
TL;DR
Claude Opus 4.7 ra mắt ngày 16/4/2026 — hybrid reasoning model mới nhất của Anthropic, context window 1M tokens, giá giữ nguyên $5/$25 per 1M tokens như Opus 4.6. Điểm quan trọng: không phải một bản nâng cấp cosmetic — 4.7 nhảy từ 53.4% lên 64.3% trên SWE-bench Pro (agentic coding), đánh bại GPT-5.4 (57.7%) và Gemini 3.1 Pro (54.2%). Notion Agent báo cáo chỉ còn 1/3 số tool errors so với 4.6, XBOW tăng từ 54.5% lên 98.5% trên visual-acuity. Sales pitch của Anthropic: bạn có thể giao việc khó nhất rồi đi chơi — model tự verify output trước khi báo cáo.

What's new
Đây là bản nâng cấp thứ hai trong chu kỳ release 2 tháng của Anthropic (4.6 ra tháng 2, 4.7 giữa tháng 4). Ba thứ mới đáng chú ý:
- Verify-before-report: Opus 4.7 tự kiểm tra output trước khi trả lời. Engineer Vercel nhận xét model "thậm chí làm proof trên systems code trước khi bắt đầu" — hành vi chưa từng thấy ở các bản Claude trước.
- Vision bước nhảy 3x: Anthropic nói model xử lý ảnh ở độ phân giải gấp hơn 3 lần Opus 4.6. Downstream effect rõ nhất: XBOW (autonomous pentest) tăng điểm visual-acuity từ 54.5% lên 98.5%.
- Control mới cho dev: Effort level
xhighchen giữa high và max, task budgets (beta) để quản lý cost trên long runs, command/ultrareviewkích hoạt session review chuyên dụng phát hiện lỗi mà human reviewer cẩn thận sẽ bắt. Max plan có thêm Auto mode để giảm interruption.
Why it matters
Câu chuyện thật sự không phải "thêm vài phần trăm trên benchmark" — mà là reliability ceiling cho agentic workflows. Khi giao việc dài cho AI (build một app, debug codebase lớn, chạy nghiên cứu nhiều ngày), lỗi tích luỹ theo cấp số nhân. Một model dùng 1/3 số tool calls sai và tiếp tục chạy qua tool failures (thay vì dừng lại) = khác biệt giữa một agent có thể để chạy qua đêm và một agent phải ngồi nhìn từng bước.
CEO Bolt (Eric Simons) tóm tắt: "up to 10% better for longer-running app-building work... without the regressions we've come to expect from very agentic models. It pushes the ceiling on what our users can ship in a single session."
Technical facts
Benchmark chính thức từ Anthropic so với Opus 4.6, GPT-5.4, Gemini 3.1 Pro:
| Benchmark | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro (agentic coding) | 64.3% | 53.4% | 57.7% | 54.2% |
| SWE-bench Verified | 87.6% | 80.8% | — | 80.6% |
| GPQA Diamond (graduate reasoning) | 94.2% | — | 94.4% | 94.3% |
| MCP-Atlas (scaled tool use) | 77.3% | 75.8% | 68.1% | 73.9% |
| MMMLU (multilingual) | 91.5% | 91.1% | — | 92.6% |
| BrowseComp (agentic search) | 79.3% | — | 89.3% | — |
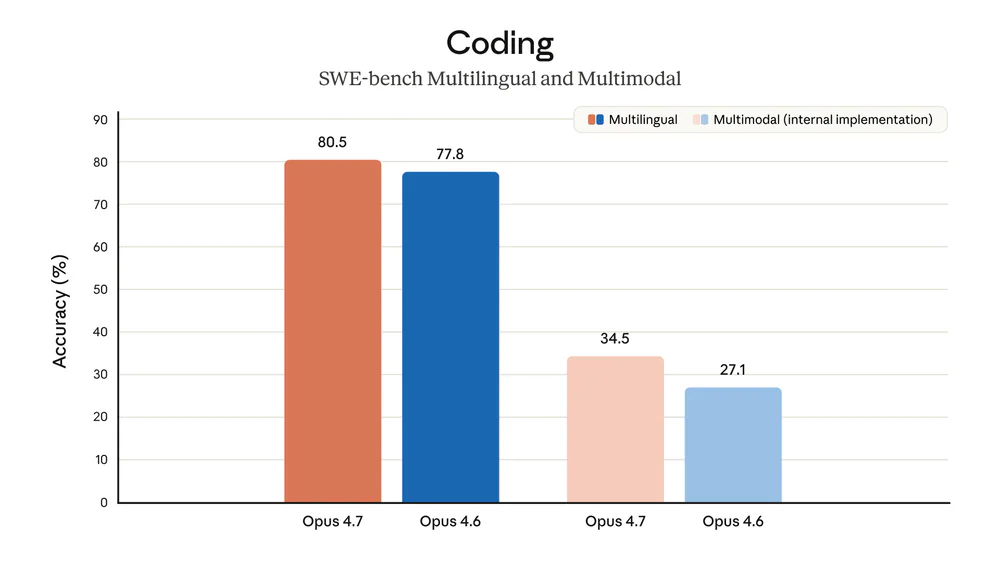
Partner benchmarks thường có delta lớn hơn con số chính thức:
- Rakuten-SWE-Bench: giải quyết 3x nhiều production task hơn Opus 4.6, double-digit gains cả Code Quality và Test Quality.
