
- Ngày 24/04/2026, DeepSeek tung bản preview V4 — hai biến thể MoE (Pro 1.6T/49B active và Flash 284B/13B active), cùng context 1M token tiêu chuẩn, đè bẹp Claude Sonnet 4.5 trong agentic coding và bán API rẻ hơn GPT-5.5 tới 8.6 lần.
TL;DR
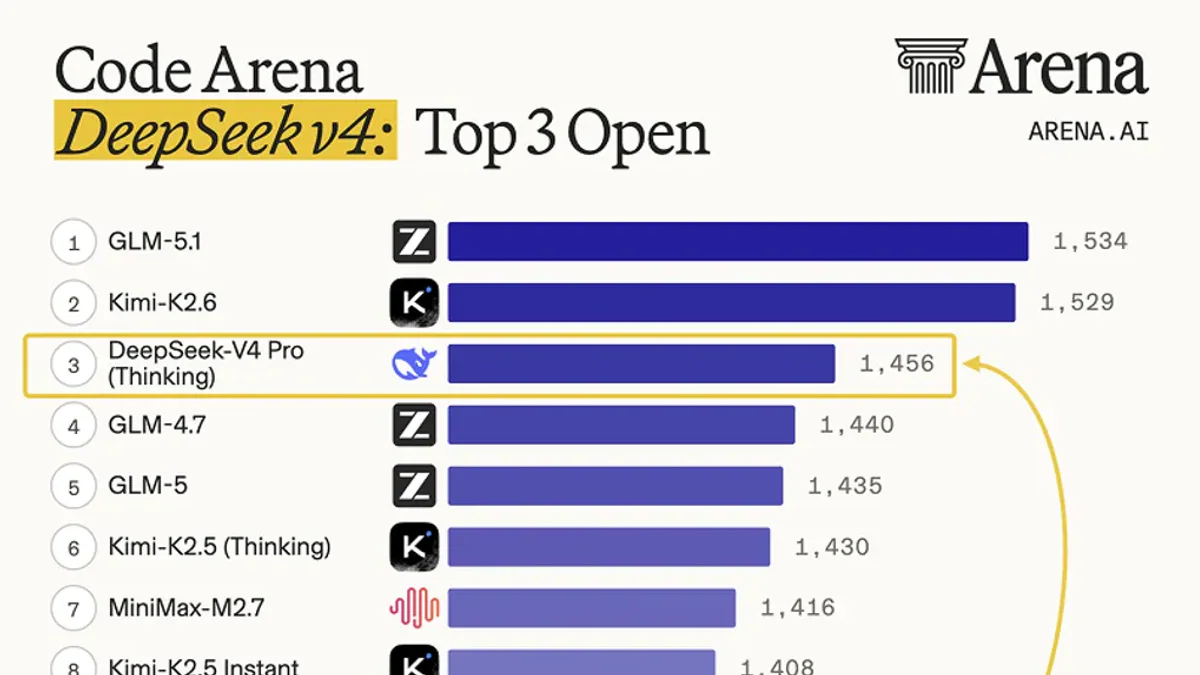
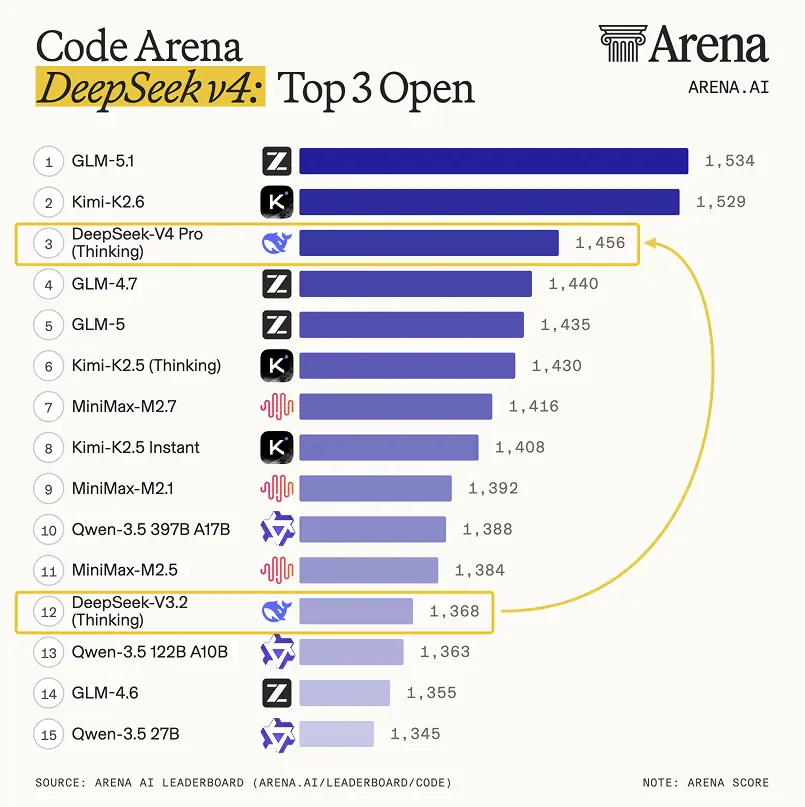
DeepSeek vừa thả bản preview V4 ngay trong ngày OpenAI ship GPT-5.5 — và đây không phải bản refresh. Hai model MoE mã nguồn mở: V4-Pro (1.6T tổng / 49B active) và V4-Flash (284B / 13B active), cả hai đều mặc định context 1 triệu token. V4-Pro đứng #3 trên Arena AI Code Leaderboard (Elo 1456, nhảy 88 điểm so với V3.2), đạt 3206 Codeforces — vượt GPT-5.4 (3168) — và có chất lượng agentic coding vượt Claude Sonnet 4.5. Output API V4-Pro $3.48/M token, rẻ hơn GPT-5.5 ~8.6 lần và Opus 4.7 ~21 lần. Trọng số đã có trên Hugging Face, API live ngay, deepseek-chat & deepseek-reasoner cũ sẽ bị retire vào 24/07/2026.
Có gì mới
Công bố chính thức ngày 24/04/2026 trên kênh @deepseek_ai. Series V4 gồm hai biến thể, đều là MoE huấn luyện riêng (Flash không phải bản trim của Pro):
- DeepSeek-V4-Pro: 1.6T tổng tham số, 49B active. Pre-train trên 33T token. Định vị flagship — agent capability mạnh nhất, world knowledge sâu, dùng cho task khó.
