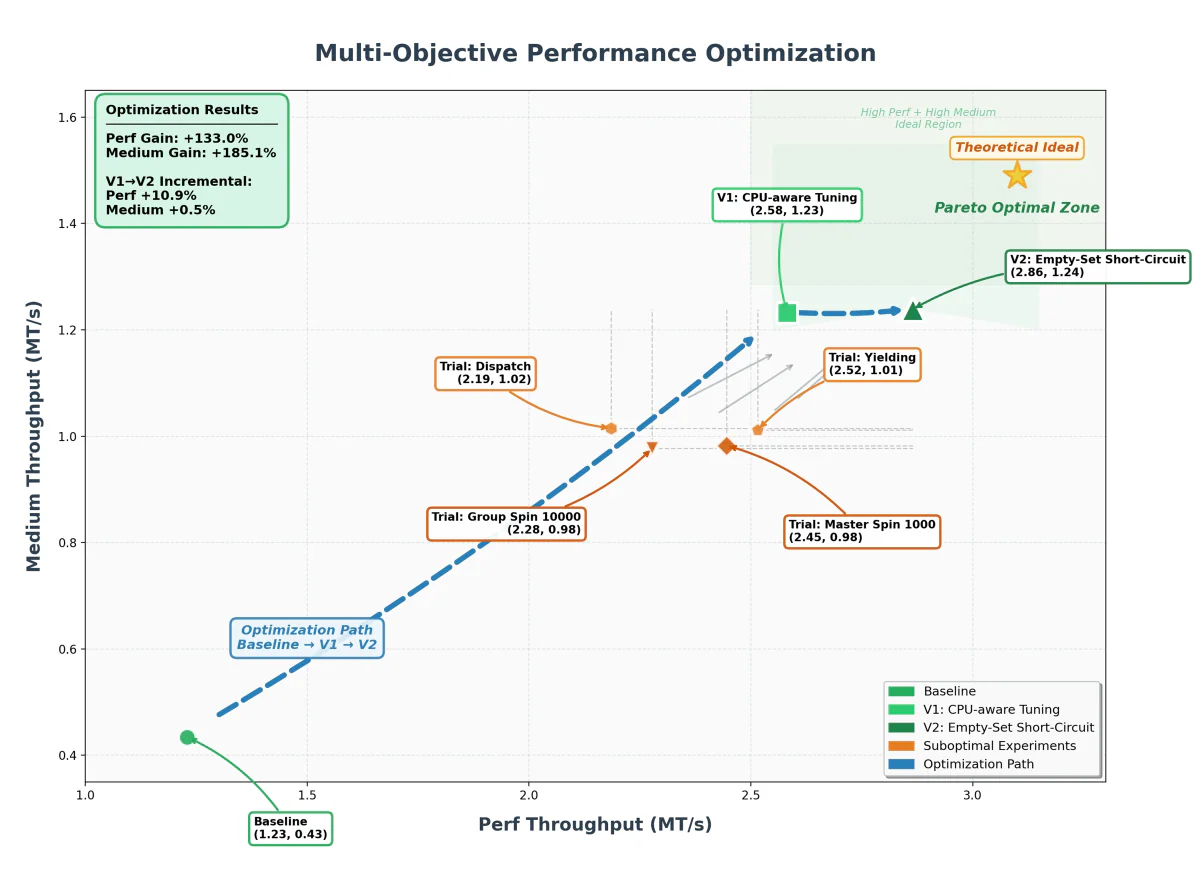
- Case study nổi bật: K2.6 tự overhaul exchange-core (matching engine tài chính 8 năm tuổi, đã tối ưu sát trần), đọc flame graph, đổi thread topology 4ME+2RE → 2ME+1RE, và bật throughput trung vị lên +185% (0.43 → 1.24 MT/s), peak +133% (1.23 → 2.86 MT/s) sau 13 giờ, 1,000+ tool call, 4,000+ dòng code sửa.
