
- HotAisle vừa công bố công thức serving production cho Kimi K2.6 (1T params) trên một node 8x AMD Instinct MI300X.
- Chuyển từ autoregressive sang DFlash speculative decoding đẩy throughput từ 90 tok/s lên 508 tok/s — cùng phần cứng, cùng model, output bit-identical.
TL;DR
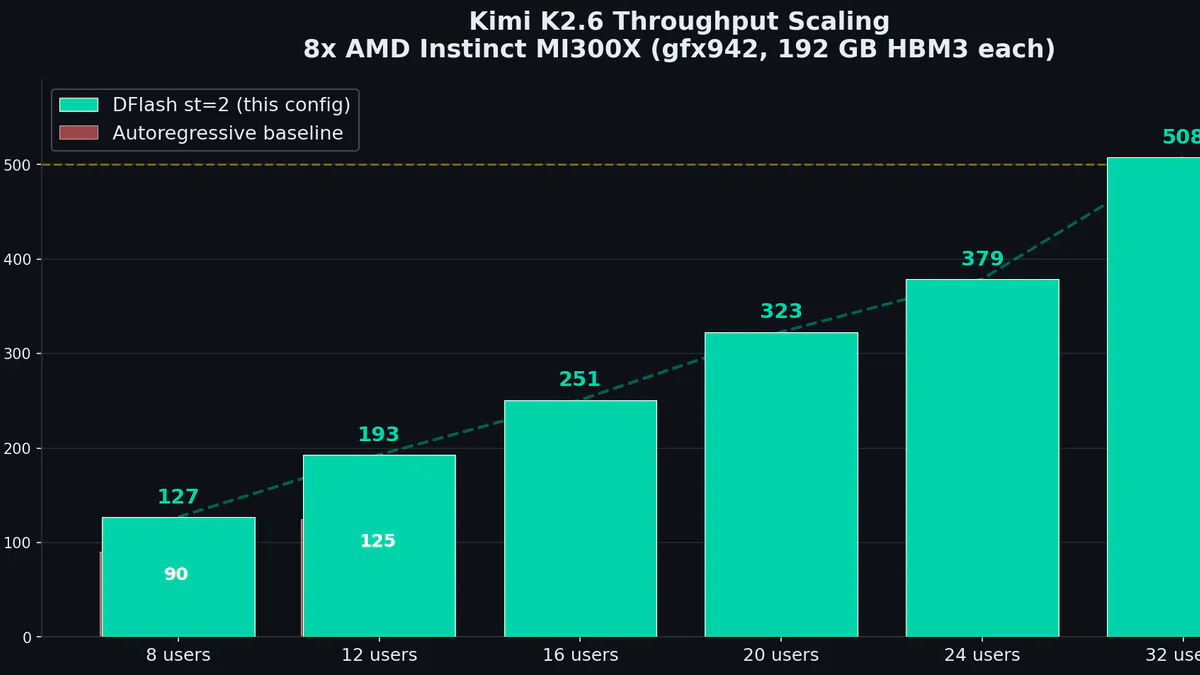
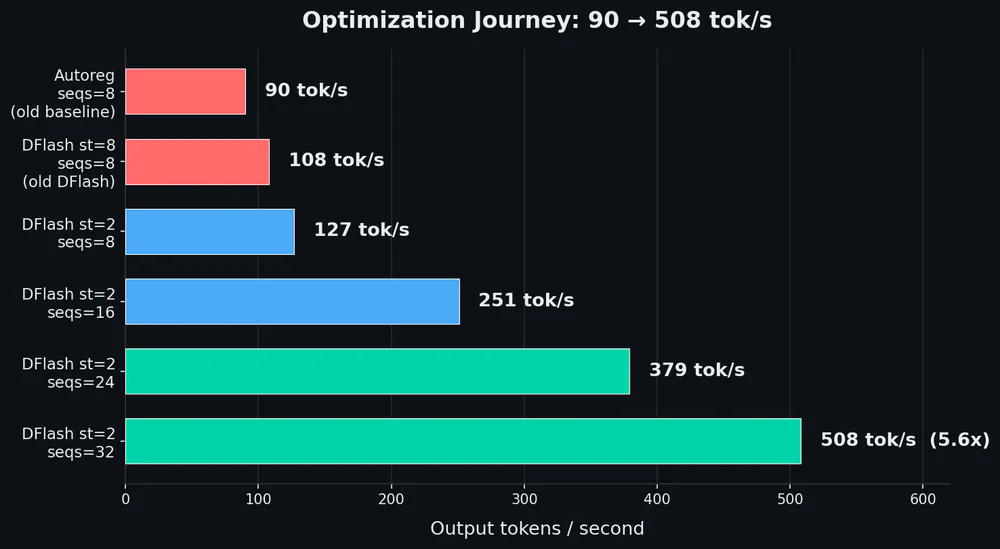
HotAisle + Florian Leibert vừa publish recipe vLLM ROCm để serve Kimi K2.6 (1T params MoE, Moonshot AI ra mắt 2026-04-20) trên một node 8× AMD Instinct MI300X. Kết quả: throughput tổng nhảy từ 90 tok/s lên 508 tok/s — 5.6×, cùng hardware, cùng model, output bit-identical vs autoregressive. Bản FP8 KV đẩy tiếp lên 901 tok/s @ 64 concurrent sessions (1.77× so với peak BF16).
