
- Alibaba tung bản preview Qwen3.6-Max — mô hình reasoning chủ lực kế tiếp.
- Dẫn đầu 6 benchmark coding, context 260k, Intelligence Index 52, chỉ kém Claude Opus 4.7 và GPT-5.4 đúng 5 điểm.
TL;DR
Ngày 20/04/2026, Alibaba bất ngờ tung Qwen3.6-Max-Preview — bản preview của mô hình flagship kế tiếp trong dòng Qwen 3.6. Model đạt top-1 trên 6 benchmark coding (SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench, SciCode), hỗ trợ context 260k tokens và ghi 52 điểm Artificial Analysis Intelligence Index — chỉ thua đúng 5 điểm so với bộ ba Claude Opus 4.7 (max), Gemini 3.1 Pro Preview và GPT-5.4 (xhigh). Dùng ngay trên Qwen Studio, API sắp mở trên Alibaba Cloud Model Studio.
Điểm mới
Qwen3.6-Max-Preview là bản nâng cấp chính của dòng Qwen chỉ 18 ngày sau bản Qwen3.6-Plus (02/04/2026). Alibaba khẳng định đây là model proprietary mạnh nhất từ trước đến nay trong hệ Qwen, được thiết kế như một reasoning model với extended chain-of-thought — suy luận nhiều bước trước khi trả lời.
- Agentic coding mạnh hơn hẳn Qwen3.6-Plus, đặc biệt ở tác vụ multi-file repo editing và terminal agent.
- World knowledge được củng cố — SuperGPQA +2.3, QwenChineseBench +5.3.
- Instruction following ổn định hơn — ToolcallFormatIFBench +2.8, quan trọng cho agent workflow dùng tool calling.
- Hỗ trợ feature
preserve_thinking: giữ nguyên thinking content xuyên suốt các turn, cực hữu ích cho agentic tasks. - API compatible cả OpenAI chat completions lẫn Anthropic protocol — drop-in thay thế.
Vì sao đáng chú ý
Suốt 2025–2026, coding agent đã trở thành chiến trường chính giữa các frontier lab. Claude Opus 4.x và GPT-5.x chiếm lĩnh nhờ khả năng tool use đáng tin cậy. Qwen3.6-Max-Preview là lần đầu tiên một model proprietary từ Alibaba bám sát top-3 phương Tây chỉ với khoảng cách 5 điểm Intelligence Index — đồng thời vượt Claude Sonnet 4.6 (max), Gemini 3 Flash và DeepSeek V3.2.
Với dev Việt Nam, điểm đáng giá nhất là context 260k tokens — đủ để nhét cả monorepo vừa cộng lịch sử conversation vào một request, không cần chia chunk phức tạp.
Số liệu kỹ thuật
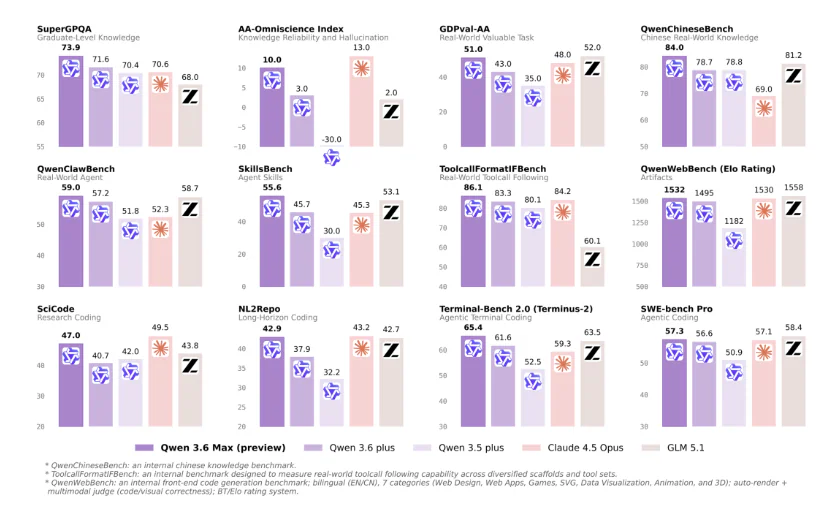
Benchmark so sánh Qwen3.6-Max-Preview với Qwen3.6-Plus và Claude 4.5 Opus (theo bảng official từ Qwen):
| Benchmark | Qwen 3.6 Max (preview) | Qwen 3.6 Plus | Claude 4.5 Opus | Delta vs Plus |
|---|---|---|---|---|
| SkillsBench (agent skills) | 55.6 | 45.7 | 45.3 | +9.9 |
| SciCode (research coding) | 47.0 | 40.7 | 49.5 | +6.3 |
| NL2Repo (long-horizon coding) | 42.9 | 37.9 | 43.2 | +5.0 |
| Terminal-Bench 2.0 | 65.4 | 61.6 | 59.3 | +3.8 |
| SWE-bench Pro (agentic coding) | 57.3 | 56.6 | 57.1 | +0.7 |
