
- Google DeepMind vừa phát hành Gemma 4 — bộ 4 mô hình mở dưới giấy phép Apache 2.0.
- Phiên bản 26B A4B dùng kiến trúc Mixture-of-Experts: 25.2 tỷ tham số tổng nhưng chỉ kích hoạt 3.8 tỷ mỗi token, đạt ELO 1441 trên Arena AI (top 6 mô hình mở thế giới), context 256K, đa phương thức text + ảnh + video, hỗ trợ 140+ ngôn ngữ.
- Quan trọng nhất: chạy gọn trên MacBook M4 Max hoặc RTX consumer với 16-18GB RAM ở quant 4-bit.
TL;DR
Ngày 2/4/2026, Google DeepMind ra mắt Gemma 4 — bộ 4 mô hình mở dưới giấy phép Apache 2.0 (không giới hạn MAU, không cấm thương mại). Trong đó, Gemma 4 26B A4B là phiên bản Mixture-of-Experts (MoE) với 25.2 tỷ tham số tổng nhưng chỉ kích hoạt 3.8 tỷ mỗi token, đạt ELO 1441 trên Arena AI text leaderboard (xếp #6 thế giới trong nhóm mô hình mở), context 256K, đa phương thức text + ảnh + video, 140+ ngôn ngữ. Chạy được trên MacBook M4 Max hoặc RTX consumer chỉ với 16-18GB RAM ở quant 4-bit.

Có gì mới
Gemma 4 không phải bản nâng cấp nhỏ. Nó được xây dựng cùng nền tảng nghiên cứu với Gemini 3, và Google công bố cả 4 size cùng lúc:
- E2B — 2.3B effective params (5.1B tổng với PLE), context 128K, hỗ trợ text + ảnh + audio. Chạy trên điện thoại, Raspberry Pi 5 (133 tokens/sec prefill).
- E4B — 4.5B effective (8B tổng), context 128K, text + ảnh + audio. Cho laptop.
- 26B A4B — MoE 25.2B/3.8B active, context 256K, text + ảnh + video. Tối ưu cho consumer GPU.
- 31B Dense — 30.7B params, context 256K. Mô hình chất lượng cao nhất, xếp #3 thế giới trong open models trên Arena AI.
Điểm thay đổi quan trọng nhất về mặt pháp lý: Gemma 4 chuyển sang giấy phép Apache 2.0 — bằng với Qwen 3.5, cởi mở hơn cộng đồng license của Llama 4. Không còn giới hạn người dùng hoạt động hàng tháng, không còn ràng buộc acceptable-use. Doanh nghiệp triển khai được trong sản phẩm thương mại và môi trường chủ quyền (sovereign cloud) mà không sợ vi phạm.
Tại sao điều này quan trọng
Bài học của MoE đã rõ từ DeepSeek-V3 và Mixtral: kích hoạt một phần nhỏ tham số mỗi token = tốc độ inference cực nhanh, chất lượng vẫn gần dense. Gemma 4 26B A4B đẩy logic này tới điểm sweet spot mới: chỉ 3.8B tham số active mà đạt khoảng 97% chất lượng của bản 31B dense với chi phí compute chỉ bằng một phần nhỏ.
Hệ quả thực tế: bạn lấy được trí tuệ "frontier-class" ngay trên MacBook Pro M4 Max hoặc một chiếc RTX 4090 — không cần API, không cần gửi dữ liệu lên cloud, không trả phí token. Đây là bước nhảy về "intelligence-per-parameter" mà Google nói thẳng là vượt mặt các mô hình lớn gấp 20 lần trên Arena.
Technical facts
Thông số đầy đủ của Gemma 4 26B A4B:
| Thuộc tính | Giá trị |
|---|---|
| Total params | 25.2B |
| Active params/token | 3.8B |
| Layers | 30 |
| Sliding window | 1024 tokens |
| Context length | 256K tokens |
| Vocab size | 262K |
| Experts | 128 fine-grained, top-8 routing + 1 shared per token |
| Modalities | Text, Image, Video (60s @ 1fps) |
| Vision encoder | ~550M params, token budget 70/140/280/560/1120 |
| Languages | 140+ pre-trained, 35+ instruction-tuned |
Kiến trúc dùng alternating attention (xen kẽ sliding-window local + global full-context), dual RoPE (standard cho local, proportional cho global — đó là cách giữ chất lượng ở context 256K), và shared KV cache ở các layer cuối để giảm bộ nhớ và compute lúc inference. Vision encoder dùng 2D positional encoder với multidimensional RoPE giữ aspect ratio gốc.
