
TL;DR
Ngày 24/04/2026, DeepSeek thả V4 Preview gồm Pro (1.6T/49B active) và Flash (284B/13B active), cả hai 1M context, MIT license. Một ngày sau, dev @0xSero chạy được V4-Flash uncompressed, đúng cấu hình DeepSeek benchmark, trên 4× NVIDIA RTX 6000 Pro (48GB/card, tổng 192GB VRAM). Kết quả: 38.6 tok/s decode batch 1, 2000 tok/s prefill, TTFT < 1 s, 8 session song song, 400k context. Đây là cột mốc: frontier model đầu tiên indie hacker có thể host fullspec tại nhà, không cần datacenter H200.
Có gì mới
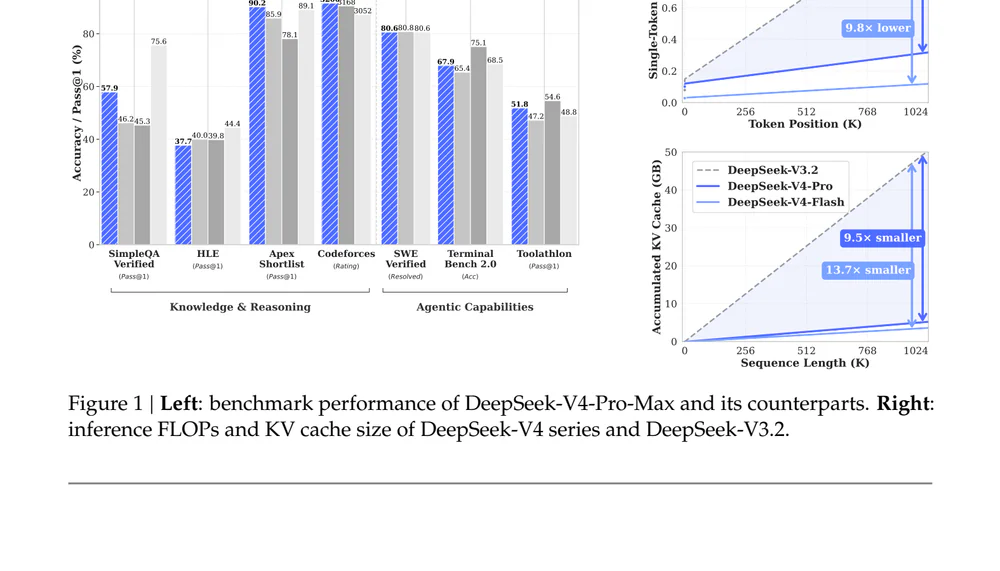
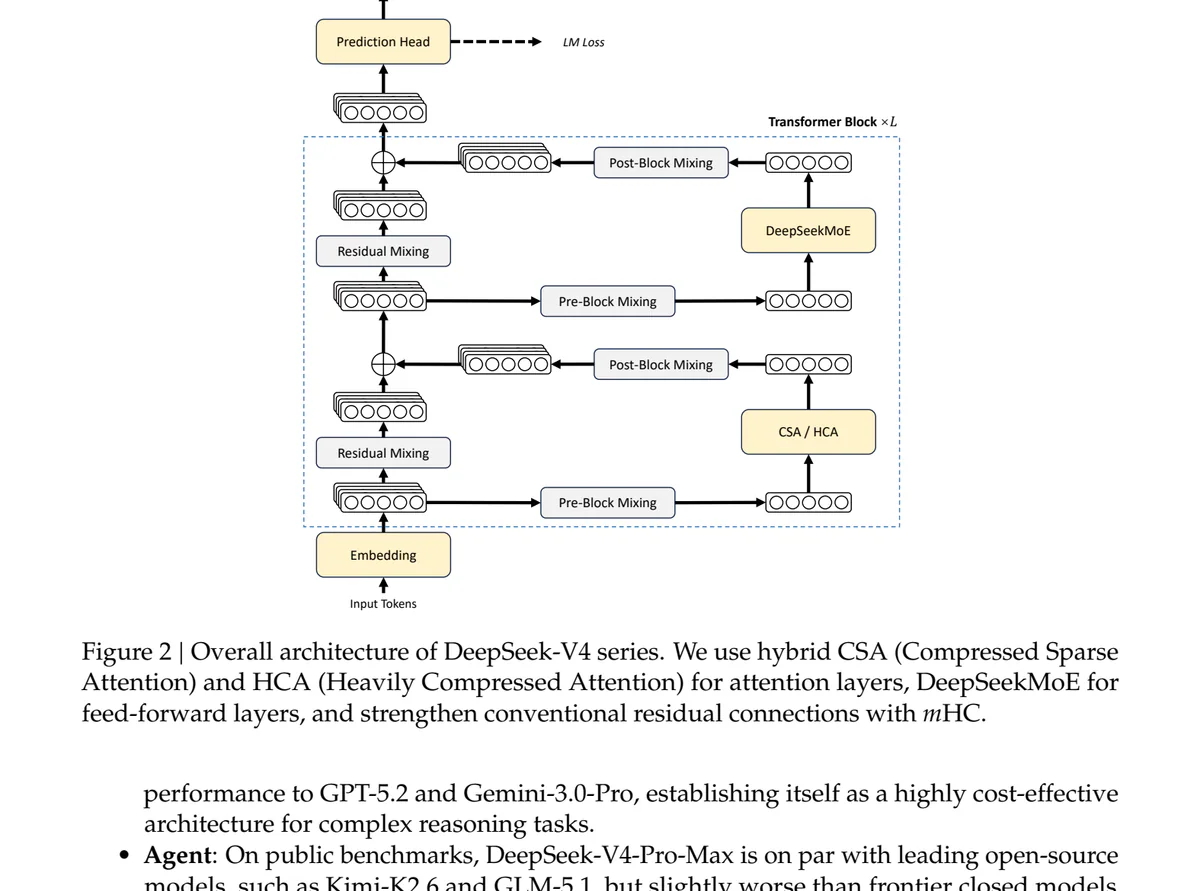
V4 không chỉ là cập nhật benchmark. Cốt lõi là Hybrid Attention Architecture — kết hợp Compressed Sparse Attention (CSA) và Heavily Compressed Attention (HCA) — xử lý long-context ở chi phí rẻ hơn nhiều lần so với kiến trúc cũ. Ở mức 1M token, V4-Flash chỉ ngốn 10% số FLOPs/token và 7% KV cache so với V3.2. So với grouped-query attention chuẩn bfloat16, KV cache của V4 chỉ bằng ~2%.
Đi kèm là 3 nâng cấp agent-centric:
- Interleaved thinking: reasoning trace giờ được giữ xuyên suốt qua các turn của user khi có tool call — trước đây reasoning bị xoá mỗi khi user gửi message mới, phá chain-of-thought của agent dài hơi.
- XML tool-call schema với token đặc biệt
|DSML|, tách string param khỏi JSON structured param — diệt sạch lỗi escape JSON-in-string mà mọi agent framework từng khốn đốn. - Ba mức reasoning: Non-think, Think High, Think Max (system prompt đặc biệt). Max thường chỉ cách Pro vài điểm benchmark.
Vì sao đáng chú ý
Pre-V4, muốn chạy frontier open-weights không nén tại local: tối thiểu 1× H200 141GB (~$30k) hoặc 2× A100 80GB (~$30k nữa) — chưa kể server + RAM. RTX 6000 Pro mới (Blackwell, 96GB) hoặc RTX 6000 Ada (48GB) là dòng prosumer workstation, nhiều indie dev và studio có sẵn cho rendering/ML.
