
- Google vừa đưa Gemini Embedding 2 lên general availability trên Gemini API và Vertex AI.
- Đây là embedding model natively multimodal đầu tiên của Google — cho phép gộp text, ảnh, video, audio, PDF vào cùng một không gian vector 3072 chiều.
- MTEB English 68.32 (+5.09 biên), MTEB Code 84.0, dẫn đầu video retrieval.
TL;DR
- Gemini Embedding 2 vừa lên GA trên Gemini API và Vertex AI, sau 6 tuần ở public preview (10/3/2026).
- Là embedding model natively multimodal đầu tiên của Google: text, ảnh, audio, video và PDF cùng chia một không gian vector 3072 chiều.
- Dẫn đầu MTEB English (68.32, biên +5.09), MTEB Multilingual 69.9, MTEB Code 84.0, và áp đảo các đối thủ trên video retrieval.
- Giá: $0.20 / 1M tokens cho text, giảm 50% với Batch API. Ảnh, audio, video có bảng giá riêng.
- Context window 8192 tokens (gấp 4× so với
gemini-embedding-001), hỗ trợ Matryoshka Representation Learning xuống đến 128 chiều.

What's new
Gemini Embedding 2 khác hoàn toàn với gemini-embedding-001 (GA tháng 7/2025) ở một điểm then chốt: nó là natively multimodal. Thay vì chạy CLIP cho ảnh, Whisper + text-embedding cho audio, một mô hình khác cho video rồi cố gắng hợp nhất các không gian vector, bạn gọi một API duy nhất và nhận về một vector 3072 chiều — bất kể input là text, JPEG, MP4, WAV, hay PDF.
Một request có thể chứa tối đa 6 ảnh, video ≤120 giây, audio native (không cần transcription), và PDF ≤6 trang. Text lên đến 8192 tokens — gấp 4 lần bản trước. Output hỗ trợ Matryoshka Representation Learning, cho phép cắt ngắn vector xuống bất kỳ mức nào từ 128 đến 3072 chiều; Google khuyến nghị 768 là điểm cân bằng chi phí/chất lượng.
Why it matters
Với enterprise đang vật lộn để dựng multimodal RAG, câu chuyện trước đây là duy trì 3–4 pipeline embedding song song — một cho text, một cho ảnh, một cho audio, và một layer mapping để kéo các không gian vector khác nhau về gần nhau. Gemini Embedding 2 xoá bỏ toàn bộ tầng đó. Bạn index một lần, query một lần, kết quả trả về có thể là bất kỳ modality nào.
Điều này mở ra các truy vấn kiểu cross-modal mà trước đây khó làm: query bằng text → match frame video; query bằng ảnh sản phẩm → match đoạn review trong PDF; query bằng đoạn audio → match tài liệu text. Tất cả trong một vector DB duy nhất.
Technical facts
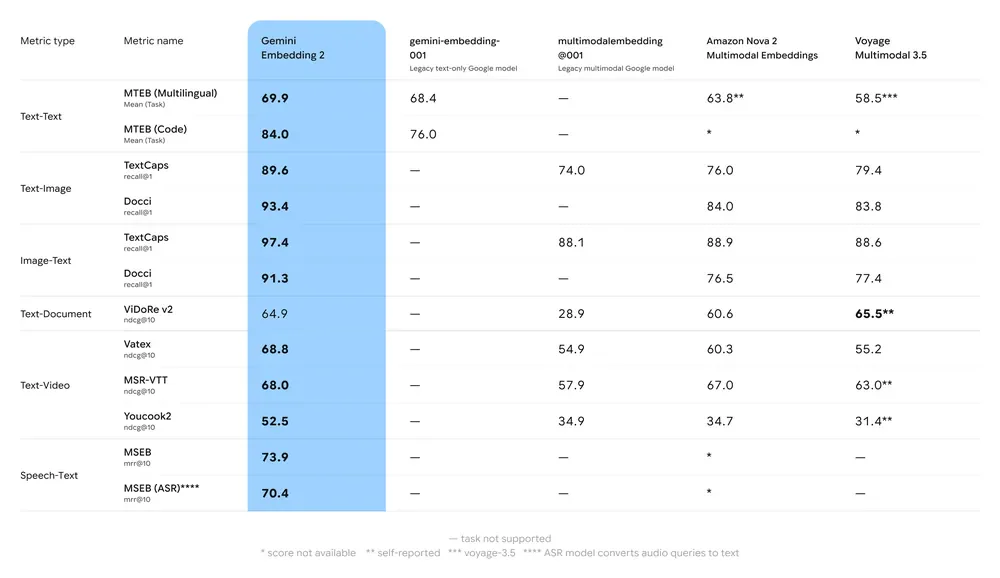
Dữ liệu benchmark Google công bố cho thấy Gemini Embedding 2 dẫn đầu gần như mọi hạng mục:
| Benchmark | Gemini Embedding 2 | gemini-embedding-001 | Amazon Nova 2 | Voyage 3.5 |
|---|---|---|---|---|
| MTEB Multilingual | 69.9 | 68.4 | 63.8 | 58.5 |
