
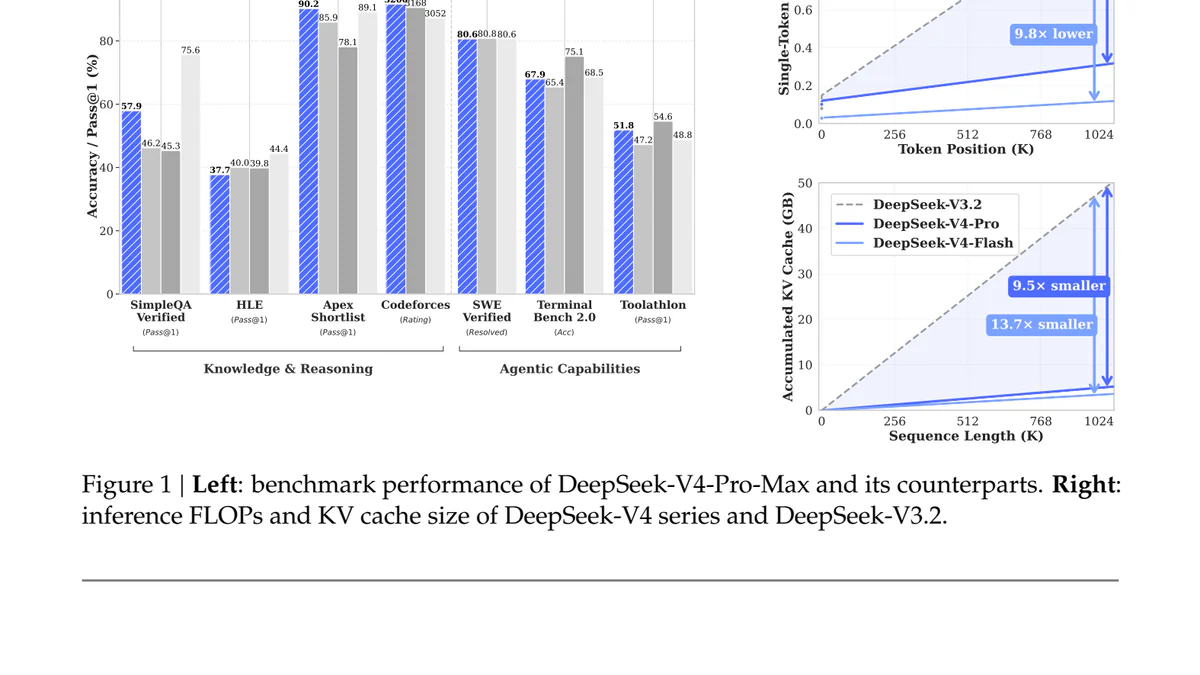
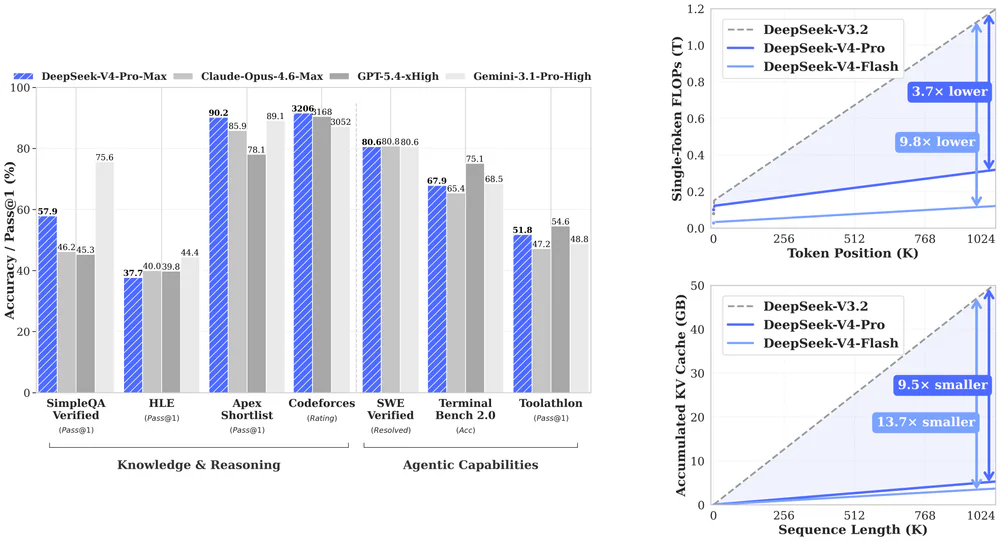
- V4-Pro vượt Opus 4.6 trên Terminal-Bench, gần bằng Gemini 3.1 Pro trên mọi benchmark, nhưng điểm đáng kể nhất là KV cache chỉ còn 10% so với V3.2 ở context 1M.
