
TL;DR
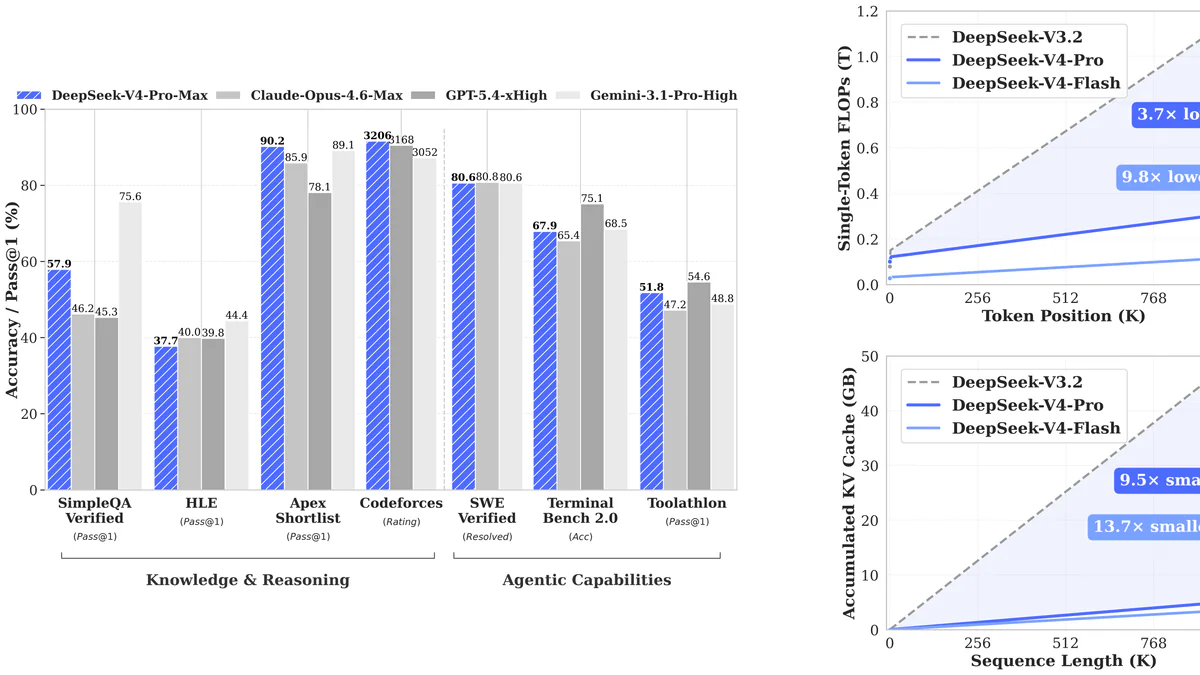
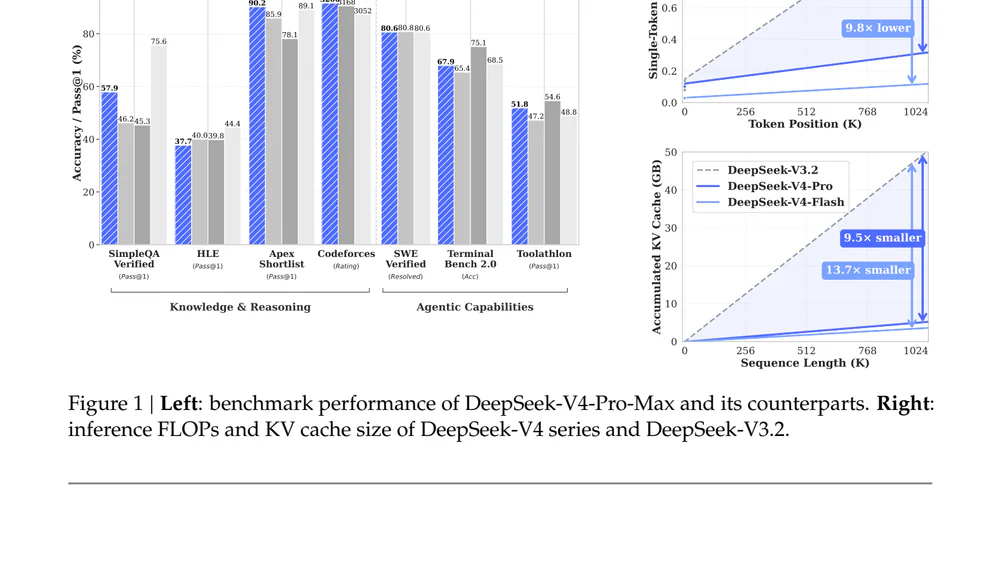
DeepSeek-V4 Preview ra mắt 24/04/2026 với hai model open-weight: V4-Pro (1.6T total / 49B active) và V4-Flash (284B / 13B). Cả hai hỗ trợ 1M token context native. Ở 1M token, V4-Pro chỉ tốn 27% single-token FLOPs và 10% KV cache so với V3.2; V4-Flash còn ấn tượng hơn — 10% FLOPs, 7% KV cache. V4-Pro-Max đạt Codeforces 3206 (xếp ~hạng 23 giữa các thí sinh người), 120/120 Putnam-2025, LiveCodeBench 93.5 — open-model SOTA. Giá output V4-Pro $3.48/M (rẻ hơn Claude Opus 4.6 7×); V4-Flash $0.28/M (rẻ hơn 89×).
