
TL;DR
DeepSeek V4 ship ngày 24/04/2026, đúng ngày OpenAI ra GPT-5.5 — một nước đi chia news cycle có tính toán. Hai biến thể MoE mở trọng số Apache 2.0: V4-Pro (1.6T tổng, 49B active) và V4-Flash (284B tổng, 13B active). Cả hai hỗ trợ 1M token context, output tối đa 384K.
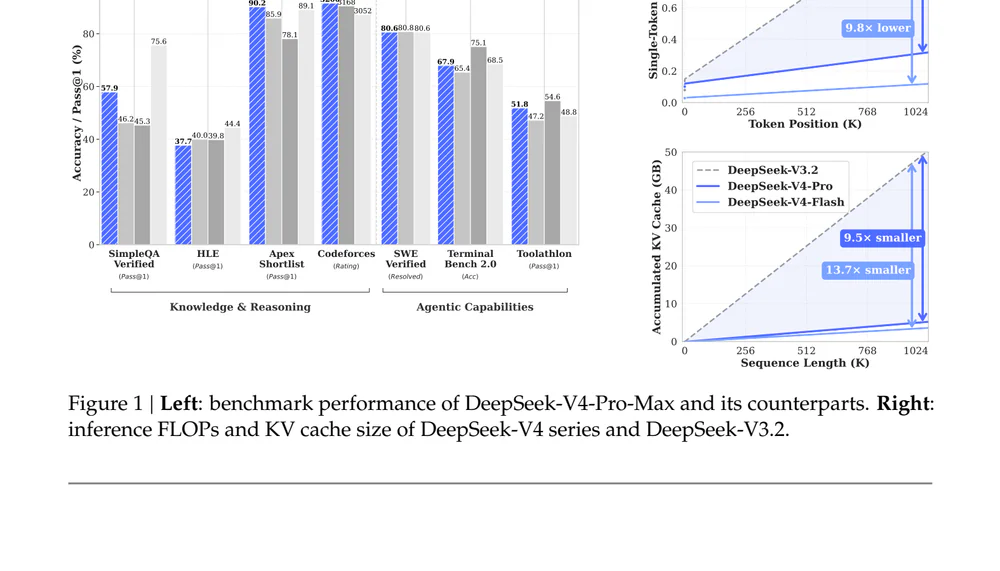
Benchmark không phải all-round SOTA. Điểm đáng giá là chi phí inference long-context: ở 1M token, V4-Pro chỉ cần 27% FLOPs và 10% KV cache so với V3.2. V4-Flash còn gắt hơn: 10% FLOPs, 7% KV cache. Đây là bài giải cho vấn đề agent "stop rồi reprompt" mà ai xài non-Opus cũng gặp.
What's new
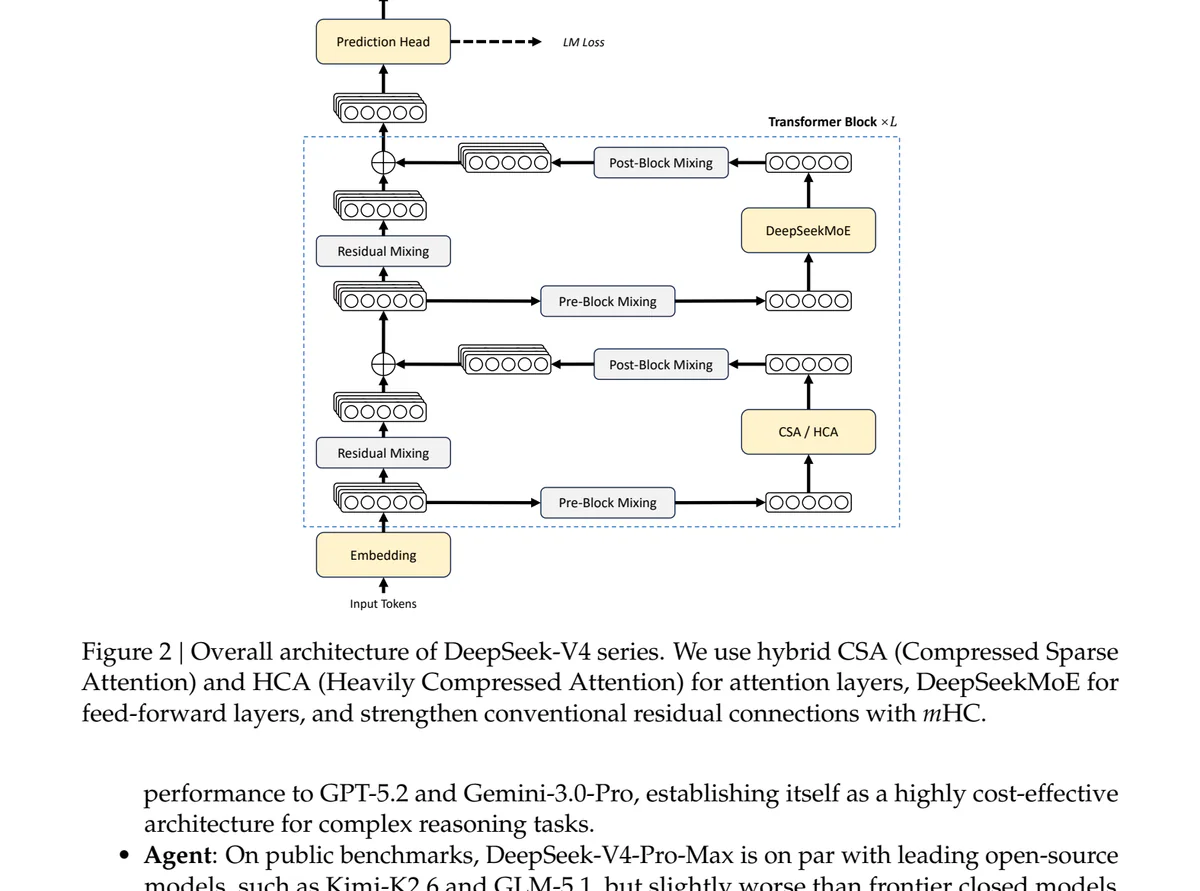
DeepSeek không chạy đua benchmark absolute; họ đánh thẳng vào chi phí attention ở context dài. Cửa sổ 1M chỉ có giá trị khi mỗi token không biến thành hóa đơn KV cache. V4 đạt điều đó bằng hybrid attention CSA + HCA xen kẽ qua các layer, cộng với Manifold-Constrained Hyper-Connections (mHC) thay cho residual truyền thống, và train bằng Muon optimizer.
