
- DeepSeek vừa tung V4-Pro và V4-Flash — hai mô hình MoE open-weights với context 1 triệu token, đánh bại mọi model mở trên benchmark code, bám sát Gemini 3.1-Pro và GPT-5.4 với giá chỉ bằng một phần nhỏ.
- V4-Pro là mô hình open-weights lớn nhất từ trước tới nay.
TL;DR
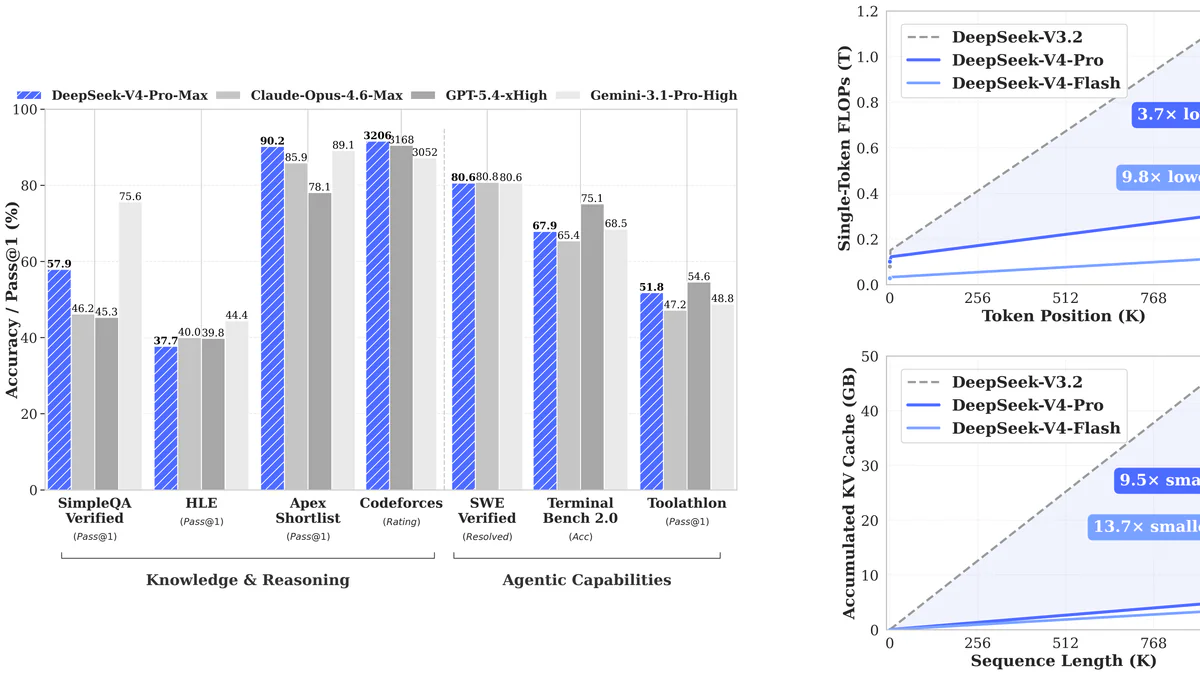
Đúng tròn một năm sau "khoảnh khắc Sputnik" của AI Trung Quốc, DeepSeek quay lại với V4-Pro (1.6T tham số, 49B kích hoạt) và V4-Flash (284B, 13B kích hoạt). Cả hai đều là MoE open-weights theo giấy phép MIT, default context 1 triệu token, chỉ dùng 27% FLOPs và 10% KV cache so với V3.2, đồng thời có giá thấp đáng kể so với mọi model frontier khác.
What's new
DeepSeek công bố cùng lúc hai biến thể: V4-Pro (flagship, 1.6T tổng params) và V4-Flash (tối ưu tốc độ/chi phí, 284B). Điểm mới cốt lõi:
- Hybrid Attention — kết hợp Compressed Sparse Attention (CSA) và Heavily Compressed Attention (HCA), cho phép context 1M token chạy được trên cấu hình thực tế.
- Manifold-Constrained Hyper-Connections (mHC) — nâng cấp residual connection giúp tín hiệu lan truyền ổn định hơn trên mô hình siêu lớn.
- Muon optimizer — tối ưu hoá mới cho training, hội tụ nhanh và ổn định hơn AdamW.
- Ba chế độ suy luận: Non-Think, Think High, Think Max (tối thiểu 384K context window để phát huy).
- Huấn luyện trên 32T+ token chất lượng cao, dùng precision hỗn hợp FP4 (expert) + FP8 (các phần còn lại).
