
- CoInteract là framework mới từ Alibaba Group + Tsinghua, sinh video người cầm sản phẩm từ 2 ảnh tĩnh + audio.
- Điểm đặc biệt: Human-Aware MoE cho tay/mặt và dual-stream co-generation loại bỏ hiện tượng tay xuyên qua vật — với chi phí inference bằng 0.
TL;DR
CoInteract là framework end-to-end do Alibaba Group và Tsinghua University công bố tháng 4/2026 (arXiv 2604.19636), giải bài toán sinh video human–object interaction (HOI) — tức là video người cầm, xoay, thao tác sản phẩm — từ 2 ảnh tham chiếu (người + sản phẩm), text prompt, và audio lời thoại.
Điểm mấu chốt: CoInteract nhúng thẳng cấu trúc hình học của tương tác vào Diffusion Transformer, không cần depth map hay pose preprocessing khi chạy. Kết quả: tay không còn xuyên qua vật, ngón tay không dính vào nhau, mặt không bị mờ — mà chi phí inference bằng đúng 0 so với backbone gốc.

What's new
CoInteract giải quyết hai thất bại kinh điển của video diffusion khi cho con người cầm đồ vật:
- Structural collapse ở tay và mặt — ngón tay dính lại, biến dạng, nét mặt mờ khi nhân vật chuyển động nhanh.
- Hand–object interpenetration — tay đi xuyên qua sản phẩm vì model không có khái niệm về ranh giới 3D của vật thể.
Team đóng góp 2 thiết kế nhúng thẳng vào DiT backbone (khởi tạo từ WanS2V của Alibaba):
- Human-Aware Mixture-of-Experts (MoE): một router được giám sát bằng bounding box của tay/mặt, điều token đến 3 expert nhẹ (Head, Hand, Base) + 1 Shared expert. Overhead chỉ 1.04×.
- Spatially-Structured Co-Generation: trong lúc training, model học song song 2 luồng — luồng RGB bình thường và luồng HOI structure (silhouette người + mask vật thể). Luồng HOI ép backbone học hình học tương tác. Khi inference, luồng HOI bị cắt bỏ hoàn toàn → zero overhead, nhưng kiến thức về cấu trúc đã ngấm vào trọng số shared DiT.
Why it matters
Avatar biết nói đã quá đủ — thị trường cần avatar biết thao tác. Cụ thể là livestream bán hàng, quảng cáo sản phẩm, virtual try-on, và trợ lý số cầm đồ minh họa. Đây là mảnh ghép đang thiếu nhất của digital human, và cũng là nơi Alibaba có động lực lớn nhất vì chính hệ sinh thái Taobao/Tmall là khách hàng tự thân.
CoInteract không phải là model HOI đầu tiên — trước đó có AnchorCrafter, HUMO, Phantom, VACE, SkyReels-V3 — nhưng là model đầu tiên đạt được cùng lúc: (i) không cần preprocess pose/depth khi inference, (ii) xử lý được hand–object interpenetration một cách có nguyên tắc, (iii) chi phí chạy không tăng so với backbone gốc.
Technical facts
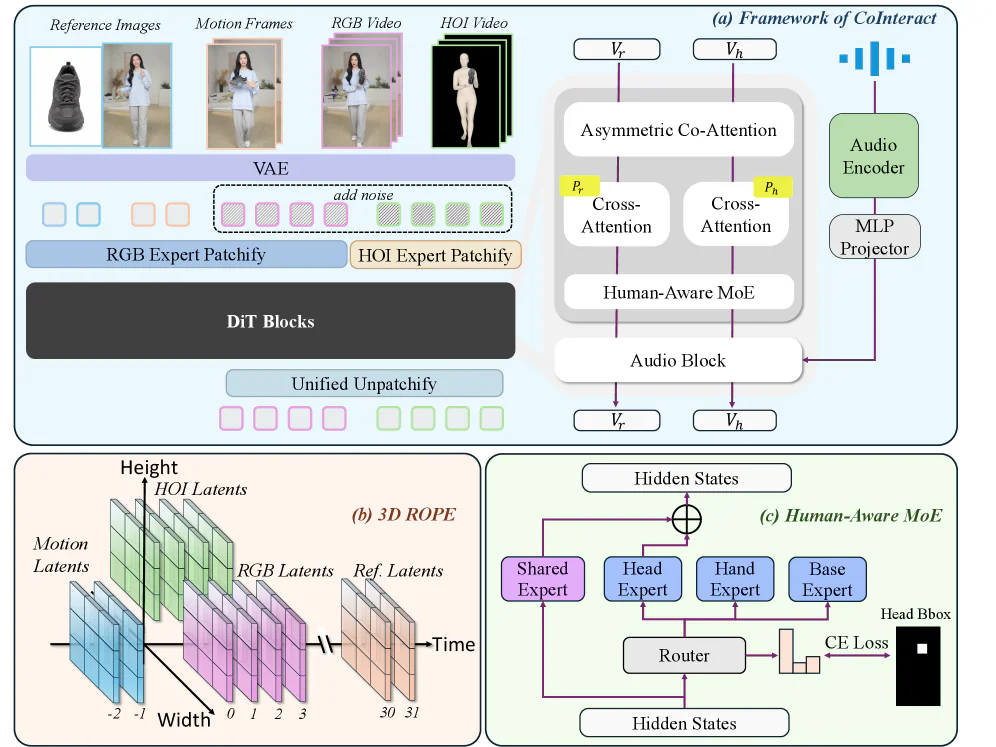
- Backbone: Diffusion Transformer, init từ WanS2V.
