
- Nanonets just open-sourced NanoIndex, an agentic RAG framework with no vector DB, no embeddings, no chunk tuning — powered by the #1 OCR model (OCR-3).
- It hits 94.5% on FinanceBench and 96% on legal docs, with pixel-level citations down to the bounding box.
TL;DR
Nanonets dropped two things in early April 2026: OCR-3, a 35B Mixture-of-Experts OCR model that took #1 on every major OCR benchmark, and NanoIndex, an open-source vectorless agentic RAG framework built on top of it. No vector DB. No embeddings. No chunk size tuning. Just pip install nanoindex and a PDF. The kicker: 94.5% on FinanceBench (84 SEC 10-K filings, avg 143 pages), 96% on DocBench Legal, and citations down to the exact pixel on the page.

What's new
If you've ever tried to run RAG on a 150-page SEC filing, you know the pain. Chunking shreds the document structure. Tables get sliced mid-row. Cross-references vanish across chunk boundaries. Your similarity search returns five chunks when the answer needed eight. Citations, when you get them, are a page number and a prayer.
Nanonets calls this "the #1 reason RAG pipelines fail" — and NanoIndex is their fix.
- Single OCR pass using Nanonets OCR-3 → extracts structured markdown, hierarchy, tables, and bounding boxes.
- Deterministic tree builder turns the output into a navigable document tree (200–500 nodes, 8+ levels deep). Zero LLM calls at this stage.
- Entity graph captures companies, metrics, legal references, and their relationships in the same single API call — no separate NER pipeline.
- LLM agent navigates the tree like a human analyst: reads the outline, drills into relevant branches, follows cross-references through the graph, returns cited answers.
- Pixel-level citations point to the exact bounding box on the page. You can literally draw a rectangle on the UI showing where every claim came from.
Why it matters
Vector similarity measures word overlap, not how information connects. That's fine for blog posts. It's catastrophic for financial filings, legal contracts, or research papers where meaning lives in the structure — footnotes that modify tables, Section 15.2 referencing Section 2.5(b), multi-page exhibits attached to the main narrative.
NanoIndex replaces the entire chunk-and-embed stack with a structural tree and an entity graph. You stop hoping retrieval finds the right chunks. The agent navigates to them.
Technical facts
Nanonets OCR-3 is a 35-billion-parameter Mixture-of-Experts visual language model, trained on 11 million documents in under a month. MoE activates only 2–3 expert sub-networks per token, so despite being bigger than OCR-2, inference is 2× faster. The API exposes five endpoints — /parse, /extract, /split, /chunk, /vqa — and every extraction ships with bounding boxes and confidence scores.
OCR-3 benchmark scores (OCR-3 vs. notable competitors on the olmOCR benchmark):
| Model | olmOCR | OmniDocBench | Notes |
|---|---|---|---|
| Nanonets OCR-3 | 87.4 | 90.5 | #1 IDP Leaderboard |
| Chandra OCR 2 | 85.9 | 85.5 | — |
| Mistral OCR 3 | 81.7 | 85.3 | — |
| GPT-5.4 | 81.0 | 85.3 | General VLM |
| Gemini 3.1 Pro | 79.6 | 85.3 | General VLM |
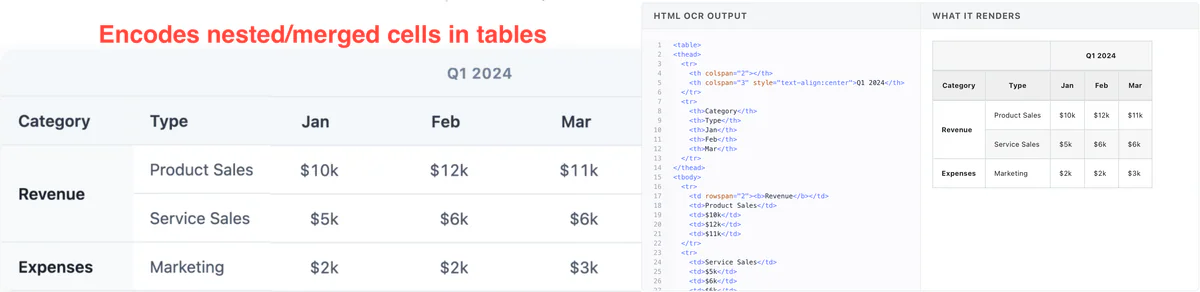
Complex tables stay intact — rowspan, colspan, and nested structure are preserved in the output:
Comparison — NanoIndex vs chunk-and-embed
On FinanceBench (84 dense SEC 10-K filings, 150 questions, Claude Sonnet 4.6 as reasoning LLM):
| Approach | FinanceBench accuracy |
|---|---|
| Chunk + embed | 65% |
| Chunk + reranker | 78% |
| NanoIndex (fast mode, 2 LLM calls) | 89% |
| NanoIndex (agentic mode) | 95% (97% on SEC 10-K) |
And the structural differences that drive that gap:
| Axis | Traditional RAG | NanoIndex |
|---|---|---|
| Document structure | Destroyed by chunking | Preserved as navigable tree |
| Cross-references | Lost across chunk boundaries | Resolved as graph edges |
| Financial tables | Split mid-row | Extracted with headers & rows |
| Multi-section queries | Hope retrieval finds all chunks | Agent navigates to each section |
| Citations | Page number at best | Pixel-level bounding boxes |
| Setup complexity | Vector DB + embedding model + chunk tuning | pip install nanoindex |
Use cases
Three lines of Python to go from PDF to cited answers:
from nanoindex import NanoIndex
ni = NanoIndex(llm="anthropic:claude-sonnet-4-6", financial_doc=True)
tree = ni.index("amazon_10k.pdf")
answer = ni.ask("What was the operating margin in FY2019?", tree)
# "Operating margin was 5.2% ($14.5B / $280.5B)"
# Citations: [Results of Operations, p.40-41]- Financial analysis — 94.5% on FinanceBench. 149 of 150 questions had the correct data retrieved from the tree (99.3% retrieval accuracy).
- Legal — 96% on DocBench Legal (51 court filings, avg 54 pages). Section 15.2 references Section 2.5(b)? A graph edge is created automatically and the agent follows it.
- Healthcare & insurance — 90.1% on HealthcareBench across clinical notes, discharge summaries, lab reports, EOBs, and prior-auth forms.
- Research & multi-doc wikis — NanoIndex calls out a "Karpathy-inspired LLM wiki" pattern: self-validating trees + entity graphs across a whole document corpus, not just one PDF.
Limitations & pricing
NanoIndex is Apache 2.0 on GitHub and PyPI (pip install nanoindex, current v0.4.0, Python 3.10+). You bring your own keys:
- Nanonets OCR-3 API for parsing: first 10,000 pages free, then $0.01/page (grab a key at docstrange.nanonets.com/app).
- LLM key for the agent: OpenAI, Anthropic, Google, or any OpenAI-compatible endpoint (Ollama, vLLM, Together).
Caveats worth knowing:
- There's a PyMuPDF fallback if you don't want to call the API, but you lose heading detection and hierarchy — Nanonets explicitly recommends it only for quick experiments.
- OCR-3 caps usage at 1280 tokens per image for predictable latency.
- Complex financial tables sometimes need
repetition_penalty=1to stop VLM repetition.
What's next
NanoIndex shipped its 0.4.0 release on Apr 12, 2026, only nine days after the first PyPI push. Nanonets has also teased a full-length technical blog on OCR-3's training methodology — frozen backbone layers, EWC regularization, 15% replay buffers, gradient checkpointing, mixed-precision training — that should drop soon. Open-weight variants (Nanonets-OCR-s 3B, OCR2-3B, OCR2-1.5B-exp) are already on Hugging Face for self-hosted setups.
If you've ever argued with a chunk size, this is the most interesting RAG release of the year. Stop chunking. Start understanding.
Nguồn: Nanonets Research, NanoIndex, PyPI, @ErickSky.

