
- Alibaba vừa phát hành Qwen3.6-27B — dense model open-weight 27B tham số, Apache 2.0, 262K context native, multimodal, và đạt SWE-bench Verified 77.2 — chỉ cách Claude 4.5 Opus 3.7 điểm trong khi chạy được trên GPU 18GB.
TL;DR
Ngày 22/04/2026, đội Qwen (Alibaba) phát hành Qwen3.6-27B — dense model 27B tham số, open-weight, Apache 2.0, multimodal, native 262K context (extend lên 1M qua YaRN). Đáng chú ý: mô hình này vượt qua flagship cũ Qwen3.5-397B-A17B (MoE) trên hầu hết benchmark coding, và chỉ kém Claude 4.5 Opus 3.7 điểm trên SWE-bench Verified (77.2 vs 80.9). Chạy được trên GPU 18GB ở bản Q4, zero API fee.
Có gì mới
Qwen3.6-27B là dense model đầu tiên trong gia đình Qwen3.6 — khác với tiền nhiệm Qwen3.5-397B dùng kiến trúc Mixture-of-Experts. Toàn bộ 27B tham số active trên mỗi lần inference, giúp routing đơn giản hơn và latency ổn định hơn cho agentic workflow.
- Dense 27B, 64 layers, hidden dim 5,120
- Hybrid attention: tỉ lệ 3:1 giữa Gated DeltaNet (linear attention) và Gated Attention chuẩn
- Context native 262,144 tokens, mở rộng 1,010,000 qua YaRN
- Multimodal: vision encoder built-in, input ảnh + text
- Thinking Preservation: cờ
preserve_thinking: Truegiữ lại reasoning trace giữa các turn, cắt redundant reasoning, tận dụng KV cache - Multi-Token Prediction cho speculative decoding
- Apache 2.0
Vì sao quan trọng
Trước đây để đạt flagship-level coding phải dùng Claude Opus (API) hoặc MoE hàng trăm tỉ tham số (Qwen3.5-397B cần 807GB disk, infra multi-node). Qwen3.6-27B nén câu chuyện đó xuống 55.6GB BF16 hoặc 16.8GB Q4_K_M — chạy được trên một card RTX 4090 đơn lẻ. Với dev có codebase nhạy cảm hoặc team muốn thoát API cost, đây là lần đầu tiên open model thật sự là drop-in replacement cho Claude Code ở tác vụ coding hàng ngày.
Technical facts
Kiến trúc lõi: 16 block lặp lại pattern 3 × (Gated DeltaNet → FFN) → 1 × (Gated Attention → FFN). Linear attention gánh đa số chi phí, attention chuẩn xen vào để giữ precision ở long context.
| Property | Qwen3.6-27B | Qwen3.5-397B-A17B (prev flagship) |
|---|---|---|
| Architecture | Dense | MoE (17B active / 397B total) |
| Active params | 27B | 17B |
| Disk size (BF16) | 55.6 GB | 807 GB |
| Native context | 262,144 | 262,144 |
| Multimodal | Yes | No |
| License | Apache 2.0 | Apache 2.0 |
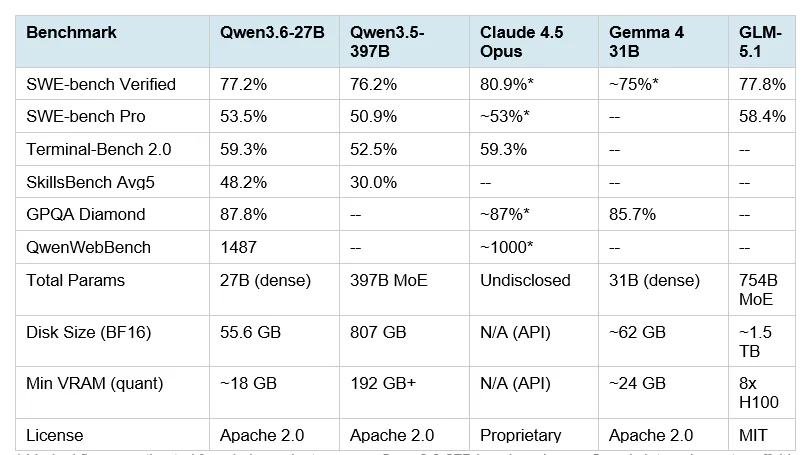
