- Google's open Gemma 4 runs a full coding assistant on your laptop — offline, free, Apache 2.0.
- With LiveCodeBench 80% and Codeforces ELO 2150, it closes the gap to Copilot while keeping every line of code on your machine.
TL;DR
Google DeepMind shipped Gemma 4 on April 2, 2026 under Apache 2.0 — four sizes from 2.3B (E2B, runs in <1.5GB RAM) to 31B dense. Pair it with Ollama + Continue in VS Code and you get chat, inline edit, and tab-autocomplete that rivals GitHub Copilot. Your code never leaves the machine, it works offline, and it costs $0 forever. Copilot Pro is $10/mo, Pro+ is $39/mo — and new signups are paused from April 20, 2026. The timing writes itself.
What's new
Gemma 4 is not a marginal upgrade. On coding benchmarks the 31B model jumps from Gemma 3 27B's 29.1% on LiveCodeBench v6 to 80.0%. Codeforces ELO goes from 110 to 2150 — roughly grandmaster territory. Four sizes ship on day one:
- E2B — 2.3B effective params, runs in <1.5GB via LiteRT with 2/4-bit weights. Phones, Raspberry Pi 5, old laptops.
- E4B — 4.5B effective. Still edge-class, better quality.
- 26B A4B — Mixture-of-Experts, 3.8B active. Fast inference on consumer GPUs.
- 31B Dense — max quality. Fits on one 80GB H100 in bfloat16.
All sizes support a configurable thinking mode, native function calling, structured JSON output, and context windows up to 256K tokens — enough to load most repos. Day-0 integrations cover Ollama, llama.cpp, MLX, vLLM, LM Studio, LiteRT-LM, transformers.js.
Why this rivals Copilot
Until now, the honest answer to "should I use Copilot?" was yes — the UX and context-awareness beat every local setup. Gemma 4 changes the math on four axes:
- Price: Apache 2.0, free commercial use. Copilot costs $10–$39/user/month.
- Privacy: code stays on the laptop. No prompts, diffs, or snippets uploaded to anyone.
- Offline: works on planes, trains, conference wifi, or inside air-gapped enterprise networks.
- Hardware floor: E2B in 1.5GB of RAM means even a five-year-old laptop runs it.
GitHub itself paused new signups for Copilot Pro, Pro+, and the student plan starting April 20, 2026. So for a lot of developers, the question right now isn't "Gemma 4 or Copilot" — it's "Gemma 4 or nothing."
Technical facts
The coding-relevant numbers (vs Gemma 3 27B baseline):
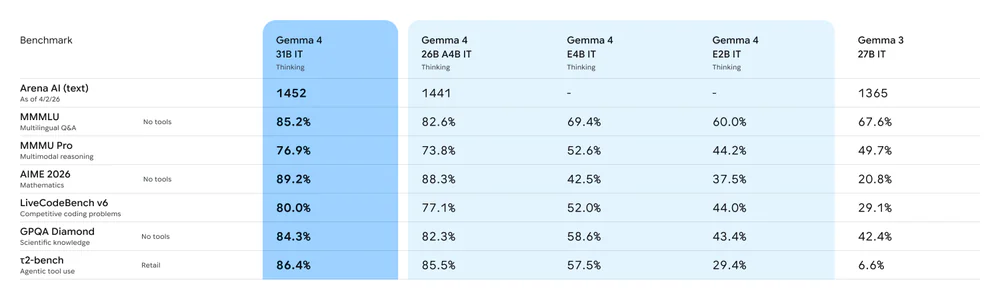
| Benchmark | 31B | 26B A4B | E4B | E2B | Gemma 3 27B |
|---|---|---|---|---|---|
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% | 29.1% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 | 110 |
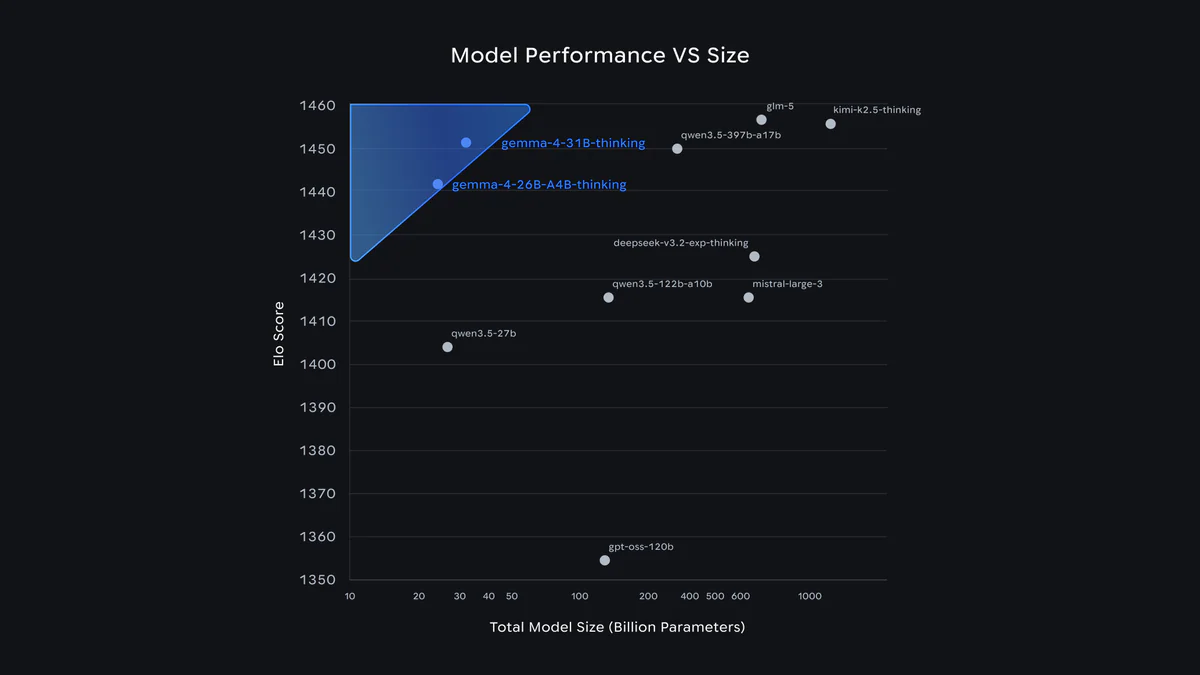
| Arena AI (text) | 1452 | 1441 | — | — | 1365 |
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% | 67.6% |
| τ2-bench (agentic) | 86.4% | 85.5% | 57.5% | 29.4% | 6.6% |
Speed on real hardware: Raspberry Pi 5 CPU gets 133 prefill / 7.6 decode tokens/s. A Qualcomm Dragonwing IQ8 NPU hits 3,700 prefill / 31 decode tokens/s. LiteRT-LM runs 4,000 tokens across 2 skills in under 3 seconds on mobile.
