
TL;DR
Ngày 16/4/2026, đội Qwen của Alibaba tung Qwen3.6-35B-A3B lên Hugging Face và ModelScope — một model MoE có 35 tỷ tham số tổng nhưng chỉ 3 tỷ active mỗi inference, mở hoàn toàn dưới giấy phép Apache 2.0. Kết hợp với Qwen3.6 Plus (closed, 1M context) ra trước đó hai tuần, đây là đợt release mạnh nhất của Qwen từ đầu năm 2026 — và nó đang đè Gemma 4-31B dense lẫn Claude Sonnet 4.5 trên nhiều benchmark coding + multimodal.

What's new
Qwen3.6 không chỉ là bản nâng cấp số từ 3.5. Đội Qwen thực sự đổi kiến trúc và training objective để ưu tiên agent workflow thay vì chat tổng quát:
- Thinking Preservation: model giữ lại các đoạn
<think>xuyên suốt lịch sử hội thoại — trước đây reasoning phải chạy lại từ đầu mỗi lượt. Giảm token dư thừa, tăng KV-cache hit, cải thiện tính nhất quán của agent. - Always-on chain-of-thought: khắc phục bệnh "overthinking" kinh niên của 3.5. Model mặc định suy luận nội bộ rồi mới trả lời, không còn toggle
/thinkvs/nothink. - Computer Use (bản Plus): agent tự mở browser, click menu, điền form, chạy lệnh terminal, đọc output và tiếp tục — không chỉ sinh code như assistant truyền thống.
- Visual-to-Code: upload wireframe Figma hoặc screenshot UI, nó sinh thẳng React/Flutter components, CSS, routing khớp design intent.
Why it matters
Cái "3B active" là đòn đánh vào kinh tế hạ tầng. Với dense 31B như Gemma 4 hoặc 70B+ của Llama, bạn trả chi phí inference tương ứng với 100% tham số. MoE sparse của Qwen3.6 chỉ "đánh thức" 8 expert routed + 1 shared mỗi token — nghĩa là chi phí compute xấp xỉ model 3B, nhưng chất lượng gần với model 35B+. Với indie developer hay startup đang vật lộn với API bill, đây là một cú lật bàn.
Thêm nữa, Apache 2.0 nghĩa là không có điều khoản MAU, không bị "custom license" kiểu Qianwen cho bản Plus — bạn self-host thương mại thoải mái, fine-tune thoải mái, tái phân phối thoải mái.
Technical facts
| Thuộc tính | Qwen3.6-35B-A3B |
|---|---|
| Tham số tổng / active | 35B / 3B |
| Kiến trúc | Sparse MoE, 256 experts (8 routed + 1 shared) |
| Số layer | 40 (Gated DeltaNet + Gated Attention xen kẽ) |
| Context length | 262,144 native — mở rộng 1,010,000 qua YaRN |
| Multimodal | Text + ảnh + video native |
| License | Apache 2.0 |
| Training objective | Multi-Token Prediction (MTP) |
Comparison
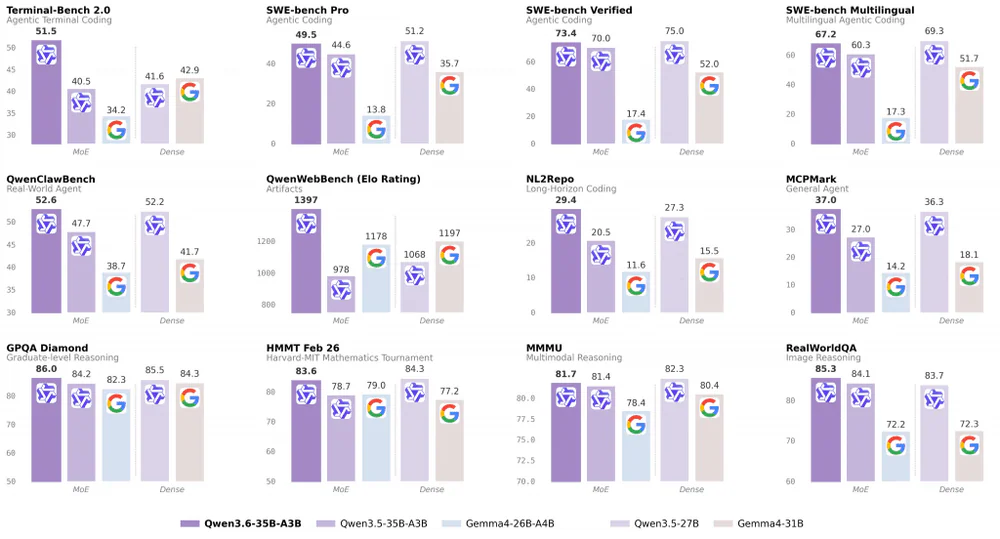
Trên benchmark coding, Qwen3.6-35B-A3B chỉ với 3B active đã đánh bại Gemma 4-31B dense (mạnh hơn 10 lần về active params):
| Benchmark | Qwen3.6-35B-A3B | Gemma 4-31B | Chênh |
|---|---|---|---|