- CSA (Compressed Sparse Attention): nén 4× theo chiều sequence — một token nén là tổng có trọng số của 8 token gốc, stride 4. Kèm lightning indexer FP4 chọn top-k block nén + sliding window 128 token cho context cục bộ.
- HCA (Heavily Compressed Attention): nén 128× (1 token = 128 token gốc, stride 128), bỏ sparse selection, dense attention trên chuỗi đã nén.
- Layout 61 layer (V4-Pro): layer 0–1 HCA, layer 2–60 xen kẽ CSA/HCA, MTP block cuối chỉ sliding-window.
- Storage: FP8 cho phần lớn KV, BF16 chỉ cho chiều RoPE, FP4 cho lightning indexer. MoE expert FP4, còn lại FP8.
Pre-train trên 32T+ token với mixed precision FP4+FP8. Weights đã lên Hugging Face với 4 checkpoint (Pro, Pro-Base, Flash, Flash-Base).
Why it matters
Vấn đề cốt lõi với agent long-horizon không phải "model ngu" — là context budget và KV cache OOM. Mỗi lần tool trả kết quả, context phình ra; mỗi token mới phải attend ngược về toàn bộ lịch sử. Trace dài vài trăm command là chết GPU memory, hoặc model stop giữa chừng và bạn phải reprompt.
V4 cắt KV cache còn 9.62 GiB per sequence ở 1M context (bf16) — nhỏ hơn 8.7× so với ~83.9 GiB của stack kiểu V3.2. Dùng fp4 indexer + fp8 cache thì nhỏ thêm ~2× nữa. So với GQA-8 bf16 baseline chỉ còn ~2% cache size. Tức là cùng 1 GPU bạn đột nhiên fit được context gấp 10 lần, hoặc tăng concurrency tương đương.
Technical facts
Ở 1M token, so với V3.2:
| Metric | V4-Pro | V4-Flash |
|---|---|---|
| Per-token FLOPs | 27% | 10% |
| KV cache memory | 10% | 7% |
| Total params | 1.6T | 284B |
| Active params | 49B | 13B |
| Context | 1M | 1M |
| Max output | 384K | 384K |
Post-training cho agent có 3 thay đổi đáng chú ý:
- Interleaved thinking across tool calls: V3.2 xóa reasoning trace mỗi khi user gửi message mới — sai cho multi-turn agent workflow. V4 giữ toàn bộ chain-of-thought qua các user turn khi cuộc hội thoại có tool call, flush reasoning chỉ khi chat thuần không tool.
- Tool-call schema dedicated token
|DSML|: format XML thay JSON-trong-string, tách string param (string="true") khỏi structured param, giảm lỗi parse quanh nested quoting và numbers/booleans. - DSec sandbox: platform Rust chạy 100K+ microVM Firecracker + QEMU full VM đồng thời, dùng cho RL rollout huấn luyện behavior agent trên tool environment thật.
