
- rednote-hilab's dots.ocr packs SOTA OmniDocBench performance into a 1.7B-parameter VLM, outperforming Qwen2-VL-72B and GPT-4o on key OCR benchmarks while running on a single GPU.
TL;DR
dots.ocr is an open-source multilingual document parser from rednote-hilab (Xiaohongshu's research lab). Despite a tiny 1.7B-parameter LLM backbone, it tops OmniDocBench with a 0.125 Overall Edit Distance, beating GPT-4o (0.233) and matching models 10–40× its size. One unified vision-language model handles text, tables, formulas, layout, and reading order in a single pass — no multi-stage pipeline, no closed API, no per-page billing. Weights are free on Hugging Face and serve cleanly through vLLM.
What's new
Most state-of-the-art document parsers fall into two camps: massive closed models like GPT-4o and Gemini 2.5-Pro that you rent by the page, or 70B+ open weights like Qwen2-VL-72B that need a small cluster to serve. dots.ocr flips that trade-off. The architecture pairs a compact 1.7B Qwen2.5 language model with a 1.2B NaViT vision encoder trained at up to 11M-pixel input resolution — roughly 3B params end-to-end, and small enough to fit on a single consumer GPU.
The crucial design choice is unification. Older OCR stacks chain a layout detector (often a YOLO variant), a text recognizer, a table parser, and a formula extractor — four models, four failure modes, four sets of weights to maintain. dots.ocr collapses all of that into one VLM. Switching tasks is a prompt change: prompt_layout_only, prompt_table, prompt_full. No model swap, no orchestration code, no glue scripts.
Why it matters
If you've ever tried to digitize a backlog of PDFs with GPT-4o Vision, you know the pain: per-page API costs that balloon at scale, strict rate limits, and zero data residency for regulated industries. Self-hosted alternatives until now were either weak (Tesseract + layout YOLO stacks that drop tables and break on Asian scripts) or impractical (72B-class models requiring 4× A100s just to load).
dots.ocr lands in the sweet spot. Small enough that a single RTX 4090 or A10 can serve it via vLLM at production throughput, but accurate enough to replace closed APIs for most document workloads. For startups and enterprises that want to own their OCR stack — legal discovery, healthcare records, financial filings — this is the first time the math actually works out.
Technical facts
| Metric (OmniDocBench EN/ZH) | dots.ocr (1.7B) | GPT-4o |
|---|---|---|
| Overall Edit Distance ↓ | 0.125 / 0.160 | 0.233 / — |
| Text Recognition Edit Distance ↓ | 0.032 / 0.066 | higher |
| Table TEDS ↑ | 88.6 / 89.0 | 72.0 |
| Reading Order Edit Distance ↓ | 0.040 / 0.067 | higher |
| Layout Detection F1 ↑ | 0.930 | n/a |
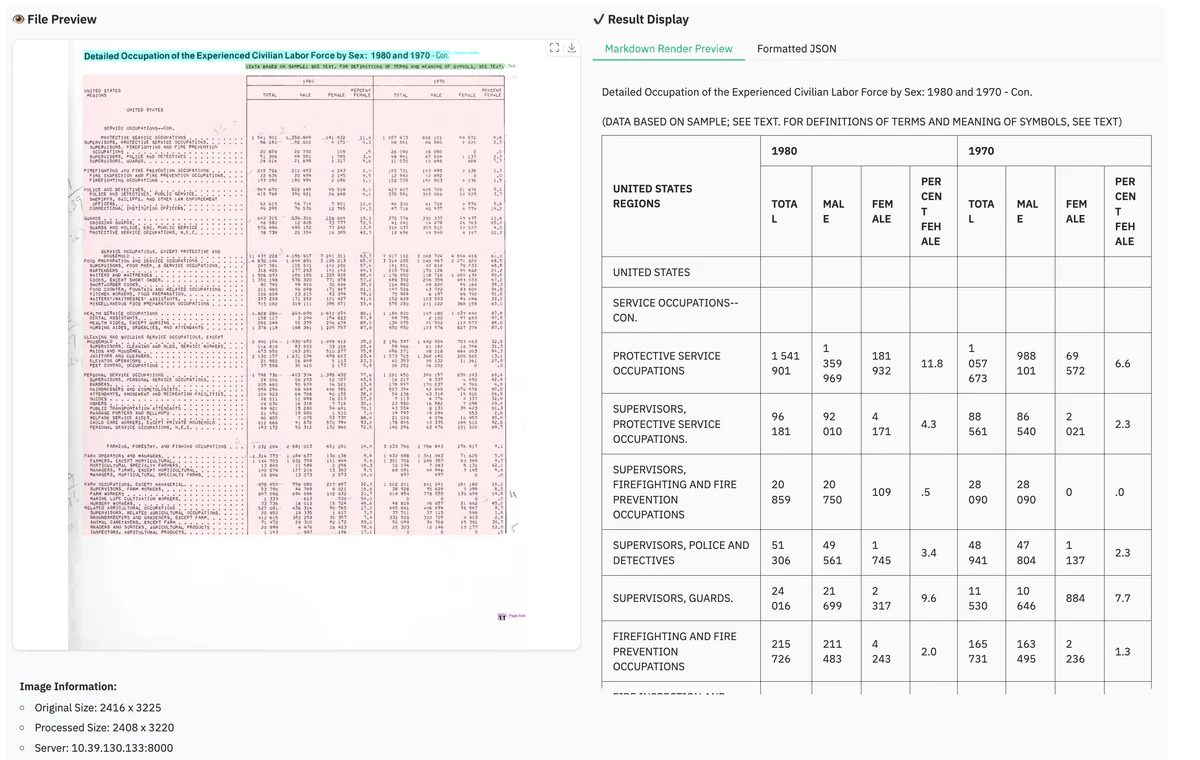
On the broader olmOCR-bench, dots.ocr scores 79.1 ± 1.0 overall — top of the leaderboard for its size class — with 88.3 on tables and 82.4 on multi-column layouts. The training recipe is three-stage pretraining plus supervised fine-tuning on roughly 300K samples blending synthetic data and human-annotated multilingual documents covering 100+ scripts.