Gemma 4 vs GitHub Copilot
| Gemma 4 (local) | GitHub Copilot | |
|---|---|---|
| Price | Free, Apache 2.0 | Pro $10 / Pro+ $39 / Business $19 / Enterprise $39 per month |
| Where code lives | Your machine | Microsoft / OpenAI servers |
| Offline | Yes | No |
| Min hardware | E2B: ~1.5GB RAM | Any internet-connected device |
| Context window | 128K (E2B/E4B), 256K (26B/31B) | Varies by tier |
| Autocomplete UX | Good via Continue; Copilot still faster & more context-aware across big repos | Best in class |
| Chat, refactor, explain | Competitive | Competitive |
| Agentic tool use | Native function calling + JSON output | Agent mode (premium) |
| Signup | Pull weights | Pro / Pro+ new signups paused since Apr 20, 2026 |
Honest take: Copilot still wins on raw completion speed and cross-workspace context awareness in monster repos. Where Gemma 4 closes the gap hardest is the chat-based flow — explaining code, refactoring, debugging from a stack trace, generating tests. That covers most of what people actually pay Copilot for.
Use cases
- Offline development — planes, trains, rural wifi, sensitive client sites.
- Regulated industries — finance, healthcare, government, defense: code provably never leaves the device.
- Indie hackers — drop a $10–$39/mo subscription. That's $120–$468 a year back in the pocket.
- Old hardware — E2B on a 2019 laptop or Raspberry Pi 5 gives real autocomplete for the first time.
- One-shot scaffolding — "Build me a landing page for X" prompts produce full HTML/CSS/JS in one go.
- Local agents — native function calling + structured JSON makes it a clean LLM backend for custom agent frameworks.

Limitations & setup
It's not all sunshine. Smaller sizes trade a lot of quality: E2B scores 44% on LiveCodeBench vs 80% on the 31B. If you want grandmaster-tier suggestions you need a real GPU (or a beefy Apple Silicon machine — 24GB unified memory handles 26B comfortably). Training cutoff is January 2025, so very new library APIs may be missing — supply them in the prompt.
Setup is a one-time lift: install Ollama, run ollama pull gemma4, install the Continue extension in VS Code, and point it at the local model. The official VS Code integration guide covers the wiring in a few minutes.
What's next
Google's AICore Developer Preview on Android hints at forward-compatibility with Gemini Nano 4, meaning the same on-device pipeline will upgrade later this year. The Gemma 4 Good Challenge on Kaggle will surface community-tuned variants — expect coding-specialist finetunes in the Gemmaverse within weeks.
For now the headline is simple: a free, open, on-device model just became good enough at code that paying monthly for the privilege is no longer the default choice.
Sources: blog.google, Google DeepMind, Gemma 4 model card, Hugging Face, GitHub Copilot plans.

