
- Alibaba mở mã Qwen3.6-27B — mô hình dense 27B với SWE-bench Verified 77.2, Terminal-Bench 2.0 ngang Claude 4.5 Opus, context 262K (mở rộng 1M), Apache 2.0.
- Nhỏ hơn 14× so với Qwen3.5-397B-A17B nhưng dẫn đầu mọi benchmark coding chính.
TL;DR
Qwen team vừa open-source Qwen3.6-27B — một mô hình dense 27B đa phương thức (text + image + video) với hiệu năng coding ở mức flagship. Điểm cốt lõi: SWE-bench Verified 77.2, Terminal-Bench 2.0 59.3 (ngang Claude 4.5 Opus), context 262K native / ~1M qua YaRN, license Apache 2.0. Đáng nói nhất: nó vượt qua Qwen3.5-397B-A17B — flagship MoE thế hệ trước với 397B params tổng — trên mọi benchmark coding chính, dù nhỏ hơn ~14× về tham số tổng và là dense (mọi param đều active).

What's new
- Dense 27B, không phải MoE — mỗi token đi qua đủ 27B params, không có routing/expert overhead. Phù hợp self-host vì latency dự đoán được.
- Hybrid architecture: 64 layer xen kẽ Gated DeltaNet (linear attention) và Gated Attention, theo pattern 16 × (3 DeltaNet + 1 Attention). Hidden 5,120, FFN 17,408.
- Multimodal natively — vision encoder tích hợp sẵn, xử lý ảnh + video + text trong 1 model. Không cần adapter rời.
- Thinking preservation — chế độ mới giữ lại reasoning context xuyên suốt nhiều turn, cực hợp iterative coding (sửa bug nhiều bước, refactor lớn).
- Multi-Token Prediction (MTP) — train với multi-step MTP, hỗ trợ tốc độ inference cao hơn khi serving framework hỗ trợ.
- Bản FP8 phát hành cùng ngày — VRAM giảm còn ~27GB, vừa khít một H100 hoặc dual-RTX-4090.
Why it matters
Cả ngành đang chuyển sang MoE để tối ưu chi phí inference (DeepSeek V3, Qwen3.5-397B, Llama 4 Scout). Qwen3.6-27B là tuyên bố ngược dòng: dense vẫn còn đất sống nếu kiến trúc được thiết kế đúng. Với một dev solo hoặc team nhỏ, 27B dense có ba lợi thế thực tế so với MoE 35B-A3B sibling: (1) dễ deploy hơn — không cần expert routing đặc biệt, (2) latency ổn định hơn cho agentic workflow nhiều bước, (3) thắng ở benchmark coding chính. Thêm vào đó, license Apache 2.0 đầy đủ — bạn có thể fine-tune, redistribute, đóng vào sản phẩm thương mại mà không cần email Alibaba.
Technical facts
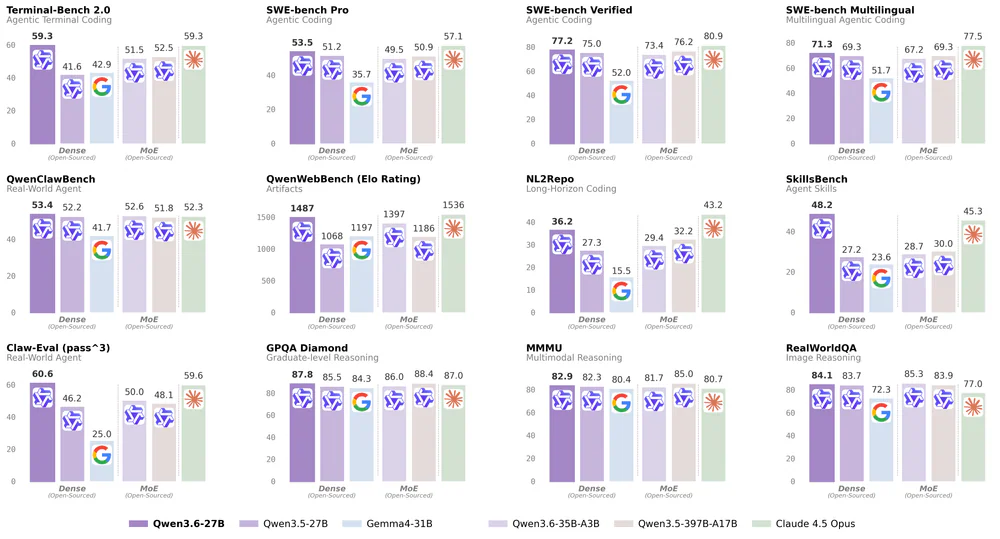
| Benchmark | Qwen3.6-27B | Qwen3.5-27B | Qwen3.5-397B-A17B | Claude 4.5 Opus |
|---|---|---|---|---|
| SWE-bench Verified | 77.2 | 72.4 | 76.2 | 80.9 |
| SWE-bench Pro | 53.5 | 49.5 | 52.5 | 57.1 |
| Terminal-Bench 2.0 | 59.3 | 41.6 | 51.1 | 59.3 |
| SWE-bench Multilingual | 71.3 | 51.7 | 69.3 | 77.5 |
| SkillsBench Avg5 | 48.2 | 27.6 | 30.0 | 45.3 |
| GPQA Diamond | 87.8 | — | 86.1 | 87.0 |
| MMMU | 82.9 | — | — | 80.7 |
| RealWorldQA | 84.1 | — | 83.7 | 77.0 |
Lưu ý: Qwen3.6-27B thắng Claude 4.5 Opus trên GPQA Diamond, MMMU, RealWorldQA — và ngang trên Terminal-Bench 2.0. Trên SWE-bench Verified vẫn kém Claude ~3.7 điểm, nhưng đây là model open weight chạy on-prem được, so với một frontier proprietary model. Trade-off rõ ràng.