Comparison
What makes the comparison brutal for incumbents: dots.ocr matches Doubao-1.5 and Gemini 2.5-Pro on formula recognition while running locally on a single GPU. On layout detection it beats DocLayout-YOLO, a dedicated detector trained for nothing else. On tables, the 16.6-point TEDS gap over GPT-4o (88.6 vs 72.0) is the kind of margin that decides whether a downstream RAG pipeline ships or gets refactored.
The successor dots.mocr (3B params, released March 2026) pushes further — OmniDocBench v1.5 TextEdit Distance drops to 0.031, ReadOrder to 0.029, and a sibling dots.mocr-svg variant adds direct chart-to-SVG generation (Unisvg 0.902, Chartmimic 0.905). The 1.7B version covered here remains the practical choice for most teams: it's smaller, well-tested, and already integrated into the vLLM ecosystem.
Use cases
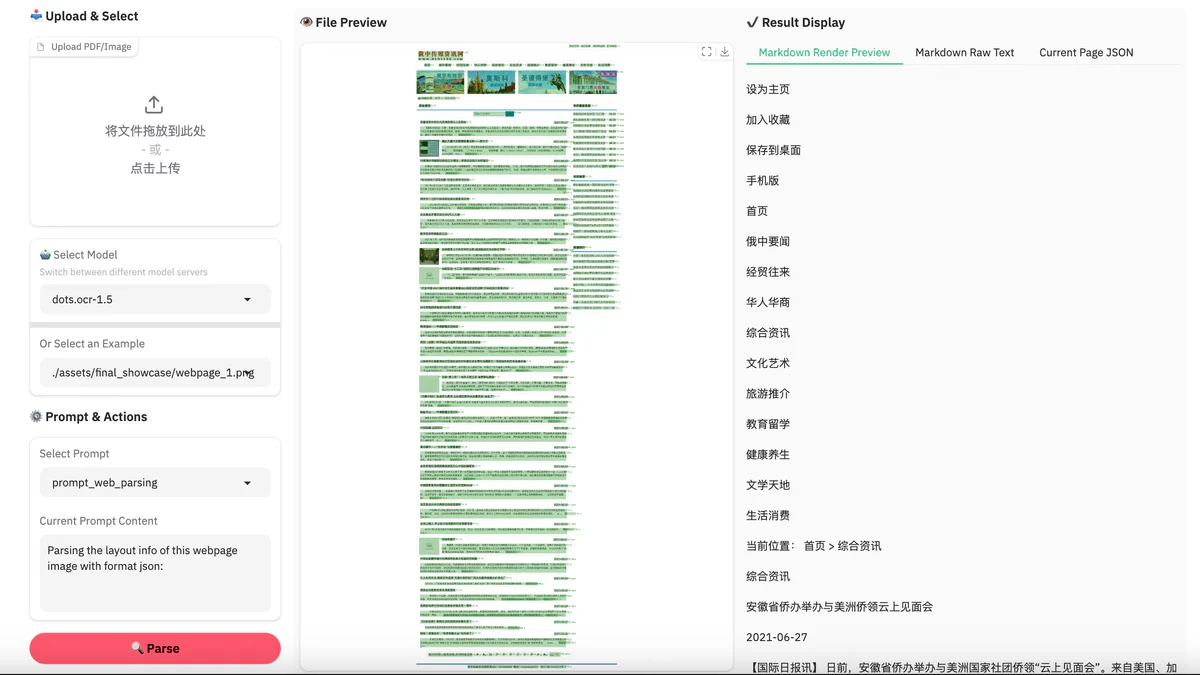
- RAG pipelines that need layout-aware extraction with reading order preserved across multi-column papers and reports
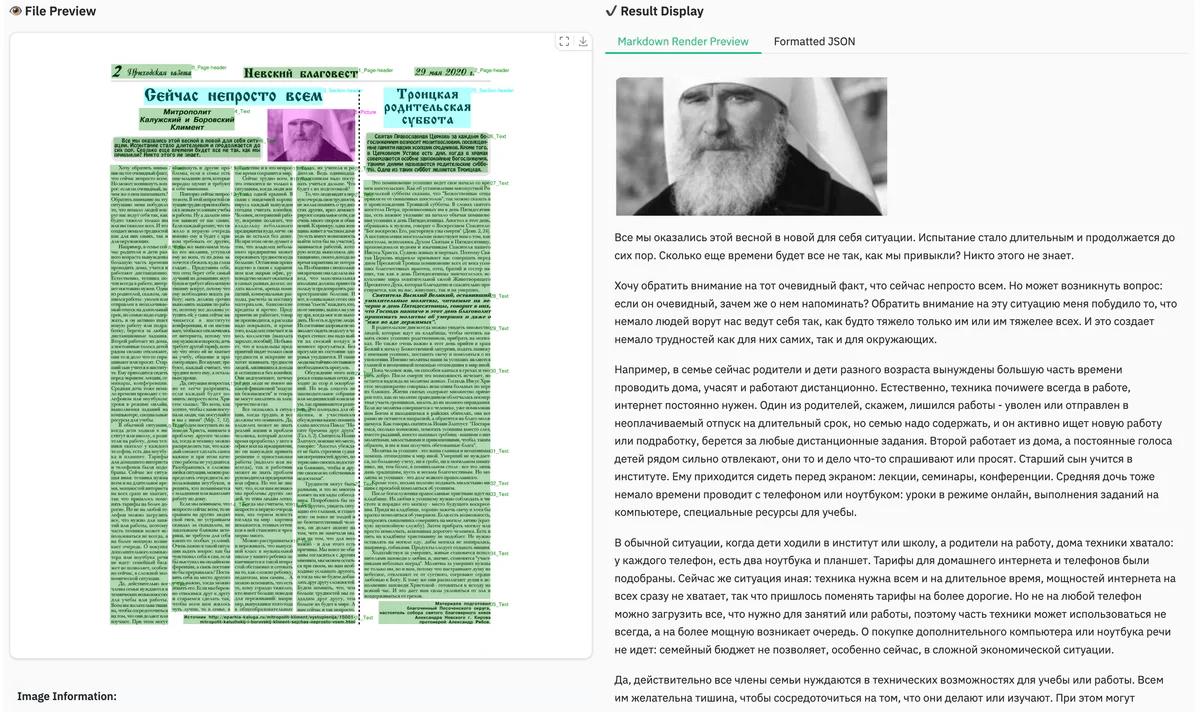
- Multilingual document archives — supports Tibetan, Kannada, Russian, traditional Chinese, and 100+ other scripts that mainstream OCR tools handle poorly
- Self-hosted OCR for regulated industries (legal, healthcare, finance) where source documents can't leave on-prem infrastructure
- Scientific paper parsing with LaTeX formulas and tables intact, ready for downstream literature search or knowledge-graph construction
- Web and UI screen parsing — turn screenshots of dashboards or webpages into structured JSON for agents and automation