TL;DR
Moonshot AI phát hành Kimi K2.6 (GA 21/04/2026) — model open-weight 1T tham số (32B active/token) hướng thẳng vào long-horizon autonomous coding. Case study đáng chú ý nhất: K2.6 tự một mình đại tu exchange-core — một matching engine tài chính Java 8 năm tuổi, vốn đã được tối ưu sát trần — trong một phiên chạy liên tục 13 giờ, thực hiện 1,000+ tool call, sửa 4,000+ dòng code, thử 12 chiến lược tối ưu, và đổi thread topology lõi từ 4ME+2RE sang 2ME+1RE. Kết quả: throughput trung vị tăng +185% (0.43 → 1.24 MT/s), peak tăng +133% (1.23 → 2.86 MT/s). Đây là bằng chứng thực nghiệm cho "AI senior engineer" chứ không phải trình diễn benchmark.
Có gì mới trong K2.6
K2.6 không phải là bước nhảy kiến trúc. Nó giữ nguyên backbone 1T MoE của series K2 (1T tổng / 32B active, 384 experts, 8 active + 1 shared per token, MLA attention, SwiGLU, MuonClip). Điểm mới nằm ở lớp thực thi (execution layer) bao quanh model — đúng thứ cần để agent chạy 12 giờ không tự bung:
- Context 262,144 tokens, đủ chứa một mid-sized monorepo + test output + scratchpad của agent.
- Automatic context compression: model tự tóm tắt/lược bỏ lịch sử khi sắp tràn — phiên 12 giờ không bị drift ở giờ thứ 9.
- Agent Swarm v2: spawning/scheduling/reconciling tối đa 300 sub-agents trên 4,000 bước phối hợp — gấp 3 lần K2.5 (100 agents / 1,500 bước).
- Proactive autonomy: tuned để chạy 24/7 theo task queue, biết nhận ra "tao đang kẹt" và replan thay vì ảo tưởng đã xong.
Vì sao exchange-core là bằng chứng thuyết phục
exchange-core là open-source Java, 8 năm tuổi, đã qua nhiều vòng tay con người tối ưu. "Vụng tay" là không được phép: nếu matching invariants vỡ thì toàn bộ logic khớp lệnh sai, không chỉ chậm. Đây chính là workload mà hầu hết model trước đó thất bại âm thầm — chúng sinh ra diff trông hợp lý nhưng regress correctness.
Cái khác của K2.6 là cách tiếp cận: nó đọc CPU flame graph và allocation flame graph để tìm bottleneck ẩn, rồi dám tái cấu hình thread topology lõi — một quyết định kiến trúc, không chỉ micro-optimization. Trên một engine đã sát trần hiệu năng, vẫn moi thêm được +185% throughput trung vị chỉ bằng một phiên chạy một mình qua đêm.
Chi tiết kỹ thuật quan trọng
- Thời lượng phiên: 13 giờ liên tục, không can thiệp người.
- Tool calls: 1,000+ lần gọi công cụ.
- Code modified: 4,000+ dòng trong codebase Java lớn.
- Iterations: 12 chiến lược tối ưu được thử, so sánh, loại bỏ, chồng lớp.
- Thread topology:
4ME+2RE→2ME+1RE(Matching Engine / Risk Engine). - Throughput trung vị (Medium): 0.43 → 1.24 MT/s (+185%).
- Throughput peak (Perf): 1.23 → 2.86 MT/s (+133%).
Bên cạnh đó, Moonshot cũng công bố hai case study khác: tối ưu inference Qwen3.5-0.8B trên Mac bằng Zig (12+ giờ, ~193 tok/s, nhanh hơn LM Studio ~20%), và một RL infra agent chạy autonomous 5 ngày liên tục quản lý monitoring/incident của chính đội Moonshot.