Why it matters
V4-Pro là mô hình open-weights lớn nhất từng được công bố với file safetensors khoảng 865GB. Quan trọng hơn, nó kéo frontier-class performance xuống mức giá mà startup và SMB có thể chạy production: V4-Flash rẻ hơn GPT-5.4 Nano, V4-Pro là mô hình frontier-class lớn nhất có giá thấp nhất thị trường hiện tại. Với giấy phép MIT, doanh nghiệp có yêu cầu compliance có thể self-host hoàn toàn — điều mà GPT-5.4 hay Gemini 3.1-Pro không cho phép.
Technical facts
| Thông số | V4-Pro | V4-Flash |
|---|---|---|
| Tổng params | 1.6T | 284B |
| Activated params | 49B | 13B |
| Context window | 1M token | 1M token |
| Dung lượng weights | ~865GB | ~160GB |
| Precision | FP4 + FP8 mixed | FP4 + FP8 mixed |
| License | MIT | MIT |
Benchmark V4-Pro Max công bố chính thức:
- MMLU-Pro: 87.5 · GPQA Diamond: 90.1 · GSM8K: 92.6
- LiveCodeBench: 93.5 (dẫn đầu, trên Gemini 3.1-Pro 91.7 và Claude Opus 4.6 88.8)
- Codeforces rating: 3206 (trên GPT-5.4 3168 và Gemini 3052)
- SWE-Verified: 80.6 · Terminal-Bench 2.0: 67.9 · BrowseComp: 83.4
- MRCR 1M: 83.5 — chứng minh context 1M không phải là con số trên giấy
Comparison
So với DeepSeek V3.2, V4-Pro chỉ dùng 27% FLOPs per token và 10% KV cache ở context 1M — tức là rẻ hơn để phục vụ, không phải chỉ rẻ hơn để gọi API.
So với closed frontier:
| Benchmark | V4-Pro | GPT-5.4 | Gemini 3.1-Pro | Claude Opus 4.6 |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 87.5 | 91.0 | 89.1 |
| LiveCodeBench | 93.5 | — | 91.7 | 88.8 |
| Codeforces | 3206 | 3168 | 3052 | — |
Tổng thể V4-Pro vượt mọi mô hình open-source trên math & coding, chỉ thua Gemini 3.1-Pro ở world knowledge. Các nhà phân tích ước tính V4 cách frontier đóng khoảng 3–6 tháng.
Use cases
- Agentic coding ở quy mô: SWE-Verified 80.6 và Terminal-Bench 67.9 đưa V4-Pro vào nhóm tốt nhất cho agent code — lý tưởng cho công cụ như Cursor, Cline, Aider.
- Xử lý codebase/tài liệu dài: 1M context thật sự dùng được (MRCR 83.5), phù hợp cho phân tích monorepo, review hợp đồng pháp lý, research tổng hợp nhiều paper.
- Reasoning sâu: Think Max mode cho toán, STEM, planning phức tạp.
- Browser & tool-use agents: BrowseComp 83.4 — sẵn sàng cho sản phẩm agent tự động hoá web.
- Self-host cho ngành regulated: tài chính, y tế, chính phủ có thể triển khai on-prem với license MIT, không gửi dữ liệu ra ngoài.
- Workload lớn cần chi phí thấp: V4-Flash $0.14 / $0.28 per 1M tokens — rẻ hơn mọi model cùng phân khúc.
Limitations & pricing
Giá API (USD per 1M tokens):
- V4-Flash: $0.14 input / $0.28 output
- V4-Pro: $1.74 input / $3.48 output
Hạn chế:
- Vẫn trail GPT-5.4 và Gemini 3.1-Pro ở vài benchmark agentic và world knowledge.
- Cải thiện là tăng trưởng, không phải đột phá kiến trúc.
- Self-host V4-Pro cần stack multi-GPU nghiêm túc (865GB weights), không phải ai cũng chạy được tại nhà.
- Think Max mode yêu cầu context window tối thiểu 384K.
- API
deepseek-chatvàdeepseek-reasonercũ sẽ bị ngừng hoàn toàn từ 2026-07-24 15:59 UTC — ai đang dùng phải migrate sangdeepseek-v4-prohoặcdeepseek-v4-flashtrước hạn.
What's next
Bản phát hành hôm nay vẫn được gắn nhãn Preview; phiên bản final V4 và có thể là V4-Reasoner chuyên biệt sẽ theo sau trong những tuần tới. API đã tương thích sẵn với OpenAI ChatCompletions và Anthropic API — chỉ cần đổi model name, không phải sửa code. Trọng số và tech report đã lên HuggingFace và ModelScope, chat web/app đã bật chế độ Expert và Instant tương ứng với hai biến thể.
Nguồn: HuggingFace model card, DeepSeek API docs, Simon Willison, CNBC.