4 card RTX 6000 Pro = 192GB VRAM, vừa đủ cho checkpoint FP4+FP8 ~158GB cộng KV cache cho 400k context và 8 session. Throughput 38.6 tok/s per session và 2000 tok/s prefill đủ phục vụ một team nhỏ hoặc app production low-traffic. Cùng lúc, API Flash giá $0.14/$0.28 per 1M tokens — ai không muốn host cũng có fallback.
Số liệu kỹ thuật
| Thông số | V4-Flash | V4-Pro |
|---|---|---|
| Total params | 284B | 1.6T |
| Active params/token | 13B | 49B |
| Context window | 1M tokens | 1M tokens |
| Checkpoint size (FP4+FP8) | ~158 GB | ~865 GB |
| Pre-training tokens | 32T | 32T |
| API throughput | 83.5 tok/s | — |
| API TTFT | 1.05 s | — |
| AA Intelligence Index | 47 | 52 |
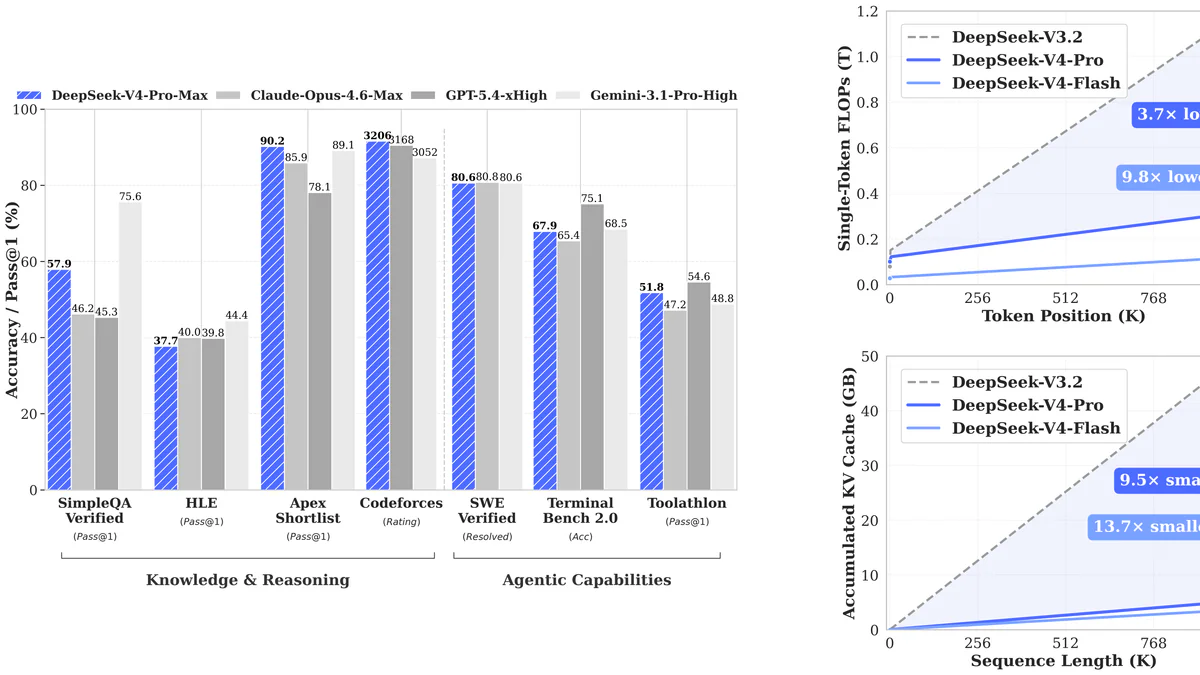
Benchmark (Flash Max vs Pro Max): MMLU-Pro 86.2 vs 87.5, LiveCodeBench 91.6 vs 93.5, GPQA Diamond 88.1 vs 90.1, SWE-bench Verified 79.0 vs 80.6, HMMT 2026 Feb 94.8 vs 95.2, Codeforces rating 3052 vs 3206. Khoảng cách thường chỉ 1–2 điểm; Flash chỉ tụt xa ở Terminal Bench 2.0 (56.9 vs 67.9) — đúng như DeepSeek thừa nhận: Pro vẫn hơn ở agentic phức tạp nhất.
