
- Alibaba vừa mở mã nguồn Qwen3.6-35B-A3B dưới giấy phép Apache 2.0: MoE 35B tổng, chỉ 3B active, đa phương thức, context 262K (mở rộng 1M), và chạy được trên MacBook 24GB.
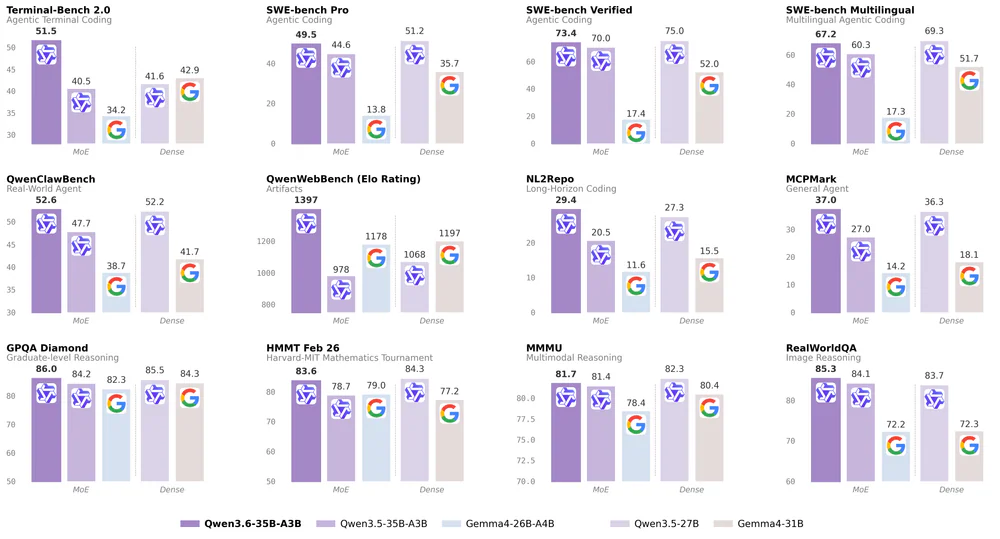
- Trên SWE-bench Verified đạt 73.4, Terminal-Bench 2.0 đạt 51.5 — vượt Gemma 4-31B và bám sát Claude Sonnet 4.5.
TL;DR
Ngày 16/04/2026, Alibaba Qwen team open-source Qwen3.6-35B-A3B dưới giấy phép Apache 2.0 — mô hình đầu tiên của thế hệ Qwen3.6. Đây là sparse Mixture-of-Experts 35B tham số tổng, chỉ 3B active mỗi token, đa phương thức gốc (text/image/video/document), context 262,144 token (mở rộng ~1,010,000 qua YaRN), và chạy được trên MacBook 24GB qua 4-bit GGUF. Benchmark đáng chú ý: SWE-bench Verified 73.4, Terminal-Bench 2.0 51.5, AIME 2026 92.7, GPQA Diamond 86.0 — vượt Gemma 4-31B double-digit và bám sát Claude Sonnet 4.5 trên coding + math.

Điểm mới
- Sparse MoE 256 experts: 8 routed + 1 shared activate per token → 3B active parameters, trong khi 35B weights vẫn nằm trên đĩa/VRAM. Lưu trữ như mô hình lớn, compute như mô hình nhỏ.
- Hybrid attention mới: 40 layer xếp thành 10 block × [3× (Gated DeltaNet → MoE) + 1× (Gated Attention → MoE)]. Gated DeltaNet (linear attention O(n)) lo long-context rẻ; Gated Attention (GQA 16Q/2KV) lo chính xác local token — tỉ lệ 4:1 là điểm cân bằng hiệu quả/độ chính xác cho repo-scale.
- Thinking Preservation: tính năng mới, bật bằng
preserve_thinking: truequachat_template_kwargs. Reasoning traces từ lượt trước được giữ lại và dùng ở lượt sau, thay vì recompute từ đầu. Agent loop nhờ đó giữ được bối cảnh kiến trúc giữa các tool call. - Multi-Token Prediction (MTP): MTP heads được huấn luyện sẵn → speculative decoding native trên SGLang/vLLM, không cần draft model phụ.
- Multimodal gốc + 201 ngôn ngữ: vision encoder tích hợp cho image/video/document; phủ tiếng Anh, Trung, Nhật, Hàn, Việt, Thái, Indonesia, và cả phương ngữ Quảng Đông/Mân Nam.
Vì sao quan trọng
Đây là lần đầu một mô hình open-weight Apache 2.0 đồng thời đạt được 3 điều kiện mà trước đây phải chọn một: (1) hiệu năng agentic coding gần frontier, (2) chạy local trên laptop consumer, (3) giấy phép thương mại sạch. Trước Qwen3.6, bạn phải chọn giữa gọi API đóng (tốn tiền, privacy kém) hoặc chạy local một mô hình yếu hơn đáng kể.
Điểm kiến trúc then chốt: 3B active parameters đủ để đánh bại 30B-class dense trên coding. Nếu kết quả này generalise sang các workload hẹp khác (toán, reasoning, vision) trong vài release tới, ngân sách compute cho local AI sẽ bị viết lại lần nữa.
