
TL;DR
Unsloth vừa đăng demo bản 2-bit Qwen3.6-35B-A3B GGUF chạy trong Unsloth Studio local, thực hiện một repo bug hunt đầy đủ: thu evidence, repro, fix, viết test, draft PR — với 30+ tool call, 20 site search và chạy Python code. Model chiếm khoảng 10.8–12.3 GB dung lượng ở 2-bit, nên máy có ~13 GB RAM trống là bắt đầu xài được (Unsloth khuyến nghị 22 GB để dư headroom). License Apache 2.0, bản native lên đến 262K context, extensible 1M.
Có gì mới
Daniel Han (Unsloth AI) pin một discussion trên Hugging Face Hub chỉ vài giờ sau khi Alibaba release Qwen3.6-35B-A3B (2026-04-16). Thay vì test bản 4-bit như thường lệ, anh chạy thẳng UD-IQ2 — nén xuống cỡ 1/6 full precision — và để model tự xử một bài toán agentic coding thực sự: quét cả repo, tìm bug tiềm ẩn, đưa ra evidence, reproduce, fix, viết unit test và cuối cùng là draft một PR writeup.
Điểm đáng chú ý không phải việc model có thể gọi tool — mà là nó gọi được 30+ tool call liên tiếp mà không lạc đường, kết hợp search web (20 trang) và thực thi Python code bên trong Unsloth Studio. Với một bản 2-bit quant, đây là con số hầu như không ai dám kỳ vọng 6 tháng trước.
Trợ thủ làm nên demo:
- Qwen3.6 cải thiện parsing nested objects trong tool call → tỉ lệ thành công cao hơn Qwen3.5.
- Unsloth Studio có sẵn self-healing tool calling, web search và code execution (Python + Bash).
- Unsloth Dynamic 2.0 GGUF — quantization calibrate trên dataset use-case thật, các layer quan trọng được upcast, giảm drop chất lượng ở cực nén.
- Developer Role Support mới giúp Qwen3.6 chạy trong Codex, OpenCode và các agentic coding tool.
Vì sao điều này quan trọng
Hai năm qua, mỗi khi nói "AI làm bug hunt repo" là mặc định gọi Claude, GPT, hoặc Gemini qua cloud API. Lý do: model open-source đủ giỏi tool calling cần ít nhất 70B dense, chạy local thì phải 2× A100. Qwen3.6 lật ngược bài toán đó:
- MoE 35B total / 3B active — compute như model 3B nhưng kiến thức như 35B.
- 2-bit quant vẫn làm được agentic workflow — file 10.8 GB chạy được trên máy 16 GB RAM.
- Apache 2.0, không có ràng buộc thương mại, data stay local.
Với các team có yêu cầu về cost, latency, data sovereignty — hoặc đơn giản là indie dev chán mỗi tháng chi $200+ cho Claude Code — đây là khoảnh khắc local agentic coding thực sự viable, không phải toy demo.
Technical facts
| Property | Qwen3.6-35B-A3B |
|---|---|
| Total / active params | 35B / 3B (MoE, 256 experts, 8 routed + 1 shared) |
| Context length | 262,144 native, 1,010,000 với YaRN |
| License | Apache 2.0 |
| 2-bit GGUF size | UD-IQ2_XXS 10.8 GB · UD-IQ2_M 11.5 GB · UD-Q2_K_XL 12.3 GB |
| RAM khuyến nghị (Unsloth) | 22 GB cho 35B-A3B GGUF; 24 GB Mac cho 4-bit dynamic |
| RAM+VRAM theo quant | 3-bit 17 GB · 4-bit 23 GB · 6-bit 30 GB · 8-bit 38 GB · BF16 70 GB |
