
- Qwen3.6-27B vừa ra mắt ngày 22/04 — một dense model đánh bại Qwen3.5-397B MoE trên coding benchmark.
- Nhưng nó chạy nhanh cỡ nào trên phần cứng local?
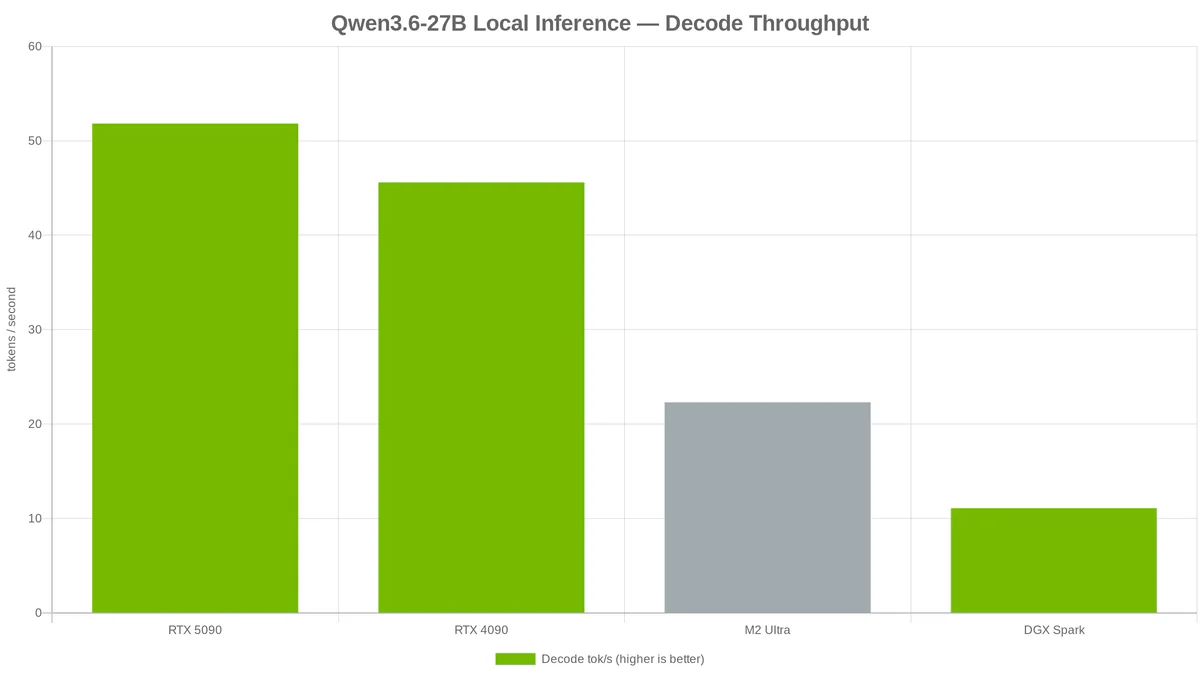
- Dev @stevibe bench 4 setup cùng lúc: RTX 5090 đạt 51.83 tok/s, M2 Ultra có TTFT thấp nhất chỉ 216ms, còn DGX Spark 128GB lại chậm bất ngờ với 11.08 tok/s.
- Bandwidth là ông vua.
TL;DR
Qwen3.6-27B — dense model 27B vừa launch 22/04/2026, đánh bại Qwen3.5-397B MoE trên SWE-bench (77.2%) và Terminal-Bench (59.3%). Dev @stevibe chạy benchmark out-of-the-box trên 4 setup phổ biến: RTX 5090 đạt 51.83 tok/s, RTX 4090 đạt 45.59 tok/s, M2 Ultra 22.30 tok/s, DGX Spark 11.08 tok/s. Điểm bất ngờ: M2 Ultra có TTFT thấp nhất (216ms) còn DGX Spark 128GB unified RAM lại chậm nhất vì bandwidth chỉ 273 GB/s.
Có gì mới
Qwen3.6-27B là dense 27B param (không phải MoE) dưới license Apache 2.0. Alibaba giảm từ 397B total param của Qwen3.5 xuống 27B nhưng vẫn giữ hiệu năng flagship trên coding benchmark — kích thước weight giảm từ 807GB còn 55.6GB BF16, và bản Q4_K_M GGUF chỉ 16.8GB, fit gọn 24GB VRAM của RTX 4090.
Vì weight đã nhẹ, cộng đồng chạy local được ngay trong ngày launch. Unsloth đẩy 2 quant song song: UD-Q4_K_XL (GGUF cho llama.cpp trên NVIDIA) và UD-MLX-4bit (cho Apple Silicon). Đây là lần đầu cộng đồng có data benchmark cross-platform trên cùng một model coding flagship ngay trong 24h đầu.
Tại sao quan trọng
Trước Qwen3.6, muốn chạy một model coding đạt chuẩn "flagship" local bạn phải load model 100B+ MoE — nghĩa là cần 128GB RAM unified hoặc multi-GPU. Với 27B dense Q4, bất kỳ RTX 4090 nào cũng chạy được với tốc độ đủ dùng cho interactive coding.
Nhưng benchmark này cũng cho câu trả lời thẳng thắn: bandwidth memory quyết định tất cả trong LLM decode. RTX 5090 có 1.8 TB/s GDDR7, nhanh 4.7× so với DGX Spark 273 GB/s LPDDR5x — và kết quả decode chênh đúng 4.7× (51.83 vs 11.08 tok/s). Bộ nhớ lớn không bù được bandwidth thấp khi model vẫn fit VRAM.