- Với GPU cố định, cùng một rack GB300 giờ có thể phục vụ gấp 10 lần số request concurrent.
- Đây là đóng góp nghiêm túc nhất cho kinh tế inference long-context năm 2026.
TL;DR
DeepSeek vừa preview V4-Pro (1.6T params / 49B active MoE) và V4-Flash (284B / 13B active) vào 24/04/2026 — cả hai đều hỗ trợ context 1M token, open weights MIT. V4-Pro vượt Opus 4.6 trên Terminal-Bench 2.0 (67.9 vs 65.4) và gần ngang các mô hình đóng trên SWE Verified. Nhưng điểm đáng nhớ nhất là: ở context 1M, V4-Pro chỉ cần 27% FLOPs per-token và 10% KV cache so với V3.2. V4-Flash còn gắt hơn — chỉ 7% KV cache. Với decode memory-bound trên HBM hạn chế, đây là cú giải quyết cơn khát phần cứng.
Có gì mới
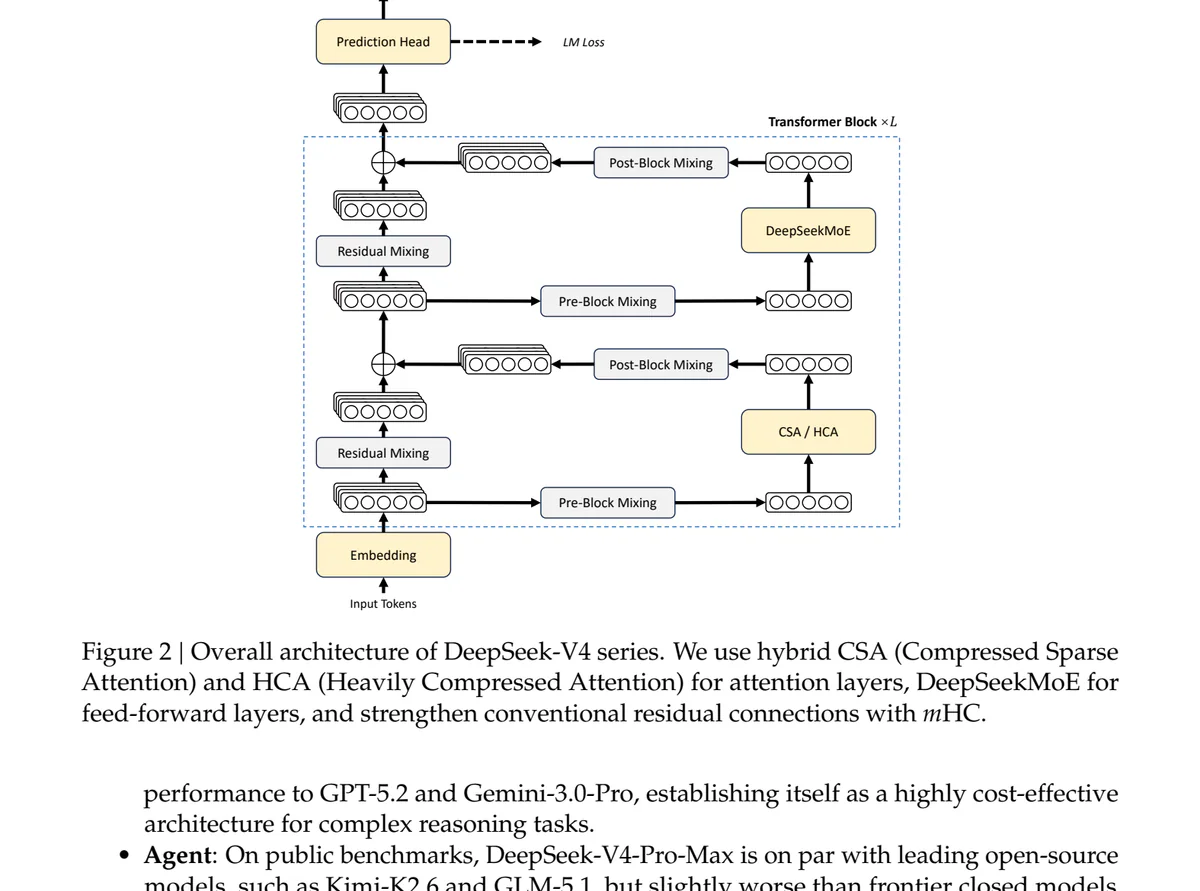
Kiến trúc V4 là cú tái thiết kế attention nhằm trực tiếp vào bottleneck KV cache:
- CSA (Compressed Sparse Attention): nén 4x qua softmax-gated pooling, có lightning indexer FP4 chọn top-k block, kèm nhánh sliding-window cho token gần.