- MoE: 4 expert (Shared + Head + Hand + Base), mỗi expert nhẹ là FFN hidden dim
256. - Router: MLP 2 tầng với stop-gradient, train bằng cross-entropy trên bounding box tay/mặt (MediaPipe).
- HOI structure stream: ảnh 3 kênh không texture — mesh người (SAM3D-body) project xuống mặt phẳng ảnh, fuse với mask vật thể (SAM3).
- 3D RoPE: RGB token ở width [0, W], HOI token ở [−W, 0] để giữ tương ứng pixel-level; reference images gắn temporal anchor xa (t=30,31) làm identity anchor.
- Training: 2 giai đoạn — Stage 1 full attention 5K iter, Stage 2 asymmetric co-attention mask 2K iter. AdamW, lr
1e-4, cosine annealing. - Dataset: 40 giờ video demo sản phẩm + livestream → 12K clip chất lượng cao sau khi filter.
- Inference: CFG=5, 40 step, 480p — và luồng HOI bị drop hoàn toàn.
Comparison
Benchmark trên test set 50 clip, đấu với 6 baseline mạnh dùng chung input:
| Metric | Ý nghĩa | CoInteract |
|---|---|---|
| VLM-QA | Gemini-3-Pro chấm HOI plausibility qua 50 câu hỏi | 0.72 — dẫn đầu |
| HQ | Độ tin cậy keypoint tay (DWPose) | 0.724 — dẫn đầu |
| DINO-id | Giữ identity nhân vật (DINOv2) | 0.671 — dẫn đầu |
| FaceSim | Giữ khuôn mặt (ArcFace) | 0.696 — dẫn đầu |
| Smooth | Temporal coherence (CLIP giữa các frame) | 0.9951 — dẫn đầu |
Ablation đáng chú ý: bỏ dual-stream co-generation → VLM-QA rơi từ 0.72 xuống 0.48 (−33%). Giữ luồng HOI ở inference thay vì dùng asymmetric mask → điểm nhích nhẹ nhưng chi phí đội lên 4.13×. Đây chính là lý do asymmetric co-attention là chi tiết quan trọng nhất của paper.
User study với 24 evaluator (10 case mỗi người, blind ranking) cho CoInteract thắng cả 3 tiêu chí Object Consistency, Human/Background Consistency, Interaction Plausibility — trong đó Interaction Plausibility là cách biệt lớn nhất.

Use cases
- Livestream bán hàng ảo — host AI cầm sản phẩm xoay, giới thiệu, đọc script. Taobao/Tmall là khách hàng nội bộ rõ nhất.
- Quảng cáo sản phẩm — chỉ cần 1 ảnh actor + 1 ảnh sản phẩm + voiceover, không cần studio quay.
- Virtual try-on nâng cấp — không chỉ thử quần áo tĩnh, mà diễn tả người cầm túi xách, cầm cốc, thao tác phụ kiện.
- Trợ lý số và giáo dục từ xa — instructor AI cầm vật minh họa, bài giảng sinh động hơn.
Limitations & pricing
- Độ phân giải: 480p, chưa lên được 1080p/4K.
- Domain: train chủ yếu trên video demo sản phẩm và livestream → scene ngoài trời, nhiều người, hành động phức tạp ngoài tầm mẫu huấn luyện sẽ kém tổng quát hóa.
- Code & weights: repo GitHub đã public nhưng inference code + model weights chưa release (team hứa trong vòng 1 tuần). Training code ra sau. Pose control là roadmap, chưa có.
- Giá: mã nguồn mở khi weights drop, self-host. Chưa có dạng API thương mại.
- Rủi ro: deepfake giống mọi speech-driven avatar khác — kiểm soát người dùng là trách nhiệm của bên triển khai.
What's next
Roadmap ngắn hạn của team: thả inference code + weights, sau đó đến training code, và pose control. Về phía cộng đồng, hướng mở rộng tự nhiên là chạy lên 720p/1080p, mở rộng dataset ra ngoài e-commerce, và kết hợp với các mô hình video lớn hơn thế hệ Wan 2.x. Trong bức tranh tổng thể 2026 của Alibaba — Qwen3.5 Omni, PixVerse, và giờ là CoInteract — công ty đang xây một stack đầy đủ cho digital human & video: từ lời nói, tới mặt, tới tay cầm sản phẩm.
Nguồn: arXiv 2604.19636, GitHub, project page, Hugging Face.