Có gì mới
Ba thành phần ghép lại:
- Kimi K2.6 — 1T tổng params, 32B active per token, 384 experts (8 active + 1 shared), 61 layers, context 256K tokens, weights dưới Modified MIT License. Ra mắt 20/04/2026, dẫn đầu HLE-Full (54.0), SWE-Bench Pro (58.6), LiveCodeBench v6 (89.6).
- DFlash — speculative decoding dùng block diffusion làm draft model parallel (paper arXiv:2602.06036, Feb 2026). Khác với EAGLE-3 ở chỗ draft tokens được sinh trong một forward pass thay vì tuần tự, acceptance cao hơn nhiều.
- Draft checkpoint z-lab/Kimi-K2.5-DFlash — chỉ 5 decoder layers, ~6.5B params, ~6.5 GB, nhét gọn vào một MI300X.
Công thức chạy ngay trên vLLM v0.19.2 ROCm nightly + AMD aiter MoE kernels. Không cần hack driver, không custom inference engine.
Vì sao đáng quan tâm
Với 90 tok/s aggregate, bạn gần như không serve nổi một user tử tế — huống chi tính năng headline của K2.6 là agent swarm 300 sub-agents × 4,000 bước phối hợp. Muốn swarm chạy real-time, decode phải đủ nhanh để feed song song hàng chục sub-agents một lúc. 508 tok/s là ngưỡng đó.
Quan trọng hơn: đây là AMD, không phải NVIDIA. Một node 8× MI300X (1,536 GB HBM3 tổng) giờ cho throughput ngang ngửa H100/H200 class cho model 1T MoE — và spot rate trên cloud MI300X thường rẻ hơn H100 đáng kể. Cột mốc parity cho Instinct platform.
Số liệu kỹ thuật
Config đạt 508 tok/s ở concurrency=32, BF16 KV cache:
| Config | Throughput tổng | Speedup |
|---|---|---|
| Autoregressive baseline (c=8) | 90.4 tok/s | 1.0× |
| DFlash st=2, BF16 KV (c=32) | 507.6 tok/s | 5.6× |
| DFlash st=2, FP8 KV (c=64) | 901 tok/s | 10.0× |
Ba tinh chỉnh quyết định kéo từ 90 lên 508:
- Tắt NUMA balancing (
echo 0 > /proc/sys/kernel/numa_balancing) — xoá memory-access bottleneck. - Spec tokens: 8 → 2 — acceptance rate nhảy từ 16% lên 50%.
- max_num_seqs: 8 → 32 — scale tuyến tính, +15.8 tok/s mỗi slot thêm vào.
Hardware stack:
- 8× AMD Instinct MI300X, CDNA 3 (gfx942), 192 GB HBM3 mỗi GPU — tổng 1,536 GB VRAM
- ~2 TB system RAM, vLLM v0.19.2 ROCm nightly, ROCm 6.x
- MOE_BACKEND=aiter, BLOCK_SIZE=16 (bắt buộc cho DFlash + MLA), ENFORCE_EAGER=true
- MAX_MODEL_LEN=262144, GPU_MEMORY_UTILIZATION=0.90
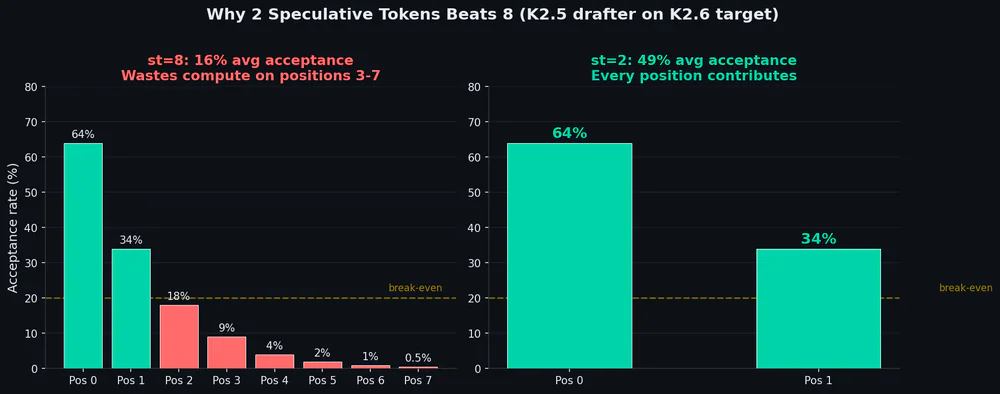
So sánh: st=2 vs st=8 và FP8 vs BF16
Trực giác cho rằng càng nhiều speculative tokens càng nhanh là sai. Ở Kimi K2.6 + DFlash drafter này, st=8 làm acceptance sụp xuống 16% — draft tokens bị reject quá nhiều, verification phí thời gian, throughput giảm 20%.