- DeepSeek-V4-Flash: 284B tổng / 13B active. Pre-train trên 32T token. Định vị tiết kiệm — reasoning gần Pro nhưng nhanh và rẻ hơn nhiều.
Cả hai chia sẻ: context 1M token, output tối đa 384K, hỗ trợ hai chế độ Thinking / Non-Thinking với ba mức effort (high / max / non-think), JSON output, Tool Calls, Chat Prefix Completion. Kiến trúc dùng FP4+FP8 mixed precision (MoE expert ở FP4).
Trọng số đã đẩy lên Hugging Face (deepseek-ai/DeepSeek-V4-Pro và DeepSeek-V4-Flash) và mirror ModelScope. API live cùng ngày — giữ nguyên base_url, chỉ đổi model_name. Hỗ trợ song song giao thức OpenAI ChatCompletions và Anthropic.
Vì sao đáng quan tâm
Có ba điểm phá vỡ cân bằng thị trường:
- 1M context trở thành tiêu chuẩn, không phải premium. Trước đây các provider thường cap context ở 128K hoặc charge phụ phí. DeepSeek bật mặc định 1M cho cả Pro lẫn Flash, kèm cải tiến kiến trúc khiến chi phí inference giảm theo đơn vị bậc — chứ không phải theo phần trăm.
- Open-weight đầu tiên thực sự ngang frontier ở agentic coding. V4-Pro vượt Claude Sonnet 4.5 và tiệm cận Opus 4.6 non-thinking trong delivery quality. DeepSeek công khai dùng nó làm tool agentic coding nội bộ.
- Cú đập giá tiếp theo. Khi R1 hạ giá output 90% so với o1, OpenAI buộc phải mở model cao cấp cho free tier. V4-Pro $3.48/M output đặt áp lực tương tự lên GPT-5.5 ($30) và Opus 4.7 (~$75 — rẻ hơn 21 lần).