Con số benchmark
Tất cả số đo single-stream, out-of-the-box, không tuning:
| Setup | Decode (tok/s) | TTFT (ms) | Engine | Quant |
|---|---|---|---|---|
| RTX 5090 | 51.83 | 752 | llama.cpp | UD-Q4_K_XL |
| RTX 4090 | 45.59 | 525 | llama.cpp | UD-Q4_K_XL |
| M2 Ultra | 22.30 | 216 | MLX | UD-MLX-4bit |
| DGX Spark | 11.08 | 319 | llama.cpp | UD-Q4_K_XL |
Chú ý: quant khác nhau giữa NVIDIA (UD-Q4_K_XL GGUF) và Mac (UD-MLX-4bit) nên đây không phải apples-to-apples hoàn hảo — MLX 4bit thường nhẹ hơn một chút, nhưng chất lượng output khác. Dù vậy, tỉ lệ tương đối giữa hardware vẫn phản ánh đúng bandwidth gap.
TTFT kể một câu chuyện khác
Decode là cuộc chơi của 2 card NVIDIA, nhưng TTFT (time to first token) thì M2 Ultra đứng đầu với chỉ 216ms — nhanh hơn RTX 5090 (752ms) gấp 3.5 lần.
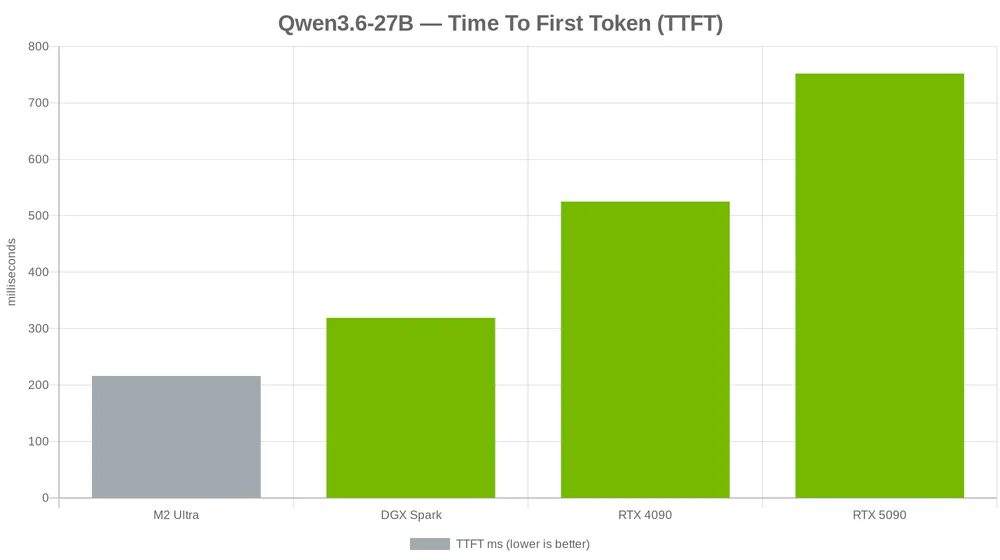
Lý do: unified memory của Apple Silicon không cần copy weight từ system RAM sang VRAM — model đã sẵn sàng ngay khi load. Với llama.cpp trên CUDA, prefill phase có thêm chi phí setup kernel, đặc biệt rõ trên 5090 Blackwell chưa tune hết.
Ngụ ý: nếu bạn xây coding agent interactive mà user quan tâm "model có phản hồi ngay không" hơn là "sinh nhanh cỡ nào", M2 Ultra lại là lựa chọn tốt bất ngờ.
Chọn setup nào?
- RTX 4090 (24GB) — sweet spot giá/hiệu năng. 45 tok/s đủ cho coding agent, chat interactive. Q4 quant fit vừa đủ VRAM.
- RTX 5090 (32GB) — chỉ hơn 4090 ~14% decode, không đáng nâng cấp nếu chỉ chạy 27B. Đáng giá khi lên Q6/Q8 hoặc model 70B dense.
- M2 Ultra Mac Studio — TTFT thấp, tiết kiệm điện, im lặng. Phù hợp dev mobile/desktop creator single-user. 22 tok/s OK cho chat nhưng chậm với agent nặng.
- DGX Spark — KHÔNG nên dùng cho model <32GB. Lợi thế duy nhất: 128GB unified để chạy model 100B-200B mà 5090 không fit. Developer kit để prototype workflow data-center, không phải inference machine.
Giới hạn & caveat
Benchmark chỉ là starting point, không phải endgame:
- Single-stream, chưa batch — scale concurrent có thể 2-4× throughput trên NVIDIA.
- Chưa bật speculative decoding — với draft model nhỏ, 4090/5090 có thể lên 80-100 tok/s.
- FP8 trên Blackwell (5090) chưa tune — có khả năng nhanh thêm 20-30%.
- MLX quant khác GGUF quant → không fair hoàn toàn giữa Apple và NVIDIA.
Về chi phí (tham khảo thị trường): RTX 4090 ~1.6-2k USD, RTX 5090 ~2-3k USD, Mac Studio M2 Ultra 64GB+ từ 4k USD, DGX Spark 3.999 USD.
Tiếp theo
Dự kiến 1-2 tuần tới cộng đồng sẽ push các con số optimized: batch throughput, speculative decoding numbers, FP8 trên 5090, và comparison với vLLM/SGLang thay vì llama.cpp. Qwen3.6-27B-FP8 đã có sẵn trên HuggingFace, chờ driver Blackwell tune xong là unlock thêm 20-30%.
Nguồn: @stevibe benchmark tweet, Simon Willison, MarkTechPost, LMSYS DGX Spark review.


