
- Nico Martin open-source một Chrome extension chạy AI agent hoàn toàn local bằng Gemma 4 E2B trên Transformers.js + WebGPU.
- Đọc tabs, history, page content, tool calling — không server, không API key.
- Phần hay không phải là nó chạy được, mà là cách nhét LLM đa gigabyte vào service worker của extension và chia sẻ qua mọi tab.
TL;DR
Nico Martin vừa công bố gemma4-browser-extension — một Chrome extension chạy AI agent hoàn toàn trên máy người dùng, dùng Gemma 4 E2B (ONNX) trên Transformers.js + WebGPU. Agent có thể liệt kê/chuyển tab, hỏi nội dung trang hiện tại, highlight element, và tìm kiếm lịch sử duyệt web bằng semantic search. Toàn bộ inference chạy local, không gửi byte nào lên server. Phần thú vị nhất không phải là "chạy được", mà là cách tách kiến trúc thành background worker + side panel + content script để nhét LLM đa gigabyte vào môi trường extension.

Cái gì mới
Repo là một bản tham khảo sạch cho pattern "on-device LLM agent trong Chrome extension". Agent expose 6 tool qua function calling của Gemma 4:
get_open_tabs,go_to_tab,open_url,close_tab— quản lý tab qua ngôn ngữ tự nhiênask_website— RAG trên trang hiện tại, embedding bằngall-MiniLM-L6-v2, trả về các đoạn khớp nhất theo semantic similarityhighlight_website_element— scroll + highlight DOM element mà agent chọnfind_history— semantic search trên lịch sử duyệt web, vector embeddings lưu trong IndexedDB, có filter theo thời gian
Model chính là onnx-community/gemma-4-E2B-it-ONNX — Gemma 4 E2B instruction-tuned, convert sang ONNX để Transformers.js chạy trên WebGPU. Yêu cầu: Chrome 113+ với WebGPU, GPU có dung lượng VRAM vừa phải.
Tại sao đáng chú ý
Từ cuối 2024, "browser agent" là từ khoá nóng — OpenAI Operator, Anthropic Computer Use, Perplexity Comet. Tất cả đều dựa vào một model cloud gọi ngược về trình duyệt qua screenshot hoặc accessibility tree. Mỗi click = một vòng round-trip. Privacy kém, latency cao, tốn token.
Dự án này demo một hướng đối xứng: đưa model vào chính extension. Khi model đủ nhỏ (2.3B effective params) và backend browser đủ mạnh (WebGPU, Transformers.js), agent không cần cloud để hoạt động. Đây cũng là lần đầu một open model cỡ E2B đạt τ2-bench agentic tool use 29.4% — so với Gemma 3 27B chỉ 6.6%, là một bước nhảy 4.5 lần trong năng lực gọi tool của model "nhỏ".
Kiến trúc: tách ba tiến trình
Điểm hay nhất của repo là cách tổ chức ba loại context trong một Chrome extension:
- Background service worker — nơi host model. Transformers.js singleton, load một lần duy nhất, dùng chung cho mọi tab/panel. Không load lại khi user mở tab mới. Service worker được giữ sống trong suốt inference (có thể mất vài giây). Đây là vị trí duy nhất có thể dùng WebGPU liên tục mà không bị terminate khi popup đóng.
- Side panel (React) — UI chat, state bền vững trong suốt session. Giao tiếp với background qua
chrome.runtime.sendMessage/onMessage. Khác với popup cũ (đóng là mất state), side panel bám bên cạnh page và giữ conversation context. - Content script — chạy trong context của từng trang. Chỉ tier này truy cập được DOM thật. Nó extract structured content (headings, paragraphs, lists) gửi về background để embed, và highlight element khi agent gọi tool.
Dòng dữ liệu khi user hỏi "bài này nói gì về WebGPU?":
Side Panel → sendMessage → Background (Gemma 4 inference)
↓ tool call: ask_website
Content Script (extract DOM, gửi chunks)
↓ embeddings
Background (MiniLM embed + cosine sim)
↓ top-k chunks
Gemma 4 (compose answer)
↓ message
Side Panel (render)Lý do tách: ML inference nặng không được block UI; model multi-GB không được load lại mỗi tab; DOM chỉ accessible trong content script. Đây là pattern gần như tối ưu cho bất kỳ ai muốn ship local LLM qua extension (password manager có AI, writing assistant, accessibility tool...).