| Backend hỗ trợ | llama.cpp, vLLM, SGLang, KTransformers, Transformers |
| Tool calling | Cải thiện parsing nested objects; self-healing trong Unsloth Studio |
So với Gemma 4-31B và Qwen3.5
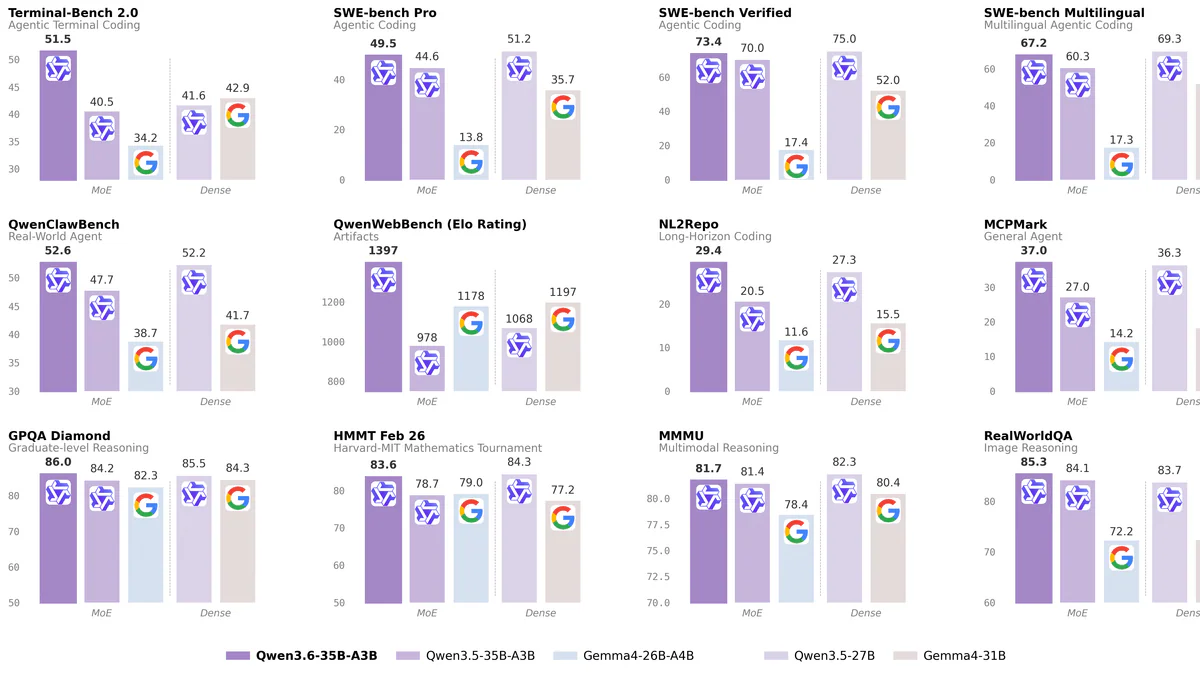
Benchmark của Alibaba (nhiều số trùng với Unsloth doc) cho thấy Qwen3.6-35B-A3B bỏ xa Gemma 4-31B trên các task agentic coding, dù active param chỉ bằng ~1/10:
| Benchmark | Qwen3.6-35B-A3B | Gemma4-31B | Qwen3.5-35B-A3B |
|---|---|---|---|
| SWE-bench Verified | 73.4 | 52.0 | 70.0 |
| SWE-bench Pro | 49.5 | 35.7 | 44.6 |
| SWE-bench Multilingual | 67.2 | 51.7 | 60.3 |
| Terminal-Bench 2.0 | 51.5 | 42.9 | 40.5 |
| QwenWebBench (Elo) | 1397 | 1197 | 978 |
| AIME 26 (math) | 92.7 | 89.2 | — |
| MMLU-Pro | 85.2 | 85.2 | 85.3 |
Bước nhảy so với Qwen3.5-35B-A3B cũng đáng kể: +11 điểm Terminal-Bench, +419 điểm QwenWebBench Elo. Trên vision-language, Qwen3.6 match Claude Sonnet 4.5 và vượt nó ở spatial intelligence (RefCOCO 92.0, ODInW13 50.8).
Use case thực tế
- Repo bug hunt + PR draft (chính demo này): agent tự đi qua code, thu evidence, repro lỗi, viết fix, viết test, draft PR writeup.
- Terminal agent với Qwen Code / Codex / OpenCode nhờ Developer Role Support mới.
- Frontend workflow + repo-level reasoning — điểm mạnh nhất của Qwen3.6 theo blog chính thức.
- Ingest cả codebase vào prompt — 262K context native đủ cho phần lớn monorepo vừa.
- Self-host cho enterprise — Apache 2.0 + MoE efficient = chi phí inference thấp, không leak data.
Limitations & pricing
- Giá: 0đ. Weights Apache 2.0. Unsloth Studio UI AGPL-3.0.
- Chưa chạy được trên Ollama do Qwen3.6 GGUF dùng file
mmprojvision tách rời. Dùng llama.cpp-compatible backend (Unsloth Studio, llama.cpp, vLLM, SGLang, KTransformers). - Không dùng CUDA 13.2 — gây output gibberish. NVIDIA đang fix.
- Static YaRN áp hằng số scaling → có thể giảm chất lượng với prompt ngắn; chỉ bật khi thực sự cần >262K token.
- Nếu RAM+VRAM < model size, llama.cpp sẽ offload SSD/HDD — chạy được nhưng chậm đáng kể.
- "13 GB RAM" trong tweet là ước lượng sát với file 2-bit (10.8–12.3 GB). Unsloth khuyến nghị tối thiểu 22 GB để dư chỗ cho context + OS.
What's next
Unsloth confirm sẽ release Unsloth Studio desktop app trong tháng 4/2026 (hiện chỉ có web UI). Training support cho Apple MLX, AMD, Intel "sắp ra", multi-GPU đang có upgrade lớn. Phía Qwen team chuẩn bị open-source QwenClawBench — benchmark agent theo phân phối user thật.
Muốn nghịch thử ngay:
- Cài Unsloth Studio (GitHub).
- Search
qwen3.6trong Studio → tảiUD-IQ2_M(11.5 GB) nếu RAM ~16 GB, hoặcUD-Q4_K_XL(22 GB) nếu có 24 GB Mac / 24 GB VRAM. - Bật tool calling, paste repo vào chat, nói "hunt bugs, propose fixes with tests".
Nguồn: Unsloth HF discussion, Unsloth docs, Qwen model card, OfficeChai, tweet gốc.