So kè frontier
Artificial Analysis Intelligence Index (24/04/2026): GPT-5.5 xhigh 60 · Claude Opus 4.7 max 57 · Gemini 3.1 Pro 57 · GPT-5.4 xhigh 57 · DeepSeek V4-Pro Max 52 · DeepSeek V4-Flash Max 47. DeepSeek tự thừa nhận tụt 3–6 tháng sau GPT-5.4 / Gemini 3.1-Pro — phát biểu hiếm thấy, nhưng khớp thực tế.
Giá API càng ấn tượng hơn:
| Model | Input $/M | Output $/M |
|---|---|---|
| DeepSeek V4-Flash | $0.14 | $0.28 |
| GPT-5.4 Nano | $0.20 | $1.25 |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 |
| Claude Haiku 4.5 | $1.00 | $5.00 |
| DeepSeek V4-Pro | $1.74 | $3.48 |
| Claude Opus 4.7 | $5.00 | $25.00 |
| GPT-5.5 | $5.00 | $30.00 |
Flash rẻ hơn GPT-5.4 Nano. Output rẻ gấp ~89× so với GPT-5.5. Đồng thời, weights mở — khách hàng không cần tin DeepSeek, cứ self-host là xong.
Use case
- Agent dài hơi: interleaved thinking + XML tool schema giải quyết đúng hai bug tan-chảy-context của mọi coding agent hiện tại. DeepSeek xác nhận V4 tích hợp sẵn với Claude Code, OpenClaw, OpenCode.
- Trợ lý code nội bộ cho repo riêng tư: 2× A100 80GB với 128K context đã đủ phục vụ cả team — không một dòng code nào rời network. Giờ có thêm option 4× RTX 6000 nếu không có datacenter.
- Xử lý tài liệu siêu dài: nạp cả codebase, book, server log vào 1 prompt — không cần RAG pipeline phức tạp.
- Thay thế
deepseek-chat/deepseek-reasoner: hai endpoint cũ retire ngày 24/07/2026, hiện đang route thẳng vào V4-Flash.
Hạn chế & pricing
Flash là text-only — không xử lý ảnh. Ở tác vụ agentic khó nhất (Terminal Bench 2.0, MCPAtlas) Pro vẫn cách biệt rõ. Context 1M đầy đủ vẫn cần nhiều GPU cho KV cache — 4× A100 hoặc 2× H200 là khuyến nghị chính thức của DeepSeek; setup 4× RTX 6000 của @0xSero mới đạt 400k, chưa phải 1M.
API: $0.14 input (cache miss) / $0.028 input (cache hit) / $0.28 output per 1M tokens, 1M context, 384k output. Weights: Hugging Face, MIT license, chạy chính thức với vLLM ≥ 0.9.0.
Cái gì tiếp theo
V4 hiện là preview, chưa phải production final. Benchmark độc lập sẽ kết luận trong vòng 1 tuần — giống kịch bản R1 tháng 01/2025. deepseek-chat và deepseek-reasoner sẽ bị retire hoàn toàn sau 24/07/2026 15:59 UTC, buộc toàn bộ traffic chuyển sang V4.
DeepSeek không hé lộ V5 nhưng khẳng định "longtermism hướng tới AGI". Điều cần theo dõi: liệu community có sớm port quantization int4 ngon hơn để V4-Flash chạy tốt trên 2× RTX 5090 / M5 Ultra không — đó mới là nấc tiếp theo của câu chuyện "frontier model tại nhà".
Nguồn: DeepSeek API Docs, Hugging Face Blog, Simon Willison, Artificial Analysis, TheNextWeb, Codersera, @0xSero trên X.