Thông số kỹ thuật
| Thành phần | Chi tiết |
|---|---|
| LLM | Gemma 4 E2B-IT (2.3B eff / 5.1B total, 128K context) |
| Format | ONNX, quantized |
| Runtime | Transformers.js + WebGPU (Chrome 113+) |
| Embeddings | all-MiniLM-L6-v2 (384-dim) |
| Vector store | IndexedDB (history), in-memory (page RAG) |
| UI | React, Chrome side panel API |
| License | Gemma 4 Apache 2.0 |
So sánh: Gemma 4 E2B vs các variant khác
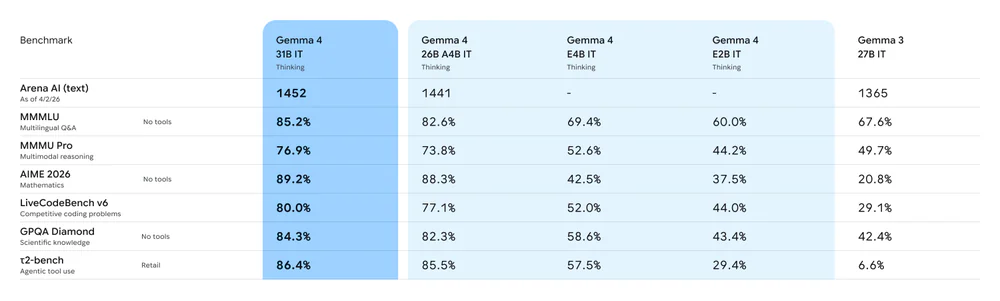
Gemma 4 family (Google DeepMind release ngày 2/4/2026, Apache 2.0):
| Model | Params | Context | Arena Elo | τ2-bench |
|---|---|---|---|---|
| E2B (dùng trong extension) | 2.3B eff / 5.1B | 128K | — | 29.4% |
| E4B | 4.5B eff / 8B | 128K | — | 57.5% |
| 26B A4B MoE | 4B active / 26B | 256K | 1441 | 85.5% |
| 31B dense | 31B | 256K | 1452 | 86.4% |
| Gemma 3 27B (tham chiếu) | 27B | 128K | 1365 | 6.6% |
So với agent cloud (Operator, Computer Use): extension này chậm hơn ở reasoning phức tạp nhưng thắng tuyệt đối ở privacy, latency local, và chi phí (zero).
Ứng dụng thực tế
- Research assistant riêng tư — "tóm tắt bài này", "trang này nói gì về X" mà không leak nội dung cho bên thứ ba.
- Semantic history search — "tìm bài tuần trước về WebGPU" hiệu quả hơn keyword history của Chrome.
- Tab orchestration — "đóng hết tab GitHub", "chuyển sang tab docs".
- Môi trường compliance — legal, healthcare, tài chính — nơi mọi byte duyệt web không được rời thiết bị.
- Reference architecture — dev ship local LLM qua extension có thể copy pattern service-worker-as-engine.
Giới hạn & pricing
- Miễn phí, mã nguồn mở. Gemma 4 Apache 2.0 — dùng thương mại thoải mái.
- Cần Chrome 113+ và GPU hỗ trợ WebGPU. Máy cũ là không chạy được.
- Cold start: lần đầu download ~2GB weights ONNX. Sau đó cache.
- E2B là model 2.3B — độ sâu suy luận thấp hơn cloud frontier. Tool selection có thể miss ở query phức tạp.
- Chrome-only (Manifest V3). Port Firefox/Safari không trivial.
Tiếp theo
Ba hướng mở rộng tự nhiên: (1) swap E4B để thêm audio input → "nghe podcast này rồi tóm tắt"; (2) dùng vision head của Gemma 4 để agent "nhìn" screenshot trang thay vì chỉ parse DOM (giải được các site heavy JS/canvas); (3) port MV3 qua Firefox/Edge. Ngoài ra, pattern trong repo nên trở thành template cho mọi extension local-first AI.
Nguồn: nico-martin/gemma4-browser-extension, blog.google — Gemma 4, Hugging Face — Welcome Gemma 4, tweet gốc.
