
- Alibaba ra mắt Qwen3.6-27B ngày 22/04/2026: dense model 27B mở Apache 2.0, chạy local trên 18GB RAM qua Unsloth Dynamic GGUFs, vượt mô hình tiền nhiệm 397B-A17B trên SWE-bench Verified, SWE-bench Pro, Terminal-Bench 2.0 và SkillsBench.
- Context 262K token, native multimodal, hybrid thinking, hỗ trợ 201 ngôn ngữ.
TL;DR
- Qwen3.6-27B là mô hình dense 27B vừa được Alibaba phát hành ngày 22/04/2026 dưới giấy phép Apache 2.0.
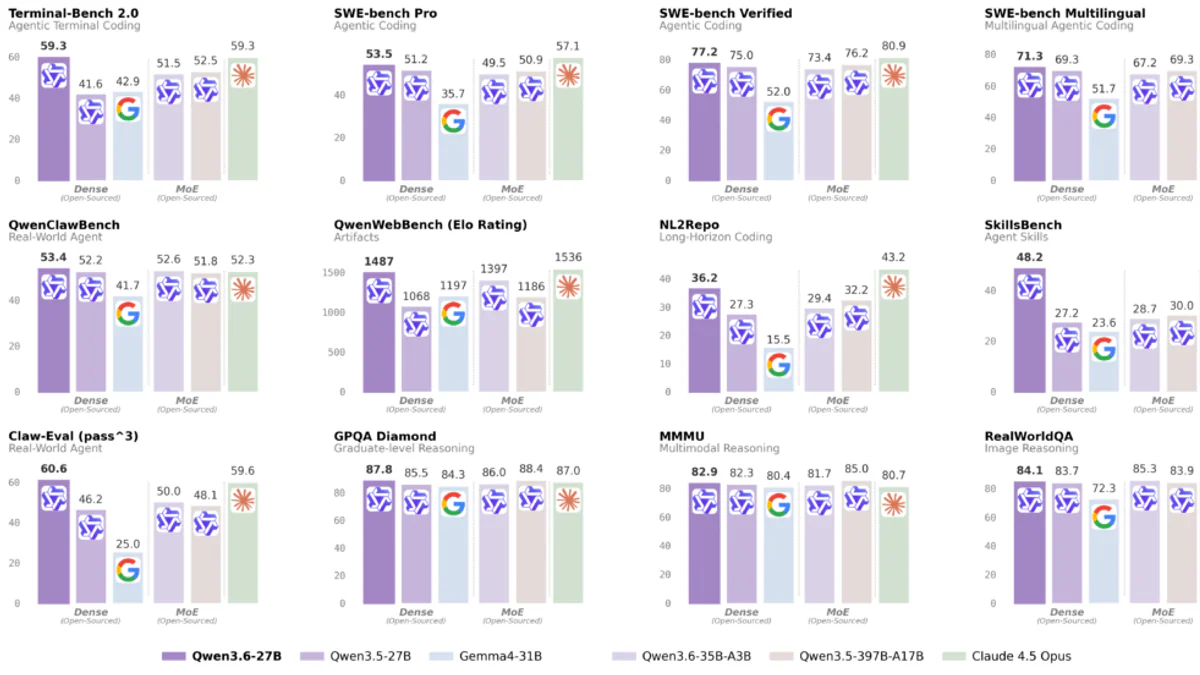
- Vượt Qwen3.5-397B-A17B (flagship MoE thế hệ trước) trên cả 4 benchmark coding chính: SWE-bench Verified 77.2 vs 76.2, SWE-bench Pro 53.5 vs 50.9, Terminal-Bench 2.0 59.3 vs 52.5, SkillsBench 48.2 vs 30.0.
- Chạy local trên 18 GB RAM (4-bit) hoặc thậm chí 15 GB (3-bit) với Unsloth Dynamic GGUFs.
- Native multimodal (text + ảnh + video), context 262K token (mở rộng tới 1M qua YaRN), hybrid thinking với tính năng mới Thinking Preservation.
Có gì mới
Sau khi tung Qwen3.6-35B-A3B (MoE) vào ngày 16/04, Alibaba hoàn thiện gia đình open-weight Qwen3.6 với phiên bản dense 27B. Đây là mô hình đầu tiên trong tier <30B chạm ngưỡng flagship-level agentic coding, một mức trước nay chỉ thuộc về MoE 100B trở lên hoặc các API đóng.
Hai nâng cấp đáng chú ý theo blog phát hành chính thức:
- Agentic Coding: Xử lý workflow front-end và reasoning ở mức repository tốt hơn rõ rệt, đáp ứng phản hồi cộng đồng từ thế hệ Qwen3.5.
- Thinking Preservation: Tùy chọn mới
preserve_thinking=Truegiữ nguyên reasoning trace từ các turn trước trong hội thoại. Trong agent loop, điều này giúp giữ tính nhất quán quyết định, giảm token tiêu hao và tăng hiệu quả KV cache.