- Scene text spotting in natural images for retail, logistics, and accessibility tooling

Limitations & pricing
The model is fully open under the rednote-hilab repo — free to self-host, weights on Hugging Face (rednote-hilab/dots.ocr) under a permissive license. Real-world caveats worth knowing before you commit:
- Not yet optimized for high-throughput batch PDF processing — expect to invest engineering time on queueing and parallelism for large jobs
- Very complex tables (deeply nested headers, merged cells across pages) and dense math formulas can still trip the model up
- Picture/embedded-image extraction is not implemented in the 1.7B version — use dots.mocr-svg if you need chart-to-SVG
- Optimal resolution caps near 11.3M pixels per page; ultra-high-DPI scans should be downsampled first
- vLLM ≥0.11.0 is required for the production-grade serving path; the HF Transformers backend works but is markedly slower
What's next
The published roadmap targets the obvious gaps: better complex-table and formula handling, picture content extraction, and serious throughput improvements for batch PDF jobs. The team is also positioning dots.ocr as the seed of a broader general-purpose perception model — not just OCR but full visual understanding at small scale. For practitioners, the takeaway is that the 70B-or-API duopoly in document AI is over. Try the live demo at dotsocr.xiaohongshu.com or grab the weights from Hugging Face and benchmark against your own docs.
Sources: rednote-hilab/dots.ocr GitHub, Hugging Face model card, OmniDocBench (CVPR 2025).