| Spec tokens | Acceptance pos 0 | Acceptance pos 1 | Avg | Net effect |
|---|---|---|---|---|
| st=2 | 64% | 34% | 49% | +40% throughput |
| st=8 | 64% | 34% | 16% | -20% throughput |
FP8 KV cache là trade-off khác: memory capacity tăng từ 1,230,368 lên 2,469,568 tokens (2.01×), cho phép seqs=64 → aggregate 901 tok/s. Nhưng per-slot throughput chậm hơn BF16 ~22% do phải tính dynamic scale. Tối ưu cho batch đông; với latency-sensitive traffic thì BF16 seqs=32 vẫn tốt hơn.
Ai hưởng lợi
- Agent swarm workloads — K2.6 thiết kế để chạy 300 sub-agents × 4,000 bước. Ở 90 tok/s là ảo; ở 508 tok/s là khả thi.
- Coding assistants dài hơi — Kimi Code CLI, IDE integrations. K2.6 dẫn đầu SWE-Bench Pro và LiveCodeBench; decode nhanh biến autocomplete thành pair-programmer.
- Self-hosted enterprise trên AMD — một node 8× MI300X (thuê on-demand ~$24–32/hr) giờ serve 32 user đồng thời, cost/token giảm ~5.6× so với trước.
- Reasoning batches — HLE-Full, AIME 2026 (96.4), GPQA-Diamond với output lên 98K tokens được benefit nhiều nhất.
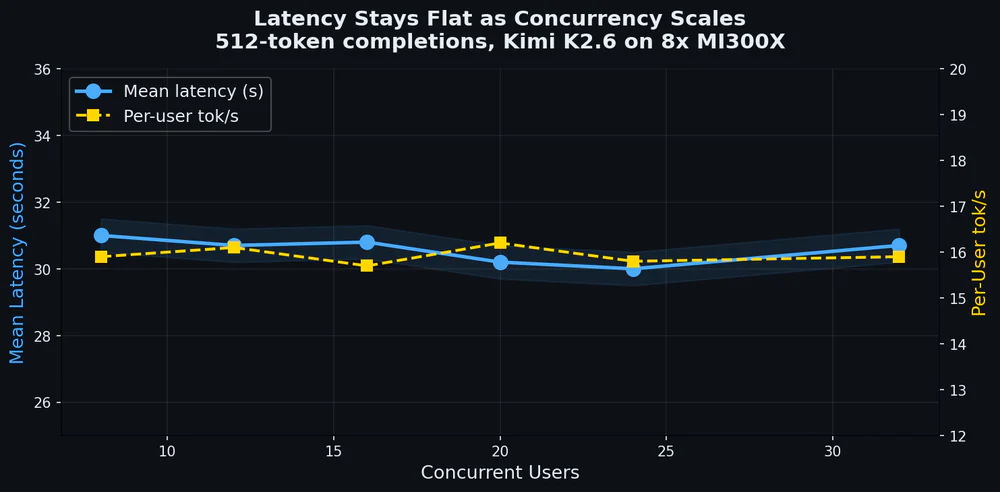
Per-user tok/s giữ ổn định ~15.8 tok/s mỗi slot, mean request latency ~30–31s bất kể concurrency 8 hay 32. Không có cliff.
Giới hạn & chi phí
- ENFORCE_EAGER=true — torch.compile hiện chưa cho gain trên ROCm, phải chạy eager mode.
- st=8 là footgun — đừng tin “nhiều draft tokens = nhanh”. Sweet spot của target + drafter này là st=2.
- Draft context mismatch — drafter train ở 4K nhưng target 256K. Acceptance dài-context có thể xuống ngoài training distribution.
- Hardware cost — 8× MI300X node capex ~$200K+ hoặc ~$24–32/hr on-demand. Chưa phải cho solo dev, nhưng dễ tiếp cận hơn H200 cluster tương đương.
- Quality: bit-identical với AR. Speculative decoding lossless về toán học khi verify đúng — không có benchmark drop.
Tiếp theo
Hướng tối ưu còn để ngỏ: calibration FP8 KV scale tĩnh (hiện auto-compute range 0.026–0.068) được kỳ vọng recover 22% gap per-slot. DFlash drafter train lại ở context dài hơn. Recipes cho MI325X và MI350 khi hardware đến tay cộng đồng. Và chắc chắn sẽ có người port recipe này qua H200 để so sánh trực tiếp.
Repo đầy đủ (config, benchmark script, Dockerfile) trên Hugging Face tại florianleibert/kimi-k26-dflash-mi300x.
Nguồn: HotAisle, Hugging Face config, DFlash paper, Moonshot AI Kimi K2.6.