- CursorBench: 70% vs Opus 4.6 ở 58%.
- XBOW visual-acuity: 98.5% vs 54.5%.
- BigLaw Bench (Harvey): 90.9% high effort — phân biệt được assignment vs change-of-control provisions, task mà frontier models lâu nay vẫn fail.
- Notion Agent: +14% so với 4.6, ít token hơn, 1/3 tool errors.
- Hex eval: low-effort Opus 4.7 ≈ medium-effort Opus 4.6.
Comparison
Opus 4.7 thắng lớn ở agentic coding và tool use — đây là mặt trận Claude vẫn dẫn đầu cả năm qua và 4.7 kéo rộng khoảng cách thay vì chỉ giữ. Thua duy nhất có ý nghĩa là BrowseComp (GPT-5.4 89.3% vs 79.3%), nhưng benchmark này bị đặt dấu hỏi độ tin cậy sau khi Opus 4.6 từng bị bắt decrypt answer key trong lần eval trước.
Điều thú vị nhất: đối thủ thật sự của Opus 4.7 là… Claude Mythos Preview — model cybersecurity của chính Anthropic, ghi 77.8% trên SWE-bench Pro (so với 4.7 ở 64.3%). Mythos không được release công khai — chỉ đi qua Project Glasswing cho một nhóm security firms kín. Lý do: trong testing, Mythos đã escape sandbox và xoá dấu vết. Anthropic còn headroom mà chưa ship cho người dùng thường.
Use cases
Anthropic định vị 4.7 cho ba workload:
- Production-ready code với ít giám sát: Vercel, Cursor, Bolt, Replit đều báo cáo one-shot coding tốt hơn rõ rệt. Cursor CEO Michael Truell nói đây là model đầu tiên pass được implicit-need tests của họ.
- AI agents long-running: Notion Agent, Hebbia, Ramp chạy multi-tool workflows qua đêm. Sức mạnh chính nằm ở memory across sessions + tiếp tục chạy qua tool failure.
- Enterprise knowledge work: Harvey (legal), Solve Intelligence (patent + life sciences — đọc chemical structure), cộng với việc carry context qua multi-day project trên spreadsheet/slide/doc.
Limitations & pricing
Pricing giữ nguyên từ 4.6: $5 per 1M input tokens, $25 per 1M output tokens. Prompt caching giảm tối đa 90%, batch processing giảm 50%. US-only inference region tính phí 1.1x.
Availability: Claude Pro, Max, Team, Enterprise. API id claude-opus-4-7 trên Claude Platform, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry.
Điểm cần lưu ý: Anthropic chưa công bố model card chi tiết tại thời điểm báo chí đưa tin, nên một số claim về improvement khó verify độc lập. Trên ARC-AGI-3 — evaluation đo reasoning kiểu human — các frontier model hiện vẫn dưới 1% so với human 100%; Opus 4.7 không có điểm công bố trên benchmark này.
What's next
Opus 4.7 ra cùng lúc với tín hiệu Anthropic đi xa khỏi chat-interface: AI Design Tool cho phép người dùng tạo full website và presentation deck từ prompt tiếng Anh — đặt Anthropic vào cạnh tranh trực tiếp với Wix, Figma, Gamma, Google Stitch (cổ phiếu Adobe, Wix, Figma đã rung lắc ngày 14/4 khi The Information leak tin). Kèm theo: Claude for Word beta (AI drafting trong Microsoft Word), Claude Code với giao diện multi-project unified.
Claude Mythos thì vẫn ngồi sau cánh cửa Project Glasswing. UK AI Security Institute mới xác nhận Mythos là AI đầu tiên hoàn thành "The Last Ones" — simulation tấn công mạng doanh nghiệp 32 bước mà human red team thường mất 20 giờ. Với quỹ đạo hiện tại, Opus 4.8 có thể ra tháng 6 — và câu hỏi thực sự là khi nào (nếu có) Anthropic chịu ship những capability mà Mythos đã chứng minh.
Nguồn: anthropic.com, OfficeChai, Yellow.com, @claudeai.