What's new
DeepSeek không chỉ scale up. Họ giải bài toán chính của long-context: chi phí inference. KV cache là dung lượng GPU phải giữ cho mọi token đã có trong context — tăng tuyến tính theo độ dài, ở 1M token đủ để buộc bạn phải dùng cluster lớn hoặc giết throughput. Cắt còn 10% nghĩa là phục vụ context dài hơn trên máy nhỏ hơn, hoặc nhồi nhiều user hơn lên cùng một GPU.
Inference FLOPs là chi phí compute để sinh ra token kế tiếp. Với attention thường, scaling là quadratic theo độ dài — đó là lý do long-context đắt cắt cổ. Còn 27% nghĩa mỗi token sinh ra ở 1M context rẻ hơn gần 4 lần.
Cộng lại: long-context inference từ tính năng cao cấp phải tiết kiệm trở thành thứ bạn bật mặc định.
Why it matters
Đây là lần đầu một open-weight model làm cho 1M context khả thi về kinh tế ở quy mô production. Workload từng tốn $1 compute trên V3.2 ở 1M token nay chỉ còn ~$0.27 trên V4-Pro — và còn rẻ hơn nữa với V4-Flash. Full-codebase analysis, multi-document RAG, Q&A trên corpus pháp lý / tài chính — những workload trước đây không khả thi giờ chạy được.
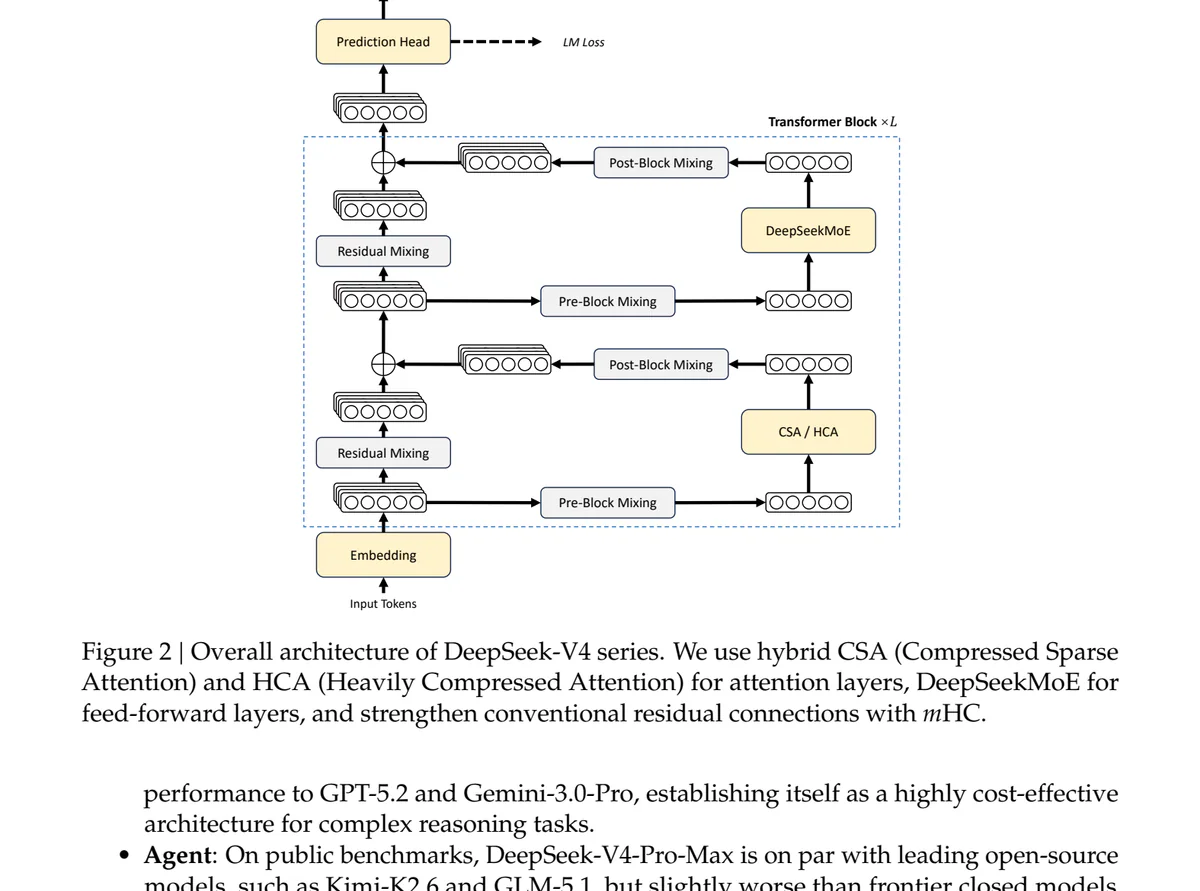
Hybrid Attention: CSA + HCA
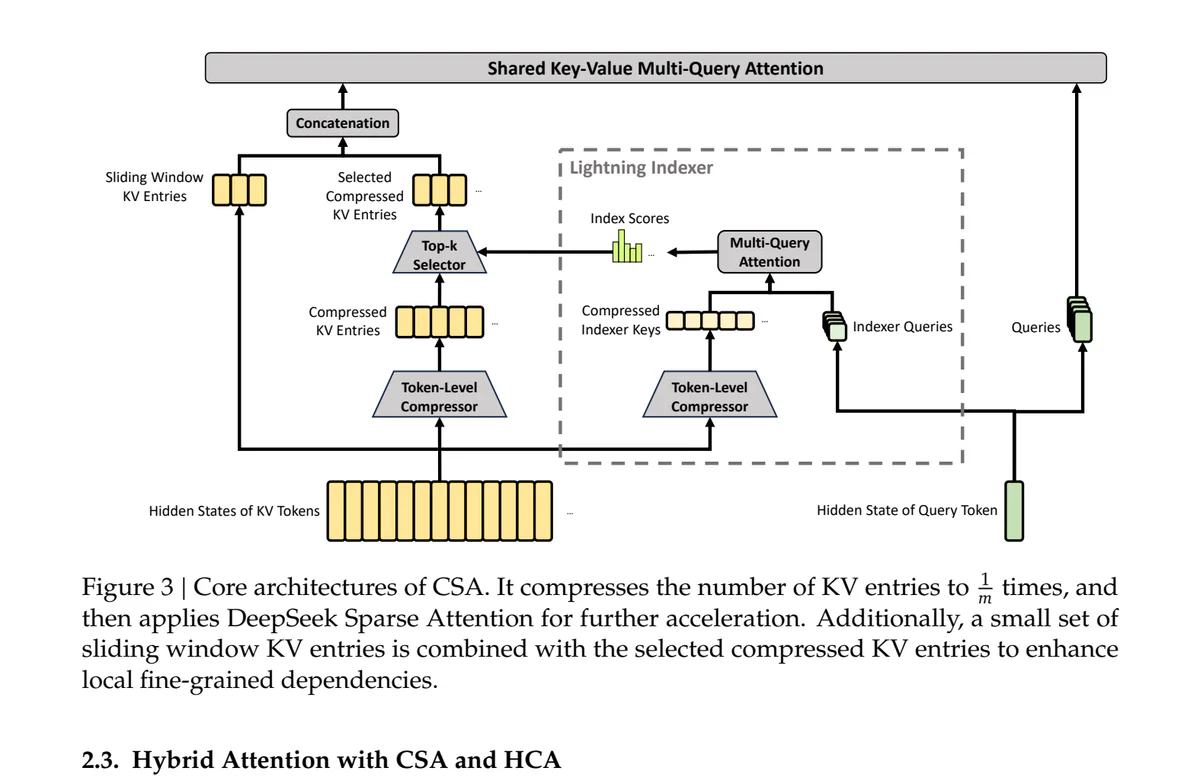
Bí mật nằm ở thiết kế attention lai, đan xen hai cơ chế thay vì chọn một.