Comparison
Agent benchmarks (V4-Pro-Max vs frontier):
| Benchmark | V4-Pro-Max | K2.6 Thinking | Opus 4.6 | GPT-5.4 xHigh | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| Terminal-Bench 2.0 | 67.9 | 66.7 | — | 75.1 | 68.5 |
| SWE-Bench Verified | 80.6 | — | 80.8 | — | 80.6 |
| MCPAtlas Public | 73.6 | 66.6 | 73.8 | 67.2 | 69.2 |
| LiveCodeBench | 93.5 | 89.6 | 88.8 | — | 91.7 |
| Codeforces | 3206 | — | — | 3168 | 3052 |
| Chinese-SimpleQA | 84.4 | 75.9 | 76.2 | 76.8 | 85.9 |
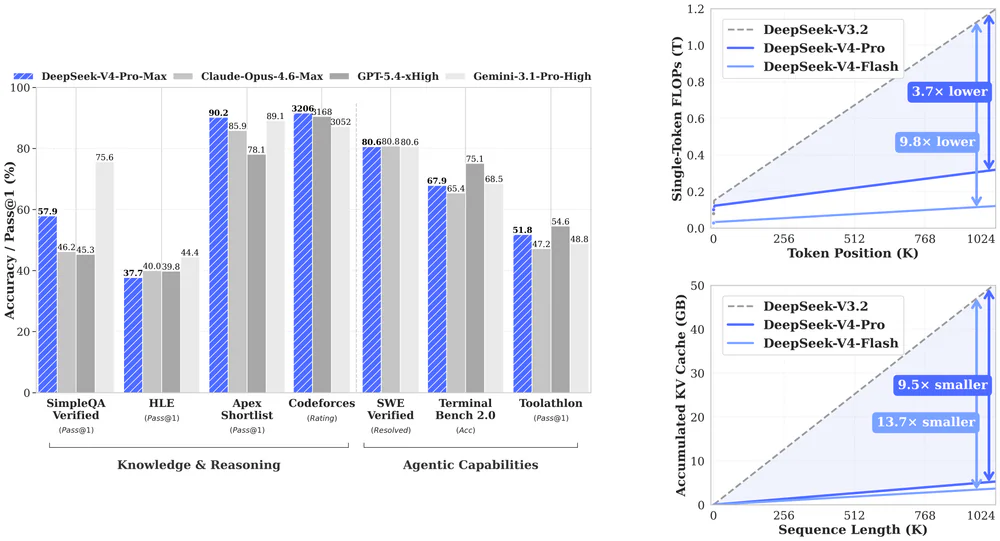
Nơi V4-Pro vẫn thua: MRCR 1M (83.5 vs Opus 92.9), CorpusQA 1M (62.0 vs Opus 71.7), GDPval-AA Elo (1554 vs GPT-5.4's 1674), SWE-Bench Pro (55.4 vs Kimi K2.6's 58.6). Nhận định thẳng thắn từ cộng đồng: "1M context là thật, nhưng retrieval quality tuyệt đối vẫn thua Opus. Chiến thắng của V4 là hiệu quả, không phải accuracy tối đa."
Use cases
- Agent long-horizon: SWE-bench task, terminal session vài trăm command, multi-step browse — V4 giữ state không bị OOM, interleaved thinking giữ reasoning cumulative qua user turn.
- Whole-repo code understanding: truyền nguyên codebase 500+ file vào prompt, bỏ bớt RAG pipeline phức tạp.
- Document discovery quy mô lớn: 1M token ≈ 15–20 tiểu thuyết — nuốt nguyên bộ tài liệu pháp lý/y tế/tài chính trong một pass. Có caveat: retrieval chính xác giảm ở extreme context.
- Sản phẩm Chinese-first: 84.4 Chinese-SimpleQA — open-weight đầu tiên parity với closed frontier cho tiếng Trung.
Limitations & pricing
Trade-off của compression mạnh: MRCR 8-needle accuracy giữ trên 0.82 đến 256K token nhưng rớt xuống 0.59 ở 1M — "needle in haystack" thất bại khi stress test extreme context. Stay on closed frontier (GPT-5.5 / Opus 4.7) nếu tác vụ cần retrieval tuyệt đối ở scale triệu token, GDPval-grade knowledge work, hoặc terminal agent (GPT-5.5 Terminal-Bench 82.7% đứng riêng một tier).
Serving requirements: V4-Pro cần 8×B200/B300 single node; Flash fit 4×B200/B300.
API pricing (per 1M token):
| Model | Input miss | Input hit | Output |
|---|---|---|---|
| V4-Pro | $1.74 | $0.145 | $3.48 |
| V4-Flash | $0.14 | $0.028 | $0.28 |
V4-Pro output 8.6× rẻ hơn GPT-5.5 ($30) và 21× rẻ hơn Opus 4.7 ($75). Flash $0.28 output gần như free. License upgrade từ MIT lên Apache 2.0 — có patent grant rõ ràng, commercial deploy không vướng.
What's next
24/07/2026: deepseek-chat và deepseek-reasoner bị deprecate (hiện route tạm về V4-Flash). Model R2 (next-gen reasoning) được báo cáo delay do Bắc Kinh thúc ép DeepSeek chuyển sang domestic silicon — V4-Pro theo báo cáo đã train hoàn toàn trên Huawei Ascend 910B + Cambricon MLU, lần đầu một frontier model train không cần NVIDIA.
vLLM đang làm thêm DeepGEMM MegaMoE kernel và Paged prefill kernel. Chinese silicon đã được support qua vllm-ascend và vllm-mlu.
Nguồn: Hugging Face — DeepSeek-V4 blog post, vLLM — DeepSeek V4 integration, NxCode specs & benchmarks, WCCFTech — trade-off analysis.