TL;DR
- LocallyAI update mới nhất đưa Gemma 4 26B A4B và 31B Dense lên Mac — hai model lớn nhất, thông minh nhất từng có trong app.
- Cùng update fix các vấn đề với Gemma 4 trên iPhone/iPad tương thích (E2B, E4B).
- 26B A4B: Mixture-of-Experts 128 experts, chỉ 16 active mỗi token, ~3.8B active params. Đạt ~150 tokens/s trên consumer GPU và xếp #6 open model trên Arena AI.
- 31B Dense: xếp #3 open model thế giới trên Arena AI với Elo 1452. Dense transformer, chất lượng raw cao nhất.
- Cả hai hỗ trợ 256K context, multimodal (vision + video), agentic workflows với function calling native, 140+ ngôn ngữ, Apache 2.0 license.
- Chạy 100% offline trên Apple Silicon qua MLX framework — không cloud, không login, không data collection.
What's new
Đúng theo thông báo chính thức từ LocallyAI, bản update này mang hai model Gemma 4 lớn nhất mà Google DeepMind vừa release ngày 02/04/2026 lên Mac:
- Gemma 4 26B A4B — Mixture-of-Experts với 128 chuyên gia tổng, chỉ 16 active trong mỗi bước inference. 26B tổng params nhưng chỉ ~3.8–4B active → tốc độ cực nhanh kèm chất lượng của model 30B+.
- Gemma 4 31B Dense — traditional dense transformer, tất cả 31B params active mỗi token. Chất lượng raw cao nhất, nền tảng fine-tune mạnh.
Update này cũng improve và fix issues với Gemma 4 trên iPhone/iPad đủ sức chạy (các variant E2B ~2.5GB, E4B). Cùng lúc, LocallyAI thông báo đang gia nhập LM Studio — một bước đi lớn cho ecosystem local inference trên Apple Silicon.
Why it matters
Đây là lần đầu tiên người dùng Mac có thể chạy frontier open model ở quy mô này hoàn toàn offline, với trải nghiệm native. LocallyAI dùng Apple MLX framework — đẩy inference vào GPU qua Metal, tận dụng unified memory của Apple Silicon. Không dùng Neural Engine (vốn dành cho Face ID, camera), nhưng chính GPU flexibility mới là thứ LLM cần.
Với 256K context window, bạn có thể đưa nguyên một repo code hoặc long document vào một prompt duy nhất — xử lý ngay trên máy, không tốn token API, không rate limit, không gửi dữ liệu đi đâu cả.
Technical facts
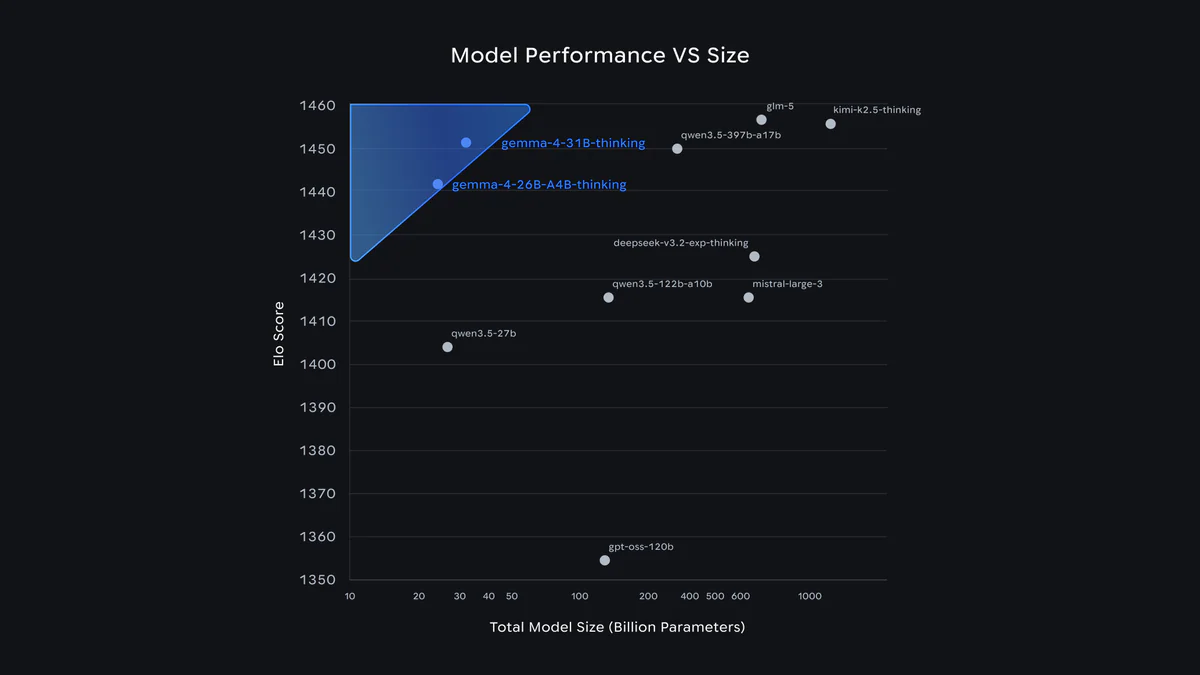
Gemma 4 là bước nhảy vọt về intelligence-per-parameter. Trên Arena AI chat leaderboard (tính đến 02/04/2026):
- Gemma 4 31B Thinking: Elo 1452 → xếp #3 open model thế giới, đánh bại nhiều model lớn gấp 20 lần.
- Gemma 4 26B A4B Thinking: Elo 1441 → xếp #6 open model, với chỉ 4B active params.