- HCA (Heavily Compressed Attention): nén 128x, dense MQA trên block đã nén — không cần sparse select vì sequence đã đủ ngắn.
- 61 layer: layer 0-1 HCA, 2-60 xen kẽ CSA/HCA, MTP block cuối chỉ sliding-window.
- KV lưu FP8, riêng chiều RoPE giữ BF16, indexer FP4.
- MoE experts quantize FP4, phần còn lại FP8 trong checkpoint instruct.
So với GQA chuẩn (8-head, BF16), V4 chỉ cần ~2% KV cache.
Vì sao điều này quan trọng
Decode khác Prefill: memory-bound, không phải compute-bound. HBM còn lại trên mỗi GPU quyết định batch size tối đa, và batch size quyết định số request đồng thời phục vụ được. Trên rack GB300 NVL72 chạy DEP16 (Data + Expert Parallelism 16 GPU) với V3.2, sau khi load weights MoE dạng NVFP4, mỗi GPU còn ~176GB HBM trống. Tính toán KV cache per request:
| Context | KV cache / request (V3.2) | Concurrent requests (176GB) |
|---|---|---|
| 128K | 4.45 GB | ~36 |
| 256K | 8.90 GB | ~18 |
| 512K | 17.80 GB | ~9 |
| 1M | 35.60 GB | ~4 |
Giờ hãy tưởng tượng KV cache giảm 10 lần ở 1M — cùng một rack có thể phục vụ ~40 request đồng thời thay vì 4. Đó là lý do cộng đồng infra gọi đây là đóng góp quan trọng nhất của V4: nó không chỉ mở rộng context, nó biến 1M context từ thứ không kinh tế thành thứ serve được ở quy mô thật.
Số liệu kỹ thuật
- V4-Pro: 1.6T params, 49B active, train trên 33T token, checkpoint 865GB.
- V4-Flash: 284B params, 13B active, 32T token, 160GB.
- Context 1M input, output tối đa 384K.
- Ở 1M context so với V3.2: V4-Pro dùng 27% FLOPs + 10% KV cache; V4-Flash 10% FLOPs + 7% KV cache.
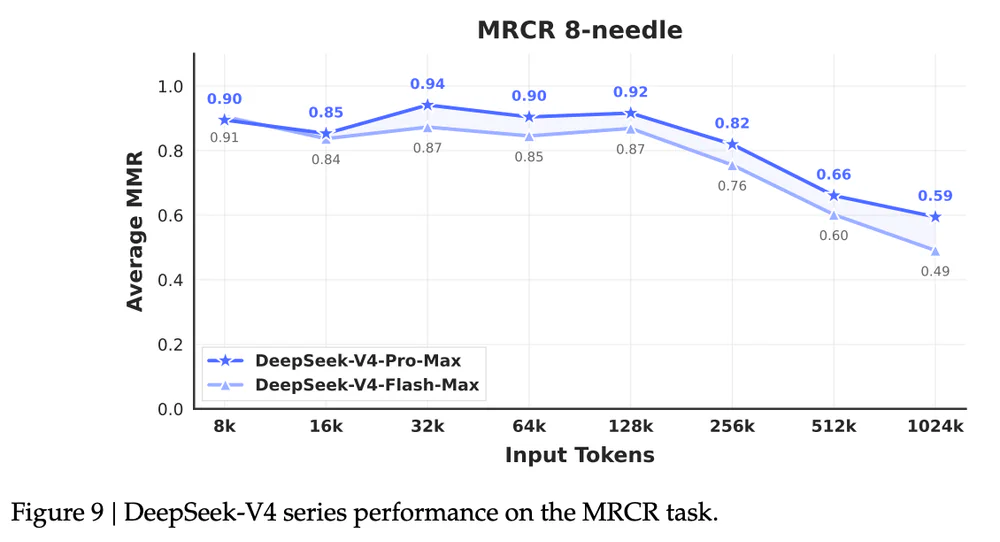
- Long-context retrieval (MRCR 8-needle): 0.82 ở 256K, 0.59 ở 1M.