Số liệu kỹ thuật
| Thuộc tính | Giá trị |
|---|---|
| Total params | 35B |
| Active params / token | 3B |
| MoE experts | 256 (8 routed + 1 shared) |
| Hidden dim | 2048 |
| Expert intermediate dim | 512 |
| Layers | 40 (10 block × [3 Gated DeltaNet + 1 Gated Attention]) |
| Attention heads | GQA 16 Q / 2 KV |
| Context native | 262,144 token |
| Context với YaRN | ~1,010,000 token |
| MTP speculative decoding | native |
| License | Apache 2.0 |
So sánh
| Benchmark | Qwen3.6-35B-A3B | Gemma 4-31B | Claude Sonnet 4.5 |
|---|---|---|---|
| SWE-bench Verified | 73.4 | 52.0 | 72.1 |
| SWE-bench Pro | 49.5 | 35.7 | 48.9 |
| Terminal-Bench 2.0 | 51.5 | 42.9 | 50.8 |
| MCPMark (tool use) | 37.0 | 18.1 | — |
| AIME 2026 | 92.7 | 84.1 | 90.5 |
| GPQA Diamond | 86.0 | 79.4 | 84.7 |
| MMMU (vision) | 81.7 | 80.4 | 82.3 |
| RealWorldQA | 85.3 | 72.3 | 70.3 |
| RefCOCO (grounding) | 92.0 | — | 88.1 |
So với tiền nhiệm Qwen3.5-35B-A3B: Terminal-Bench 2.0 tăng từ 40.5 lên 51.5 (+27%), QwenWebBench frontend từ 978 lên 1397 (+43%), SWE-bench Verified từ 70.0 lên 73.4. Riêng MCPMark gấp đôi Gemma 4-31B (37.0 vs 18.1) — khoảng cách tool-calling rõ rệt nhất trong tập benchmark.
Use case thực tế
- Agentic coding repo-scale: Cursor, Continue.dev, VS Code Copilot, Qwen Code CLI (
pip install qwen-code). Tool-calling qua parserqwen3_codercho vLLM/SGLang, cắm thẳng vào MCP servers — stack tool đang chạy với Claude Code slot thẳng vào được. - Refactor cross-file: hiểu cây component React/Vue, giữ convention dự án, tránh breaking change. Thinking Preservation giữ quyết định kiến trúc (JWT+Redis) xuyên qua nhiều lượt prompt, giảm ~80% overhead re-explain.
- GraphRAG bug-fix: paper tháng 3/2026 với Qwen3.5-35B-A3B đã nâng bug resolution 24% → 32%, regression 6.08% → 1.82%. Qwen3.6 kế thừa và mở rộng.
- Local privacy-first: indie dev và team on-prem xử lý codebase proprietary có thể chạy hoàn toàn offline trên Mac 24GB qua Unsloth Q4 GGUF (20.9GB), còn dư RAM cho OS.
- Budget rig CPU+GPU: RTX 4090 + 128GB DDR5 + KTransformers — MoE sparsity cho phép offload experts inactive xuống RAM rẻ hơn hẳn dense 30B.
Giới hạn & pricing
Hardware theo precision:
- FP16/BF16: ~70–72GB VRAM (2× A100)
- INT8: ~35–36GB (A100 40GB)
- Unsloth dynamic Q4 GGUF: ~18–20GB (RTX 3090/4090, Mac 24GB)
Pricing: self-host MIỄN PHÍ (Apache 2.0, commercial OK, patent grant). Cloud qua Alibaba Model Studio là qwen3.6-flash; tier Qwen3.6-Plus ~2 RMB / 1M input token (Trung Quốc) hoặc ~$0.325 / 1M input qua OpenRouter.
Cần biết trước khi migrate từ Qwen3: soft switch /think và /nothink đã bỏ — phải chuyển mode qua API param enable_thinking: false. Safety tuning ít được document hơn closed models, và parity chất lượng Anh–Trung ở long-context chưa được audit độc lập. Dense frontier như Claude Opus 4.7 hoặc GPT-4o vẫn dẫn trước ở adversarial long-horizon tool chains.
Sắp tới
Qwen3.6-35B-A3B được mô tả rõ là "first open-weight variant of the Qwen3.6 generation" — rất khả năng thế hệ 3.6 sẽ rollout tiếp các size nhỏ/lớn/chuyên biệt, theo đúng nhịp Qwen3.5 đã làm (flagship 397B-A17B → mid-large 122B/35B/27B → small 0.8B–9B trong vòng 3 tuần). Release này diễn ra chỉ một tháng sau khi tech lead Junyang Lin rời đi, cho thấy pipeline open-source Qwen vẫn vận hành nguyên vẹn. Qwen hiện đã vượt Meta Llama về số download Hugging Face (600M+) và số derivative models (170K).
Tải về: Hugging Face, Ollama, Unsloth GGUF. Cloud: Qwen Studio.
Nguồn: Qwen blog, MarkTechPost, Lilting Channel, DEV Community.