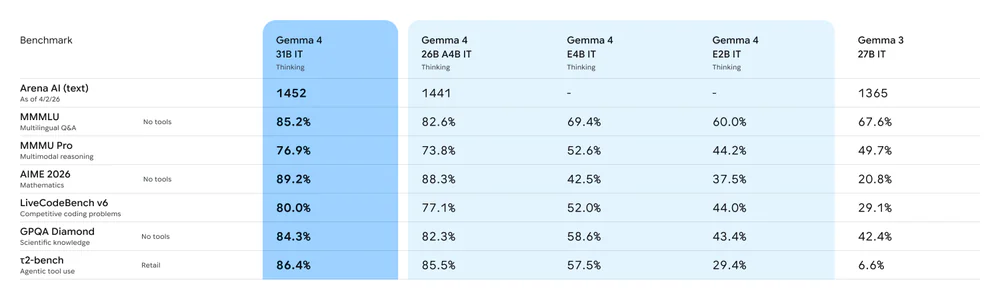
So với Gemma 3 27B (thế hệ trước), bước nhảy về reasoning và agentic là khổng lồ:
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 3 27B |
|---|---|---|---|
| AIME 2026 (Math, no tools) | 89.2% | 88.3% | 20.8% |
| LiveCodeBench v6 | 80.0% | 77.1% | 29.1% |
| Codeforces ELO | 2150 | 1718 | 110 |
| GPQA Diamond | 84.3% | 82.3% | 42.4% |
| τ2-bench (Agentic) | 86.4% | 85.5% | 6.6% |
| MMMU Pro (Vision) | 76.9% | 73.8% | 49.7% |
Kiến trúc có vài điểm mới đáng chú ý:
- Alternating attention: sliding-window 1024 tokens xen kẽ full-context attention.
- Shared KV Cache: các layer cuối reuse KV từ layer trước → giảm mạnh memory và compute cho long context.
- Per-Layer Embeddings (PLE): channel riêng cho từng layer, tăng specialization mà chỉ tốn ít params.
- Vision encoder: giữ aspect ratio gốc, token budget configurable (70/140/280/560/1120) — bạn tự cân speed vs quality.
Comparison
Trên consumer hardware (benchmark n1n.ai trên RTX 4090 24GB):
- 26B MoE (q4_k_m): ~150 tokens/s generation, fit thoải mái trong 24GB VRAM → sweet spot cho local AI.
- 31B Dense: VRAM maxed, phải offload sang RAM → drop xuống ~7.8 t/s. Trên Mac unified memory không bị PCIe bottleneck, 31B chạy tốt hơn nếu có M3 Max/Ultra hoặc M4 Max với 64GB+ RAM.
So với Gemma 3, Gemma 4 không chỉ nhanh hơn mà còn đặc biệt mạnh ở agentic. τ2-bench nhảy từ 6.6% lên 86.4% — từ "simple chat" sang model có thể build autonomous agent dùng tools, function calling, structured JSON output.
Use cases trên Mac

- Xử lý dữ liệu nhạy cảm: tài liệu tài chính cá nhân, notes công ty, data proprietary — không bao giờ rời máy.
- Coding assistant offline: viết Python, refactor code, review logic. Trong test qualitative, 31B giữ vững structural integrity so với Claude Code.
- Prototyping agentic workflows: build agent dùng function-calling native + structured JSON, chạy infinite iterations không lo token cost.
- Phân tích repo khổng lồ: nhét cả codebase vào 256K context window, hỏi trực tiếp, không cần RAG.
- Apple ecosystem automation: trigger model qua Apple Shortcuts, Siri ("Hey, Locally AI"), Control Center, Action Button, hoặc Local Voice Mode.
Limitations & pricing
Có vài điểm cần lưu ý:
- 256K context không free lunch: active context càng lớn càng ăn RAM. Thực tế nên cap 32K–64K trên máy RAM hạn chế để giữ tốc độ.
- 31B Dense kén máy: cần Mac có unified memory lớn (M3 Max/Ultra hoặc M4 Max với 64GB+). Máy M1/M2 RAM thấp nên chọn 26B A4B hoặc các variant nhỏ hơn.
- Code generation có thể thiếu "safety-first" commenting kiểu Claude Code.
- Các task dài như transcription hoặc PDF phân tích sâu vẫn nên dùng cloud model.
Pricing: hoàn toàn miễn phí. LocallyAI free trên Mac App Store, không login, không account. Weights Gemma 4 release dưới Apache 2.0 license — commercial-permissive, digital sovereignty, deploy thoải mái.
Yêu cầu Mac: Apple Silicon (M-series). Quantized 26B (q4/q5) chạy mượt với ~24GB unified memory; 31B nên có M3 Max/Ultra hoặc M4 Max với 64GB+ RAM.
What's next
Timeline ngắn gọn:
- 02/04/2026: Google DeepMind công bố Gemma 4 (E2B, E4B, 26B A4B, 31B Dense) với day-0 support trên MLX, llama.cpp, Ollama, LM Studio, vLLM.
- 07/04/2026: reviewers lần đầu chạy thành công Gemma 4 trên iPhone/Mac qua LocallyAI.
- Giữa 04/2026: bản update Mac thêm 26B A4B + 31B + fix issues E2B/E4B trên iOS.
- Roadmap: LocallyAI joining LM Studio — một unified ecosystem cho local inference trên Apple Silicon đang hình thành.
Gemma series đã đạt hơn 400 triệu lượt download với 100.000+ variants trong "Gemmaverse". Với việc Gemma 4 cùng đẳng cấp research với Gemini 3 nhưng open + chạy được trên máy cá nhân, ranh giới giữa cloud AI và local AI đang mờ đi rất nhanh.
Nguồn: Google Blog — Gemma 4, Google DeepMind, Hugging Face — Welcome Gemma 4, LocallyAI, n1n.ai benchmark.