| QwenClawBench (real-world agent) | 59.0 | 57.2 | 52.3 | +1.8 |
| QwenWebBench (Elo rating) | 1532 | 1495 | 1530 | +37 |
| SuperGPQA (graduate knowledge) | 73.9 | 71.6 | 70.6 | +2.3 |
| QwenChineseBench | 84.0 | 78.7 | 69.0 | +5.3 |
| ToolcallFormatIFBench | 86.1 | 83.3 | 84.2 | +2.8 |
Các đặc tả khác:
- Intelligence Index (Artificial Analysis): 52 — hạng 4 toàn bảng 478 models.
- Context window: 256k–260k tokens.
- Modality: text-only (không hỗ trợ image/audio/video input).
- Parameter count: không công bố (proprietary).
- Verbosity: sinh 74M output tokens khi eval Intelligence Index — khá dài dòng so với trung bình 26M.
So sánh frontier models
Trên Artificial Analysis Intelligence Index (cập nhật 04/2026):
| Model | Index | Ghi chú |
|---|---|---|
| Claude Opus 4.7 (max) | 57 | Top chung |
| Gemini 3.1 Pro Preview | 57 | Top chung |
| GPT-5.4 (xhigh) | 57 | Top chung |
| Muse Spark | 52 | Hạng 4 |
| Qwen3.6 Max Preview | 52 | Hạng 4 — mới ra |
| Claude Sonnet 4.6 (max) | 51 | Thua Qwen 1 điểm |
| GLM-5.1 | 49 | |
| Grok 4.20 | 46 | |
| Gemini 3 Flash | 46 |
Use case thực tế
- Agentic coding IDE: Cursor, Cline, Aider — Qwen3.6-Max-Preview đủ mạnh làm backbone thay Claude Sonnet cho repo phức tạp.
- Long-context code review: 260k tokens nuốt gọn 1 monorepo mid-size + git history.
- Terminal agent: điểm Terminal-Bench 2.0 65.4 — cao nhất nhóm — cho phép chạy ops/maintenance script tự động tin cậy hơn.
- Chinese-first product: QwenChineseBench 84.0 vượt xa Claude (69.0) — lựa chọn tự nhiên cho SaaS Trung Quốc hoặc tool dịch/nội địa hóa.
- Enterprise Q&A & decision support: world knowledge +2.3 trên SuperGPQA giúp answer chính xác hơn ở đề tài graduate-level.
Giới hạn & giá
- Preview, còn iterate: Alibaba nói rõ model vẫn đang phát triển, hành vi có thể thay đổi trước GA.
- Text-only: không nhận image/audio/video — thua Claude 4.7 và Gemini 3.1 Pro ở tác vụ multimodal.
- Proprietary: trọng số không public. Ai cần open-weight có thể dùng
Qwen3.6-35B-A3B(đã open-source) trong cùng dòng. - Pricing: Artificial Analysis ghi nhận $0.00/1M token in/out trong giai đoạn preview — gần như miễn phí. Giá production TBD.
- API: Alibaba Cloud Model Studio đang "coming soon". Dùng ngay được qua Qwen Studio chat.
Kế tiếp
Dòng Qwen 3.6 hiện đã đủ product matrix: Max-Preview (flagship), Plus (cân bằng), Flash (tốc độ), và Qwen3.6-35B-A3B (open-source). Alibaba hứa sẽ có thêm Qwen3.6 model trong thời gian tới — nhiều khả năng là bản GA của Max hoặc biến thể multimodal. Dev có thể test ngay để feedback trước khi preview chốt API pricing.
Nguồn: Qwen blog, Artificial Analysis, AIbase, CnTechPost.