Vì sao đáng chú ý
Trên Hugging Face, file weights Qwen3.5-397B-A17B nặng 807 GB. Qwen3.6-27B BF16 chỉ 55.6 GB, và bản Q4_K_XL của Unsloth chỉ 17.6 GB — tức là một MacBook Pro 32 GB unified memory hoặc một GPU 24 GB là đủ chạy. Vậy mà nó vẫn đập được flagship 14× lớn hơn trên các benchmark coding nghiêm túc nhất.
Simon Willison đã test Q4_K_M (16.8 GB) qua llama-server trên Mac và ghi nhận tốc độ generation ~25.57 tokens/s, đủ nhanh cho coding agent thực tế.
Thông số kỹ thuật
| Hạng mục | Qwen3.6-27B |
|---|---|
| Parameters | 27B (dense, không phải MoE) |
| Layers | 64 |
| Hidden dim | 5,120 |
| Block layout | 16 × (3 × Gated DeltaNet → FFN, 1 × Gated Attention → FFN) |
| Context length | 262,144 native (mở rộng ~1,010,000 qua YaRN) |
| Modalities | Text + Image + Video (vision encoder tích hợp) |
| Languages | 201 |
| License | Apache 2.0 (commercial OK, fine-tune OK) |
So sánh benchmark
Bảng dưới đây trích từ ảnh benchmark chính thức Qwen công bố. Dense 27B so với MoE 397B-A17B (tổng 397B / active 17B):
| Benchmark | Qwen3.6-27B | Qwen3.5-397B-A17B | Chênh lệch |
|---|---|---|---|
| SWE-bench Verified | 77.2 | 76.2 | +1.0 |
| SWE-bench Pro | 53.5 | 50.9 | +2.6 |
| Terminal-Bench 2.0 | 59.3 | 52.5 | +6.8 |
| SkillsBench | 48.2 | 30.0 | +18.2 |
| NL2Repo (long-horizon coding) | 36.2 | 32.2 | +4.0 |
| QwenWebBench (Elo) | 1487 | 1186 | +301 |
Điểm gây sốc nhất là SkillsBench +18.2 điểm — benchmark chuyên đo kỹ năng agent. Trên một số phép đo tổng quát (MMMU, GPQA Diamond), Qwen3.6-27B vẫn đứng top nhóm open-weight, vượt cả Gemma4-31B của Google và bám sát Claude 4.5 Opus.
Use case thực tế
- Local coding agent: Drop-in cho OpenAI Codex CLI, Claude Code, OpenCode, Qwen Code — Unsloth GGUFs đã hỗ trợ "developer role" sẵn.
- Agent đa bước: Tool-calling cải thiện ở phần parse nested object; Thinking Preservation giữ ngữ cảnh suy luận xuyên turn.
- Repo-level reasoning: 262K context đọc trọn codebase trung bình trong một prompt.
- Multimodal dài hơi: Hiểu video hàng giờ khi set
longest_edge= 469,762,048 (~224K video tokens). - Privacy-first enterprise: Apache 2.0 + chạy on-device → giữ codebase độc quyền không phải gửi lên cloud API.
Hạn chế & chi phí
- Miễn phí, open-weight, Apache 2.0.
- Yêu cầu RAM tối thiểu: 15 GB (3-bit), 18 GB (4-bit khuyên dùng), 24 GB (6-bit), 30 GB (8-bit), ~55 GB (BF16).
- Chưa chạy được trên Ollama vì có file
mmprojvision tách rời. Dùng llama.cpp / llama-server / Unsloth Studio / MLX thay thế. - Tránh CUDA 13.2 — sinh output rác, NVIDIA đang fix. Pin CUDA ≤ 13.1.
- Quant khuyên dùng:
UD-Q4_K_XL(17.6 GB) cân bằng tốc độ-độ chính xác, chạy mượt trên Mac 24-32 GB hoặc GPU 24 GB.
Tiếp theo là gì
Alibaba còn 2 biến thể đóng trong family Qwen3.6: Qwen3.6-Plus và Qwen3.6-Max-Preview, hiện chỉ phục vụ qua API Alibaba Cloud Model Studio. Khả năng cao một phiên bản Max open-weight sẽ xuất hiện sau, theo đúng pattern Qwen3.5 (open 397B-A17B sau khi Plus/Max API ra mắt). Tài liệu User Guide chính thức đang "coming soon" trên GitHub repo.
Với độ chín hiện tại, Qwen3.6-27B nhiều khả năng trở thành mặc định cho local coding agent trong vài tuần tới — thay thế Qwen3-Coder-30B và đẩy Llama 3.x ra khỏi ghế "best local for code".
Nguồn: Unsloth GGUF release, Unsloth Docs, QwenLM/Qwen3.6 GitHub, Simon Willison.