CSA — Compressed Sparse Attention. Với mỗi m KV entry (ví dụ 4) gộp lại thành 1 entry nén qua một token-level compressor học được. Sau đó Lightning Indexer chấm điểm các block nén so với query, top-k được chọn để attend. Vừa nén vừa sparse — chồng hai kỹ thuật giảm chi phí lên cùng một dữ liệu.
HCA — Heavily Compressed Attention. Aggressive hơn nhiều: nén mỗi m' token (ví dụ 128, m' ≫ m) thành 1 entry, rồi áp dụng dense attention trên tập nhỏ đó. Bỏ luôn bước sparse selection — vì ở tỉ số nén đó, dense attention trên một set tí hon đã rẻ sẵn.
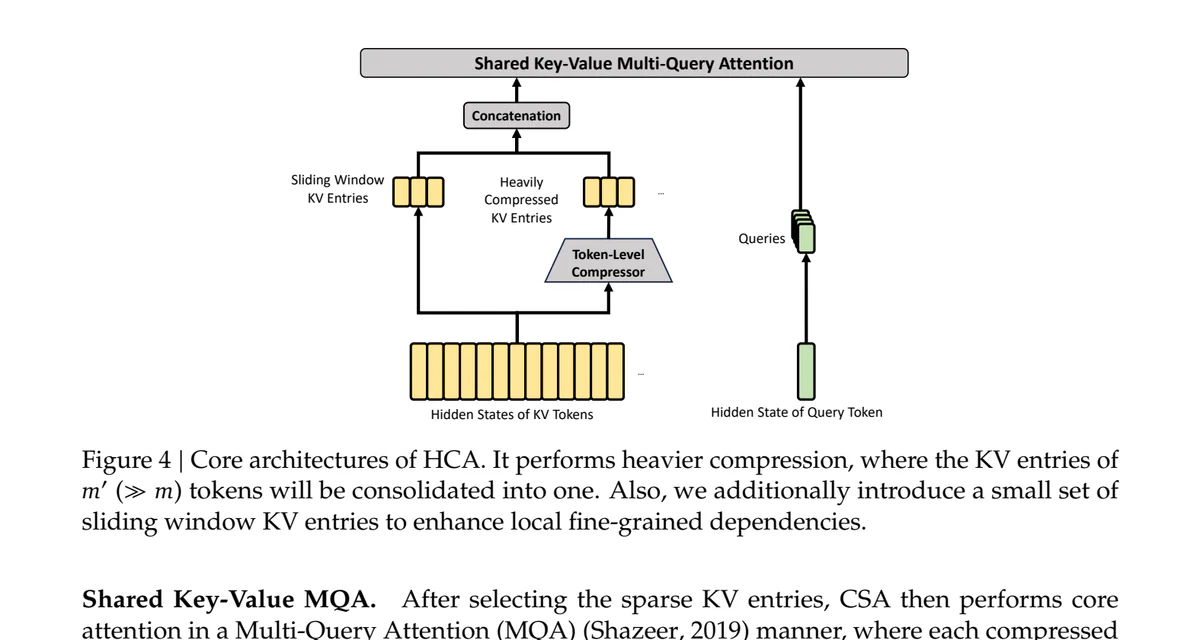
Cả hai đều có một nhánh sliding window phủ 128 token gần nhất, đảm bảo cấu trúc local fine-grained không bị compression nuốt mất.
Các layer đan xen CSA / HCA: CSA lo medium-grained retrieval, HCA lo coarse summarization. Bạn nhận được cả hai mà không phải trả phí đầy đủ cho cả hai.
Technical facts
| Spec | V4-Pro | V4-Flash |
|---|---|---|
| Total params | 1.6T | 284B |
| Active params/token | 49B | 13B |
| Training tokens | 33T | 32T |
| Context length | 1M | 1M |
| Max output | 384K | 384K |
| FLOPs vs V3.2 @1M | 27% | 10% |
| KV cache vs V3.2 @1M | 10% | 7% |
| Precision | FP4 + FP8 mixed | FP4 + FP8 mixed |
Ngoài hybrid attention, V4 còn ba đổi mới đáng chú ý:
- Manifold-Constrained Hyper-Connections (mHC) thay residual connections, ràng buộc ma trận residual lên Birkhoff polytope qua Sinkhorn-Knopp — giữ spectral norm ≤ 1 và stable khi stack nhiều layer.
