- Datalab vừa ra Chandra OCR 2 — mô hình 4B parameters đạt 85.9% trên olmOCR bench (SOTA), hỗ trợ 90+ ngôn ngữ, xử lý handwriting, math LaTeX, bảng phức tạp và biểu đồ.
- Nhỏ hơn Chandra 1 (9B) một nửa nhưng cao hơn ở mọi hạng mục.
TL;DR
- Chandra OCR 2 của Datalab — mô hình OCR 4B parameters, mã nguồn mở, ra mắt 18/03/2026.
- 85.9% trên olmOCR-bench (SOTA cho open-weights), 77.8% trung bình trên 43 ngôn ngữ — vượt Gemini 2.5 Flash (67.6%), GPT-5 Mini (60.5%) và GPT-4o (69.9% olmOCR).
- Nhỏ hơn Chandra 1 (9B) một nửa nhưng cao hơn ở mọi hạng mục: ArXiv math +8.0, Old Scans Math +9.0, multilingual +8.4 điểm.
- Output Markdown / HTML / JSON với bounding box; xử lý handwriting, math LaTeX, bảng merged-cell, form checkbox, charts thành dữ liệu cấu trúc, flowcharts thành Mermaid.
- Apache 2.0 (code) + OpenRAIL-M (weights, free dưới $2M doanh thu); chạy được trên 1 GPU consumer, throughput ~2 trang/s trên H100.
Có gì mới?
Vik Paruchuri, founder của Datalab, công bố Chandra 2 ngày 18/03/2026. Đây là phiên bản tiếp nối Chandra 1 (ra tháng 10/2025). Điểm đáng chú ý: giảm từ 9B parameters xuống 4B nhưng accuracy tăng ở mọi hạng mục.
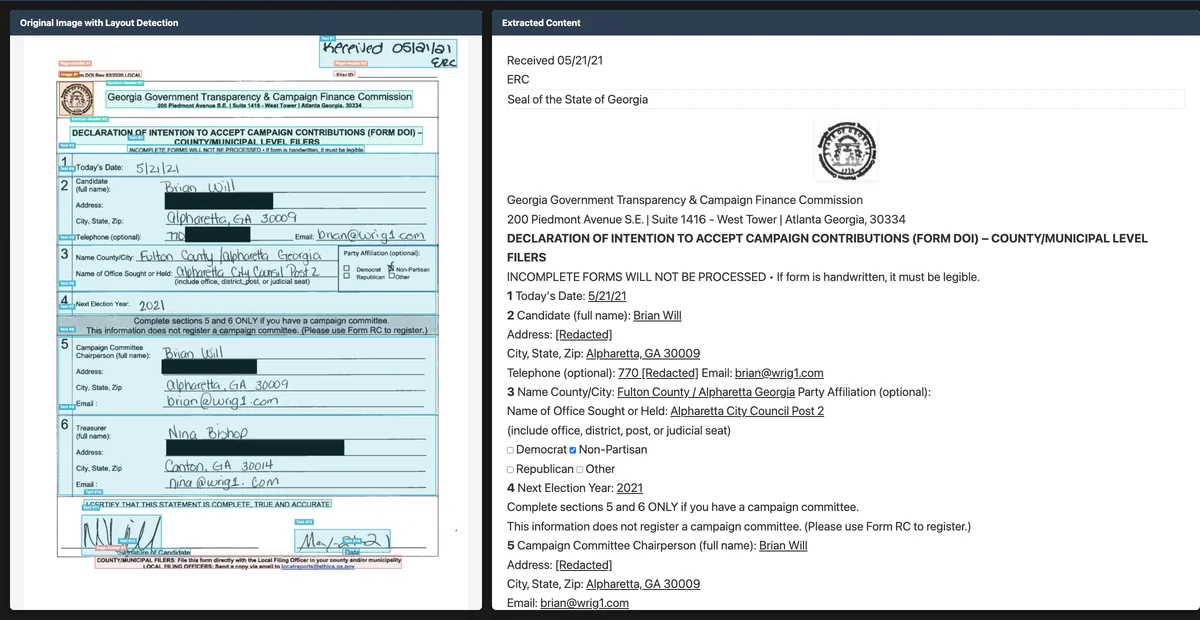
Chandra 2 không phải pipeline OCR truyền thống (segment trang thành blocks rồi xử lý từng block). Nó là một vision-language model (dựa trên Qwen3 VL) đọc cả trang một lần, hiểu toàn bộ layout, rồi xuất ra Markdown / HTML / JSON đã cấu trúc — kèm bounding box cho 15+ loại block: text, section-header, table, form, image, figure, diagram, equation-block, code-block, chemical-block, bibliography, table-of-contents, page-header, page-footer, complex-block...