So sánh với Gemma 3 và đối thủ
Bảng benchmark chính thức của Google:
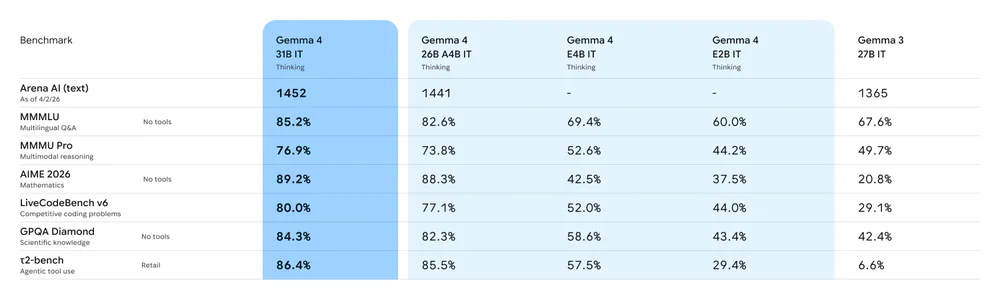
Bước nhảy thế hệ so với Gemma 3 27B đặc biệt rõ ở các bài toán suy luận:
| Benchmark | Gemma 4 26B A4B | Gemma 3 27B |
|---|---|---|
| Arena AI ELO | 1441 | 1365 |
| MMLU Pro | 82.6% | 67.6% |
| AIME 2026 (math) | 88.3% | 20.8% |
| LiveCodeBench v6 | 77.1% | 29.1% |
| Codeforces ELO | 1718 | 110 |
| GPQA Diamond | 82.3% | 42.4% |
| BigBench Extra Hard | 64.8% | 19.3% |
| MMMU Pro (multimodal) | 73.8% | 49.7% |
Ấn tượng nhất là AIME 2026 nhảy từ 20.8% lên 88.3% và Codeforces ELO từ 110 lên 1718 — không phải cải thiện, mà là một mô hình hoàn toàn khác về năng lực toán và lập trình. Trên Arena, đường "efficiency frontier" của Gemma 4 26B A4B nằm ngay phía trên các mô hình trăm tỷ params:
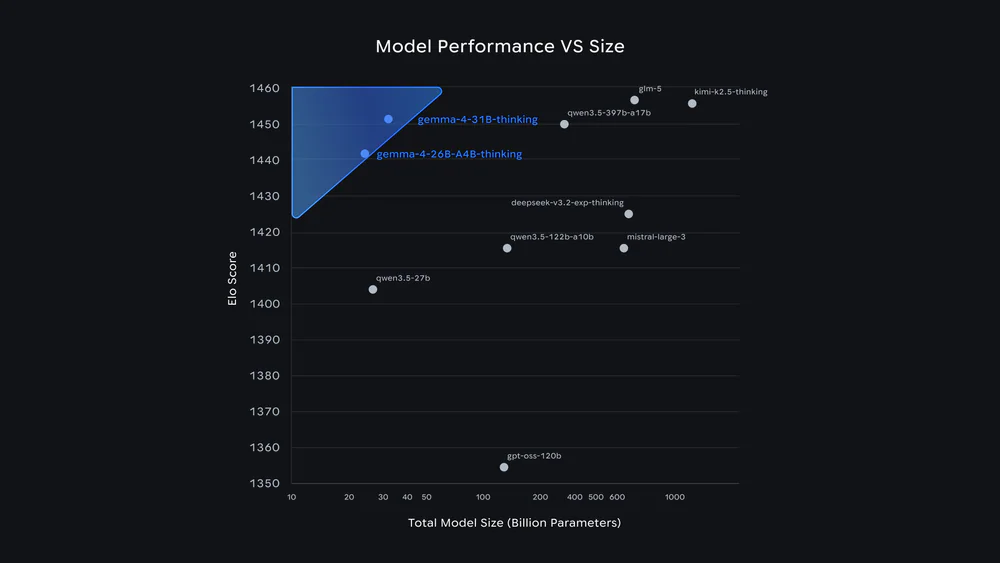
Use cases thực tế
Đối tượng hưởng lợi nhiều nhất là dev/researcher/student có máy cá nhân "đủ ngon":
- Coding assistant local-first trong IDE — code không rời khỏi máy, không quota API.
- Autonomous agent — hỗ trợ native function calling, structured JSON output, multi-step planning, "thinking mode" bật bằng token
<|think|>ở đầu system prompt. - Browser/desktop automation — vision encoder xuất bounding box trên UI element, dùng làm não cho script tự động hóa screen-parsing.
- OCR đa ngôn ngữ + parse PDF — set visual token budget cao (560 hoặc 1120) để giữ chữ nhỏ, công thức toán, chữ viết tay.
- Phân tích tài liệu dài — context 256K nuốt nguyên repo code hoặc paper nghiên cứu trong một prompt.
- Video understanding — tối đa 60 giây ở 1 fps, đủ cho clip ngắn / demo.
Hạn chế & giá
Giá: miễn phí. Apache 2.0, tải trực tiếp từ Hugging Face (google/gemma-4-26B-A4B-it), Kaggle, Ollama hoặc LM Studio. Triển khai thương mại tự do, chỉ trả phí compute nếu chạy trên Vertex AI / Cloud Run / GKE.
Yêu cầu phần cứng (26B A4B — toàn bộ 25.2B params phải nạp vào RAM dù chỉ 3.8B active):
| Quantization | RAM/VRAM |
|---|---|
| 4-bit (Q4_0 / Dynamic 4-bit) | 16-18 GB |
| 8-bit | 25-30 GB |
| BF16 / FP16 | 48-52 GB |
Tức là MacBook Pro M4 Max (36GB+ unified memory) hoặc RTX 4090 (24GB) chạy 4-bit ngon lành. BF16 unquantized cần single H100 80GB.
Hạn chế:
- Knowledge cutoff tháng 1/2025 — sự kiện gần đây không biết.
- 26B A4B không xử lý audio (chỉ E2B/E4B có).
- Như mọi LLM: hallucination, thiếu common sense, dễ bias từ web data.
- Không nên dùng
CUDA 13.2 runtimevới GGUF — Unsloth cảnh báo gây output kém.
Cách bắt đầu & What's next
Cài nhanh trên macOS:
ollama run gemma4:26b-a4b-it-q4_K_MHoặc dùng MLX dynamic 4-bit quant (có vision support cho Mac), LM Studio, llama.cpp, vLLM, Unsloth Studio đều support day-one.
Google chưa công bố roadmap thêm variant nào cho Gemma 4. Forward-looking duy nhất: Android dev có thể prototype trong AICore Developer Preview để forward-compatible với Gemini Nano 4 (proprietary, mobile-only).
Nguồn: blog.google, DeepMind, Hugging Face model card, Unsloth docs.