So với GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro

| Benchmark | K2.6 | GPT-5.4 (xhigh) | Claude Opus 4.6 | Gemini 3.1 Pro | K2.5 |
|---|---|---|---|---|---|
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | 54.2 | 50.7 |
| SWE-Bench Verified | 80.2 | — | 80.8 | 80.6 | 76.8 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | 65.4 | 68.5 | 50.8 |
| LiveCodeBench v6 | 89.6 | — | 88.8 | 91.7 | 85.0 |
| HLE-Full w/ tools | 54.0 | 52.1 | 53.0 | 51.4 | 50.2 |
| DeepSearchQA (F1) | 92.5 | 78.6 | 91.3 | 81.9 | 89.0 |
K2.6 dẫn trên SWE-Bench Pro (bài test hard-cut GitHub issues thật), HLE-Full w/ tools (tool-augmented reasoning) và DeepSearchQA. Gemini 3.1 Pro vẫn dẫn Terminal-Bench và LiveCodeBench; GPT-5.4 dẫn pure reasoning (AIME, GPQA). Điểm khác biệt lớn: K2.6 là option open-weight duy nhất ở dải này.
Ai nên dùng, dùng vào đâu
- Fintech & systems architects: refactor legacy Java/C++ nặng, tối ưu hiệu năng mà không làm vỡ invariant — đúng kịch bản exchange-core.
- DevOps / SRE: giao agent chạy 24/7 quản lý alert, incident response, full-cycle từ cảnh báo đến khắc phục (Moonshot đã chạy 5 ngày liên tục trên infra thật của họ).
- Full-stack dev: design-to-code Next.js App Router + auth + DB; Vercel báo >50% cải thiện trên internal bench so với K2.5.
- Agent swarm knowledge work: 100 sub-agents đọc 1 CV → 100 resume tuỳ biến theo 100 job; scan Google Maps tìm store thiếu website → sinh landing page hàng loạt.
- Low-level systems & niche languages: Zig/Rust — K2.6 generalize out-of-distribution tốt trên ngôn ngữ ít dữ liệu huấn luyện.
Giới hạn & pricing
- Open-weight, không open-source: weights trên Hugging Face (
moonshotai/Kimi-K2.6) dưới Modified MIT License, nhưng training data + training code không công khai. - API: OpenAI-compatible tại
https://api.moonshot.ai/v1, model IDskimi-k2.6vàkimi-k2.6-thinking. Drop-in được cho workflow Claude Code hiện có (Anthropic-format cũng hỗ trợ). - Access: Kimi.com, Kimi App, API, Kimi Code CLI, Kilo Gateway (VS Code/JetBrains), free tier qua Cloudflare Workers AI.
- Pricing: MoE inference rẻ hơn frontier đóng đáng kể. Phiên autonomous tốn token — Moonshot khuyến cáo budget theo session, không theo request.
- Self-host: 1T full cần multi-GPU H100-class; bản quantize 3-bit/4-bit chạy được trên hardware nhỏ hơn nhưng giảm chất lượng.
- Điểm yếu: Agent Swarm latency tính bằng phút, không phù hợp chat sub-second. Kém Claude 4.6 về nuanced refusal/safety. Model "rất sáng tạo" — thiếu prompt rõ ràng sẽ tự bay.
Chặng kế: K3 đang chờ chạy trên "runway" này
Moonshot đi từ K2.6 Code Preview (13/04/2026) đến GA (21/04/2026) chỉ trong 8 ngày — rất nhanh so với nhịp 2-3 tháng/major update họ duy trì gần một năm. Giới quan sát đọc K2.6 như runway infrastructure cho Kimi K3: 12h execution envelope + 300-agent swarm + context compressor là những capability chỉ hợp lý khi có một base model lớn hơn sắp landing. Leak Reddit trước đó nhắc đến K3 với 3-4T tham số để đuổi sát frontier Mỹ. Nếu nhịp preview-to-GA tiếp tục nén, K3 có thể đến sớm hơn người ta tưởng.
Nguồn: Moonshot AI official blog, MarkTechPost, Kilo Blog, @Kimi_Moonshot trên X.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