| MTEB Code | 84.0 | 76.0 | — | — |
| TextCaps (Text→Image) | 89.6 | — | 76.0 | 79.4 |
| Docci (Text→Image) | 93.4 | — | 84.0 | 83.8 |
| Vatex (Text→Video) | 68.8 | — | 60.3 | 55.2 |
| YouCook2 (Text→Video) | 52.5 | — | 34.7 | 31.4 |
Pricing & availability
Giá là nơi câu chuyện phân nhánh theo modality:
| Modality | Standard / 1M tokens | Batch API |
|---|---|---|
| Text | $0.20 | $0.10 |
| Images | $0.45 | $0.225 |
| Audio | $6.50 | $3.25 |
| Video | $12.00 | $6.00 |
Nếu chỉ làm text-only, OpenAI text-embedding-3-large ($0.13/1M) vẫn rẻ hơn và đủ tốt cho nhiều workload. Nhưng nếu cần multimodal, không có mô hình nào tương đương trong một API call duy nhất — đó là lý do Google thu phí cao hơn cho text: bạn trả giá cho sự thống nhất của không gian vector.
Use cases
- Multimodal RAG cho knowledge base doanh nghiệp: gộp docs, screenshot, diagram, video demo vào cùng một index.
- Video asset discovery: studio và marketer tìm clip theo nội dung (“hoàng hôn trên biển, cặp đôi đi dạo”) thay vì keyword tag.
- Legal & compliance search: query text → match scan PDF, biểu đồ, phụ lục.
- E-commerce visual search: upload ảnh sản phẩm → retrieve item tương tự + mô tả + clip review.
- Data stack consolidation: thay 3–4 embedding pipeline bằng một model call — giảm cost infra và loại bỏ vấn đề lệch không gian vector.
Limitations & gotchas
- Video đắt: $12/1M tokens; 1 phút video có thể tốn hàng chục nghìn tokens — workload scale lớn cần cân nhắc Batch API.
- Text-only thì không rẻ nhất: $0.20/1M so với $0.02/1M của
text-embedding-3-small— chênh 10×. Chỉ đáng dùng khi thực sự cần multimodal. - Limits per request: 6 ảnh/request, video ≤120 giây, PDF ≤6 trang — dữ liệu dài cần chunk.
- Migration từ 001: dimension mặc định giữ 3072 nhưng semantic space khác, phải re-embed toàn corpus.
- Rollout theo region: Gemini API đã GA toàn cầu, một số region Vertex AI còn đang mở dần.
What's next
Google đánh tín hiệu sẽ mở rộng về fine-tuning, domain-specific variants (legal, medical, code), và tối ưu pricing cho per-modality — hy vọng giảm phần audio/video vốn đang là rào cản cho adoption. Integrations sẵn có với LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB, Vector Search nên team có thể bật thử mà không cần viết lại pipeline.
Nếu bạn đang xây multimodal RAG hoặc đang chạy 2+ embedding model trong production, Gemini Embedding 2 đáng POC ngay tuần này — chạy song song với stack hiện tại, so retrieval quality trên chính data của bạn, rồi quyết định.
Nguồn: blog.google, Google Developers Blog, Gemini API docs, TokenCost.