| SWE-bench Verified | 73.4 | 52.0 | +21.4 |
| SWE-bench Multilingual | 67.2 | 51.7 | +15.5 |
| SWE-bench Pro | 49.5 | 35.7 | +13.8 |
| Terminal-Bench 2.0 | 51.5 | 42.9 | +8.6 |
| QwenWebBench (Elo) | 1397 | 1197 | +200 |
| NL2Repo | 29.4 | 15.5 | +13.9 |
Trên vision-language, bảng của Alibaba cho thấy Qwen3.6 vượt Claude Sonnet 4.5 ở đa số category: RealWorldQA 85.3 vs 70.3 (+15), MLVU 86.2 vs 72.8 (+13.4), CC-OCR 81.9 vs 68.1 (+13.8), MMMU-Pro 75.3 vs 68.4 (+6.9). Về spatial intelligence, Qwen đạt SOTA: RefCOCO 92.0, ODInW13 50.8.
Chỉ điểm duy nhất Qwen thua Gemma 4-31B là MMMU-Pro (75.3 vs 76.9 — chênh 1.6).
Use cases
- Enterprise codebase audit: đẩy toàn bộ repo vào 1M-token context (với Plus), yêu cầu quét vulnerability rồi sinh patch theo risk-rank — không cần chunking/RAG workaround.
- Legacy migration: model giữ toàn bộ scope project trong context, sinh migration plan file-by-file rồi execute qua tool use.
- Automated code review: đọc PR diff với full codebase context, flag issue và post feedback có cấu trúc.
- Visual-to-code: designer upload Figma export hoặc whiteboard sketch, model sinh React/Flutter components + CSS + routing khớp design.
- Autonomous GUI: agent mở browser, điền form, extract data, chạy terminal command, quan sát output và iterate.
Limitations & pricing
Qwen3.6-35B-A3B (open): free, Apache 2.0. Để phục vụ context tối đa 262K cần tensor parallel qua 8 GPU (SGLang/vLLM). YaRN scaling lên 1M là static — có thể giảm nhẹ chất lượng ở context ngắn. Alibaba khuyến nghị giữ context tối thiểu 128K để không mất khả năng thinking. llama.cpp (GGUF) và MLX (Apple Silicon) đã hỗ trợ cho ai muốn chạy local quantized.
Qwen3.6 Plus (proprietary): OpenRouter preview hiện free tại qwen/qwen3.6-plus-preview:free, nhưng Alibaba thu prompt + completion để train — không gửi code proprietary hay dữ liệu khách hàng. API chính thức Alibaba Cloud: $0.50/1M input + $3.00/1M output. Context 1M, output tối đa 65,536 tokens. Tốc độ 52.9 tok/s, TTFT 2.65s.
What's next
Qwen3.6 Plus sẽ chuyển từ free preview sang paid general availability (timeline chưa công bố). User Guide chính thức đang được chuẩn bị. Alibaba cũng dự kiến open-source QwenClawBench — benchmark agent real-user-distribution họ đang dùng nội bộ.
Các bản 3.6 nhỏ hơn (0.8B–9B kiểu 3.5 small series) chưa được xác nhận. Nếu Alibaba theo đúng cadence năm trước, kỳ vọng có distilled versions trong 1–2 tháng tới.
Nguồn: Qwen/Qwen3.6-35B-A3B on Hugging Face, QwenLM/Qwen3.6 GitHub, OfficeChai benchmark analysis, Artificial Analysis — Qwen3.6 Plus.