Kỹ thuật cốt lõi
Điểm bật nhất là cơ chế attention mới — DSA (DeepSeek Sparse Attention): kết hợp Compressed Sparse Attention (CSA) và Heavily Compressed Attention (HCA), nén ở cấp token. Thêm Manifold-Constrained Hyper-Connections (mHC) cho residual và Muon optimizer cho training stability.
So với V3.2 ở context 1M, V4-Pro chỉ cần:
- 27% single-token inference FLOPs
- 10% KV cache
Đây là chỉ số quyết định: KV cache chính là rào cản chi phí lớn nhất khi serve 1M-context, và DeepSeek cắt nó 10 lần. Đó là lý do họ dám bật 1M làm mặc định mà giá API vẫn dưới đối thủ.
| Model | Total params | Active | Context | Pre-train tokens |
|---|---|---|---|---|
| V4-Pro | 1.6T | 49B | 1M | 33T |
| V4-Flash | 284B | 13B | 1M | 32T |
| V3.2 (tham chiếu) | — | — | — | — |
So sánh với frontier
DeepSeek công bố grid head-to-head đầy đủ. Đọc thẳng:
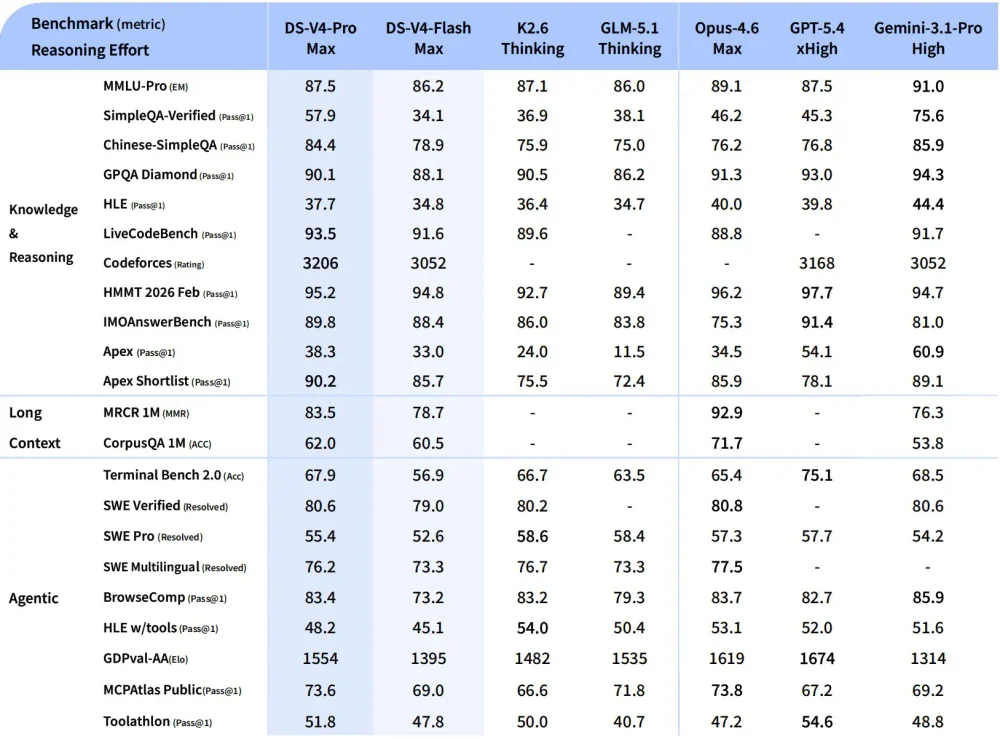
V4-Pro Max thắng tuyệt đối:
- LiveCodeBench: 93.5 vs Gemini 91.7, Opus 88.8
- Codeforces: 3206 vs GPT-5.4 3168, Gemini 3052 — vượt frontier ở vùng competitive programming
- IMOAnswerBench: 89.8 vs Opus 75.3, Gemini 81.0
- Apex Shortlist: 90.2 vs Opus 85.9, GPT-5.4 78.1
- MCPAtlas Public: 73.6 — đứng đầu mọi peer
V4-Pro thua ở đâu:
- Long-context retrieval: MRCR 1M chỉ 83.5 vs Opus 92.9. Context dài là thật, nhưng chất lượng truy hồi chưa chạm Opus.