- Muon optimizer với Newton-Schulz orthogonalization (8 + 2 iterations), AdamW giữ cho embeddings, prediction head, biases và RMSNorm.
- DSML XML tool-call schema với token
|DSML|riêng — giảm parsing error so với JSON-in-string. Interleaved thinking giữ reasoning trace qua các user turn (V3.2 flush mỗi turn mới).
Comparison vs frontier
| Benchmark | V4-Pro-Max | Opus 4.6 Max | GPT-5.4 xHigh | Gemini 3.1 Pro |
|---|---|---|---|---|
| LiveCodeBench | 93.5 | 88.8 | — | 91.7 |
| Codeforces (rating) | 3206 | — | 3168 | 3052 |
| SWE-Verified | 80.6 | 80.8 | — | 80.6 |
| Terminal-Bench 2.0 | 67.9 | 65.4 | 75.1 | 68.5 |
| MMLU-Pro | 87.5 | 89.1 | 87.5 | 91.0 |
| GPQA Diamond | 90.1 | 91.3 | 93.0 | 94.3 |
| MRCR 1M | 83.5 | 92.9 | — | 76.3 |
| SimpleQA-Verified | 57.9 | 46.2 | 45.3 | 75.6 |
| Putnam-2025 Frontier | 120/120 | — | — | — |
V4-Pro-Max đứng đầu open-model trên LiveCodeBench, Codeforces, Apex Shortlist; ngang Opus và Gemini ở SWE-Verified; thắng Opus 2.5 điểm trên Terminal-Bench 2.0. DeepSeek tự thừa nhận V4 trễ frontier 3–6 tháng ở MMLU-Pro / GPQA / HLE và bị Opus 4.6 dẫn ở MRCR 1M (92.9 vs 83.5) trong long-context retrieval khắc nghiệt nhất.
Use cases
- Long-context workload: full-repo code analysis, multi-document RAG, legal/financial corpus Q&A. KV cache giảm 90% nghĩa là 10× concurrent user trên cùng GPU memory.
- Agentic coding & dev tooling: top open-model trên LiveCodeBench / Codeforces; tích hợp với Claude Code, OpenCode, OpenClaw qua endpoint OpenAI-compatible.
- Agentic search: trên 869 task internal eval của DeepSeek, agentic search thắng 61.7% so với RAG 18.3% — chính xác là loại workload long-context, lặp prefix, nhiều tool call mà V4 được thiết kế cho.
- Chinese writing: V4-Pro thắng Gemini 3.1 Pro 62.7% vs 34.1% win rate trên internal eval.
Limitations & pricing
| Model | Input (cache miss) | Input (cache hit) | Output |
|---|---|---|---|
| V4-Flash | $0.14 | $0.028 | $0.28 |
| V4-Pro | $1.74 | $0.145 | $3.48 |
| GPT-5.5 | $5.00 | $0.50 | $30.00 |
| Claude Opus 4.7 | $5.00 | (caching) | $25.00 |
Hạn chế cần biết: benchmark là self-reported — Artificial Analysis chưa re-eval đầy đủ. Open-weight không có nghĩa open-data: training pipeline và serving stack vẫn đóng. Không native multimodal — vision/screen-use vẫn cần GPT-5.5 / Opus 4.7 / Gemini. API infrastructure đặt ở Trung Quốc → cân nhắc data sovereignty cho ngành quy định nghiêm ngặt; mitigation là self-host weights MIT-licensed (cần multi-H100/H200 cho V4-Pro).
What's next
Cả hai model gắn nhãn preview — tech report của DeepSeek nói sẽ còn post-training refinement trước khi V4 chốt cuối. Open weights MIT đã có trên Hugging Face; community GGUF quantization dự kiến xuất hiện trong vài ngày. Một chi tiết địa chính trị đáng lưu ý: V4 được train trên silicon Huawei, chứng minh frontier-class model có thể train ngoài hệ NVIDIA.
Kỷ nguyên 1 triệu token context trên open-weight model đã bắt đầu — và lần này, giá phải chăng đủ để bật mặc định.
Nguồn: Hugging Face Blog, MarkTechPost, DeepSeek-V4-Pro model card, Simon Willison, BuildFastWithAI, @akshay_pachaar.