- CorpusQA ở 1M: V4-Pro 62.0 vs Gemini 3.1 Pro 53.8.
- Tool-call schema mới: token
|DSML|bao XML (ít fail escape hơn JSON). - Interleaved thinking giữ nguyên reasoning trace xuyên qua tool call.
- DSec Sandbox: Rust, hỗ trợ function call, container, Firecracker microVM, QEMU VM cho RL training.
So với frontier
| Benchmark | V4-Pro | GPT 5.4 | Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 |
| SWE Verified | 80.6 | — | 80.8 | 80.6 |
| MCPAtlas Public | 73.6 | — | 73.8 | — |
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 |
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
V4-Pro vượt Opus 4.6 trên Terminal-Bench 2.0 đúng 2.5 điểm — benchmark 3 giờ chạy thật trên terminal, gap này quan trọng hơn vài điểm coding single-turn. SWE Verified thì sai lệch dưới 0.2 điểm với Opus và Gemini. Reasoning thuần vẫn kém GPT-5.4 và Gemini 3.1 Pro — Simon Willison gọi đây là khoảng cách 3-6 tháng.
Ai hưởng lợi
- Agent long-context: multi-hour autonomous tool use (Terminal-Bench 2.0 có timeout 3 giờ).
- Code review repo-wide: quét 500K-1M token codebase thay vì chunk nhỏ.
- RAG pipeline: bỏ bớt tầng chunking hung bạo, đẩy thẳng document gốc.
- On-prem / self-host: nơi HBM là ràng buộc cứng — giờ cùng rack phục vụ được gấp 10.
- Cost-sensitive prod: V4-Pro giá $1.74 in / $3.48 out per 1M token — chỉ bằng 1/3 input và 1/7 output của Opus 4.6.
Giới hạn & giá
- Reasoning thuần vẫn sau GPT-5.4 và Gemini 3.1 Pro khoảng 3-6 tháng.
- MRCR 1M chỉ 0.59 — long-context retrieval chưa "giải xong", mới ở mức dùng được.
- Chế độ "Think Max" yêu cầu context ≥384K, không phù hợp deployment nhỏ.
- V4-Pro 865GB — self-host cần 4x H100/H200 hoặc rack GB200/GB300.
- Trạng thái Preview — SLA production và fine-tuning recipe sẽ đến sau.
Giá per 1M token:
| Model | Input (cache miss) | Input (cache hit) | Output |
|---|---|---|---|
| V4-Flash | $0.14 | $0.028 | $0.28 |
| V4-Pro | $1.74 | $0.145 | $3.48 |
| GPT 5.4 | $2.50 | — | $15.00 |
| Opus 4.6 | $5.00 | — | $25.00 |
Bước tiếp theo
Đây mới là bản preview. Phát hành chính thức sẽ đi kèm giá production, recipe fine-tuning, và có lẽ một bản distill 30-70B cho single-GPU. Tin đồn về V4-Pro-Max (expanded reasoning tokens) cho thấy DeepSeek đang nhắm đến tier premium ngang GPT-5.4 / Opus-Max. Điểm rộng hơn: open-weight giờ đã trong khoảng 3-6 tháng so với frontier, với giá output chỉ bằng 1/7 Opus. Áp lực lên pricing của OpenAI và Anthropic chắc chắn còn tiếp diễn.
Nguồn: Simon Willison, Hugging Face Blog, OfficeChai, @bookwormengr trên X.