Comparison vs MoE sibling
Qwen3.6-27B đứng ở đâu so với Qwen3.6-35B-A3B (MoE 35B tổng / 3B active) — open-source song hành ra tuần trước?
| Tiêu chí | Qwen3.6-27B (Dense) | Qwen3.6-35B-A3B (MoE) |
|---|---|---|
| SWE-bench Verified | 77.2 | 73.4 |
| Terminal-Bench 2.0 | 59.3 | 51.6 |
| VRAM (FP16) | ~54GB | ~70GB tổng, ~6GB active |
| Inference cost / token | Cao hơn (mọi param active) | Thấp hơn nhiều (3B active) |
| Latency cho agentic loop | Ổn định, dự đoán được | Có biến động routing |
| Phù hợp | On-prem dev tools, single-GPU serving | High-throughput batch, laptop-class qua quantize |
Tóm: chọn 27B nếu bạn cần điểm cao nhất + latency ổn; chọn 35B-A3B nếu bạn cần serve nhiều user song song với chi phí token thấp.
Use cases
- Self-hosted coding copilot cho team có compliance không cho dùng API ngoài. SGLang hoặc vLLM trên một H100 là đủ.
- Agentic CLI / IDE plugin — Terminal-Bench 59.3 + thinking preservation = chuỗi sửa lỗi nhiều bước không bị mất context.
- Long-context code review — 262K native cover trọn một monorepo nhỏ trong 1 prompt; YaRN mở rộng tới 1M cho monorepo lớn.
- Multimodal builder — agent đọc screenshot UI, video demo, mockup design rồi sinh code — không cần stack vision riêng.
- Apple Silicon power-user — qua MLX, chạy được trên Mac Studio M2 Ultra (qua FP8 hoặc quantize thêm).
Limitations & pricing
- Phần cứng: dense nghĩa là không có shortcut. FP16 cần ~54GB VRAM, FP8 ~27GB. Không phải mô hình laptop trừ khi quantize xuống Q4 (qua llama.cpp).
- Chi phí: $0 cho weight (Apache 2.0), bạn chỉ trả tiền compute. Không có rate limit, không có data sharing.
- Vision-language strong nhưng không class-leading — vẫn kém các VLM chuyên dụng (GPT-4o, Gemini 2.5 Pro) ở benchmark khó.
- Thinking mode tốn token — budget ~80K max_tokens cho task reasoning phức tạp; đẩy chi phí GPU-hour lên.
- Còn kém Claude 4.5 Opus ở SWE-bench Verified (~3.7 điểm) và SWE-bench Multilingual (~6 điểm) — frontier proprietary vẫn nhỉnh hơn ở coding nguyên bản.
Availability
- HuggingFace: Qwen/Qwen3.6-27B (BF16) và Qwen/Qwen3.6-27B-FP8
- ModelScope: Qwen/Qwen3.6-27B
- Code & deploy: github.com/QwenLM/Qwen3.6 — hỗ trợ SGLang, vLLM, HF Transformers, KTransformers, llama.cpp, MLX
- Try it free: Qwen Chat
What's next
Qwen3.6-27B là mảnh ghép thứ ba của họ Qwen3.6 sau bản proprietary Qwen3.6-Plus (2/4) và MoE Qwen3.6-35B-A3B (16/4). Pattern roadmap rõ: phủ đủ ba mức — frontier API, MoE hiệu quả, dense flagship — trong cùng một thế hệ. Tiếp theo có khả năng cao là biến thể nhỏ hơn (4B/8B dense) cho on-device và bản tinh chỉnh chuyên biệt (coding, math, agentic). Với cộng đồng, đây là khoảnh khắc "open-source coding model thực sự ngang ngửa Claude" trở nên cụ thể chứ không còn là khẩu hiệu.
Nguồn: qwen.ai blog, HuggingFace model card, QwenLM/Qwen3.6, @Alibaba_Qwen.