- World knowledge: HLE 37.7 vs Gemini 44.4, SimpleQA-Verified 57.9 vs Gemini 75.6.
- SWE-Pro: 55.4 vs Kimi K2.6 58.6 — Kimi vẫn nhỉnh hơn 3 điểm ở task fix GitHub issue thực.
- GDPval-AA (giá trị kinh tế công việc tri thức): 1554 vs GPT-5.4 1674.
Cú nhảy thế hệ thấy rõ trên Arena Code Leaderboard — V4-Pro nhảy 88 Elo so với V3.2 (#12 → #3):
Use case ai dùng được
DeepSeek chỉ rõ V4 đã được tối ưu cho hệ sinh thái agent: Claude Code, OpenClaw, OpenCode, CodeBuddy. Bốn nhóm hưởng lợi rõ rệt:
- Dev & team kỹ thuật: code generation, refactoring, fix GitHub issue (SWE-Verified 80.6 — gần như ngang Opus 4.6 ở 80.8). Pro cho task khó, Flash cho prototype.
- Phân tích tài liệu dài: phân tích cả codebase, sách, paper trong một prompt — RAG dài hơi không cần chunk vỡ context.
- Ngành dữ liệu nhạy cảm (legal, healthcare, finance): trọng số mở cho phép on-prem deployment, không lock-in vendor, đáp ứng yêu cầu compliance.
- Production chat / customer support: V4-Flash $0.28/M output đưa cost-per-message về vùng budget-tier nhưng vẫn 1M context.
Giới hạn & giá API
Bảng giá chính thức (mỗi 1M token):
| Model | Input (cache hit) | Input (cache miss) | Output |
|---|---|---|---|
| V4-Flash | $0.028 | $0.14 | $0.28 |
| V4-Pro | $0.145 | $1.74 | $3.48 |
Tham chiếu nhanh: GPT-5.4 ở $2.50 in / $15 out, Opus 4.6 ở $5 in / $25 out. V4-Pro rẻ hơn 50–80% mà bench tương đương.
Limitations cần biết:
- Long-context retrieval chưa bằng Opus 4.6 (MRCR/CorpusQA chênh ~10 điểm).
- World knowledge thua Gemini 3.1 Pro rõ rệt.
- Flash giảm mạnh ở Terminal Bench (56.9 vs 67.9) và SimpleQA-Verified (34.1 vs 57.9) — tránh dùng Flash cho task cần factual recall chi tiết hoặc multi-step tool use phức tạp.
- FIM Completion (Beta) chỉ available ở non-thinking mode.
- Local deploy bản Pro yêu cầu enterprise GPU. Bản distilled FP8 cho consumer GPU (RTX 5090 32GB) sẽ do cộng đồng làm.
Truy cập: chat.deepseek.com (Pro = Expert Mode, Flash = Instant Mode), API (đổi model_name sang deepseek-v4-pro hoặc deepseek-v4-flash), trọng số trên Hugging Face.
Tiếp theo là gì
Đây mới là bản preview; DeepSeek chưa công bố ngày GA chính thức hay roadmap V5. Nhưng có một mốc cứng rất gần: 24/07/2026 — endpoint cũ deepseek-chat và deepseek-reasoner sẽ retire, mọi call tự động route sang deepseek-v4-flash (non-thinking và thinking tương ứng). Team đang chạy production trên hai endpoint cũ có 3 tháng để migrate.
Cộng đồng dự kiến đẩy ra phiên bản distilled FP8 chạy trên 32GB consumer GPU với chất lượng 75–85% V4. Hardware partner như Cambricon đã đạt Day-0 compatibility cho cả Pro và Flash qua Torch-MLU-Ops.
Câu hỏi lớn còn lại: liệu OpenAI và Anthropic có buộc phải hạ giá tier cao như cách họ đã làm sau R1, hay chấp nhận để segment dev/enterprise giá trung bình rơi về tay DeepSeek? Vài tuần tới sẽ rõ.
Nguồn: Hugging Face — DeepSeek-V4-Pro, TechNode, OfficeChai, Ofox AI, StableLearn.