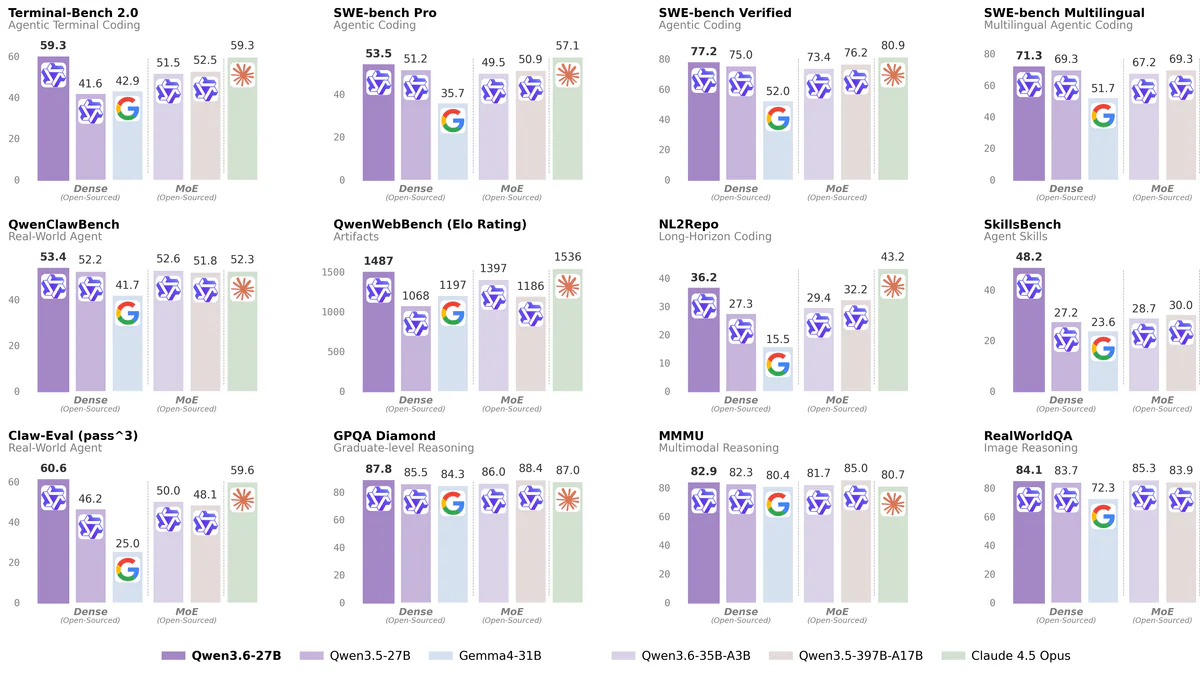
Benchmark khác đáng chú ý: GPQA Diamond 87.8, AIME26 94.1, LiveCodeBench v6 83.9, VideoMME 87.7, AndroidWorld 70.3. Simon Willison test local qua llama.cpp: ~24-25 tokens/s generation, 54 tokens/s prompt reading trên bản GGUF 16.8GB.
So sánh Claude 4.5 Opus & Qwen3.5-397B
| Benchmark | Qwen3.6-27B | Qwen3.5-397B | Claude 4.5 Opus |
|---|---|---|---|
| SWE-bench Verified | 77.2 | ~50-60 | 80.9 |
| SWE-bench Pro | 53.5 | 50.9 | — |
| Terminal-Bench 2.0 | 59.3 | — | 59.3 |
| SkillsBench Avg5 | 48.2 | 30.0 | — |
| QwenWebBench (Elo) | 1487 | 1397 | — |
| NL2Repo | 36.2 | 27.3 | — |
Headline: 27B dense ngang bằng Claude 4.5 Opus trên Terminal-Bench 2.0 và vượt flagship MoE 397B tiền nhiệm dù có ít hơn 14.8× tham số. SkillsBench cải thiện tương đối 77% so với Qwen3.5-27B.
Use cases thực tế
- Self-hosted coding agent: plug vào Claude Code, OpenCode, Cursor qua local relay OpenAI-compatible — zero API fee
- Codebase nhạy cảm: phân tích repo proprietary mà không gửi qua cloud
- Long-context repo reasoning: đọc toàn bộ monorepo trong 1M token context
- Multi-turn agentic workflow: Thinking Preservation cắt overhead giữa các step
- Frontend dev: Qwen team nhấn mạnh mảng UI code — benchmark QwenWebBench leader board đạt 1487 Elo
- Production serving: SGLang hoặc vLLM cho multi-user team
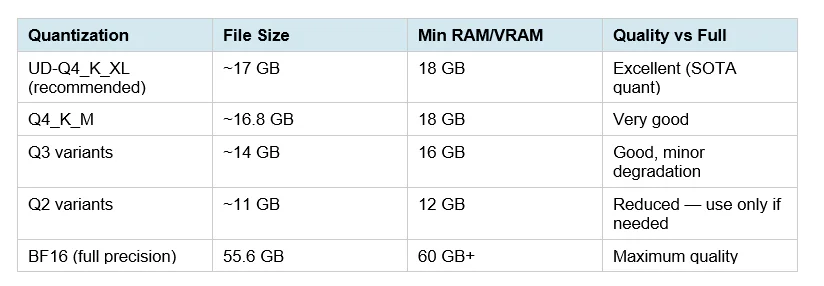
Limitations & pricing
- Giá: free self-host (Apache 2.0). API optional qua Alibaba DashScope và OpenRouter
- Vẫn kém Claude Opus 4.6/4.7 trên SWE-bench Verified
- Chưa support Ollama — file mmproj vision chưa tương thích
- CUDA 13.2 bị bug — sinh output gibberish, cần tránh version này
- Team Qwen khuyến cáo giữ context ≥128K để preserve thinking capability
- Multi-GPU (8 GPU tensor parallel) được khuyến nghị cho bản BF16 full
- Third-party benchmark verify trên production coding thật sự còn hạn chế (mới ra 1-2 ngày)
Điều gì tiếp theo
Qwen team đồng thời phát hành bản MoE anh em Qwen3.6-35B-A3B cho agentic coding với 3B active params — chạy nhẹ hơn nữa. Roadmap ngắn hạn là thêm variants trong gia đình 3.6 và mở rộng vision + agentic capability. Với license Apache 2.0, cộng đồng mong chờ fine-tune chuyên ngành (med, finance, legal coding) xuất hiện nhanh trong vài tuần tới.
Nguồn: Qwen blog, Hugging Face, Simon Willison, MarkTechPost.