Headline capabilities:
- Bảng phức tạp: colspan, rowspan, header phân cấp, ô trống offset, bảng lồng có ảnh.
- Math: in ấn lẫn viết tay, render LaTeX chuẩn — kể cả math trong scripts không phải Latin.
- Forms: checkbox, radio, label-value preserve nguyên vẹn.
- Handwriting: ghi chú bác sĩ, chữ ký, mixed printed/handwritten.
- Charts & diagrams: bar chart ra giá trị + axis labels; flowchart ra Mermaid đầy đủ nodes/edges.
- Image captioning: tự crop ảnh nhúng và sinh caption theo context.
Vì sao đáng chú ý?
Đa phần data thực tế của doanh nghiệp đang nằm trong PDF, form scan, ghi chú viết tay, báo cáo có bảng dày — không bao giờ chảy sạch vào context window LLM. OCR truyền thống cho ra một đống text linear. Cái RAG pipeline và AI agent thực sự cần là structured artifact: bảng vẫn là bảng, form field giữ label, ảnh có caption, layout giữ nguyên.
Chandra 2 giải quyết bài toán này ở quy mô open-source. Một mô hình 4B chạy trên một GPU consumer, không cần API gọi ra ngoài — phù hợp ngành y tế, tài chính, pháp lý, nơi data confidential không được gửi qua API third-party.
Số liệu kỹ thuật
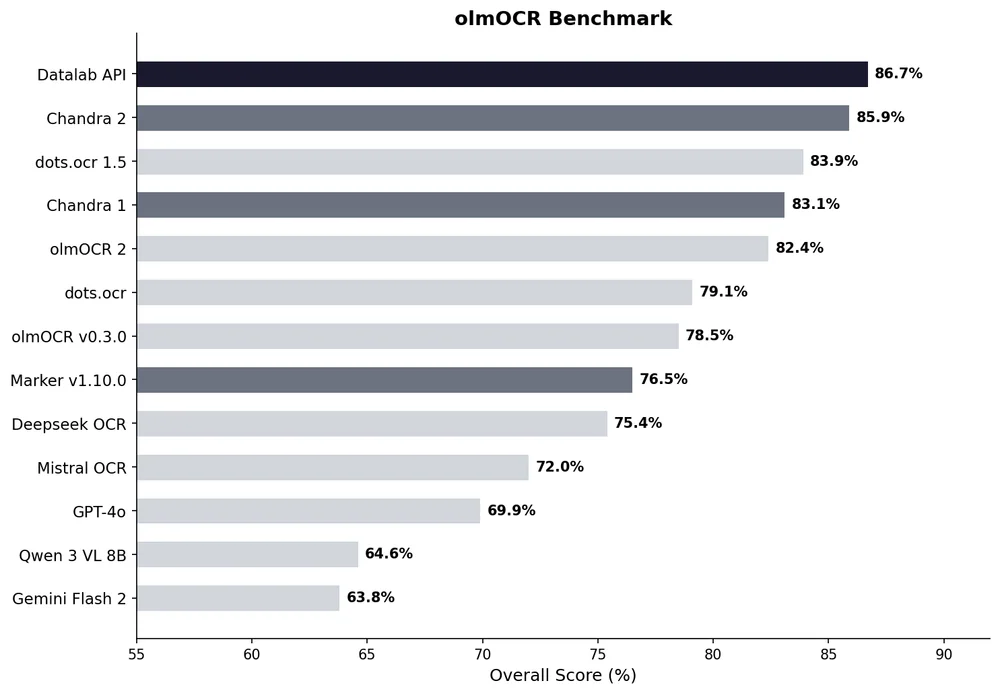
Trên olmOCR-bench (benchmark chuẩn từ AllenAI), Chandra 2 đạt 85.9% ± 0.8 — đứng thứ hai chỉ sau chính Datalab API (86.7%, là Chandra 2 hosted có thêm post-processing).
| Hạng mục | Chandra 1 | Chandra 2 | Thay đổi |
|---|---|---|---|
| ArXiv | 82.2% | 90.2% | +8.0 |
| Old Scans Math | 80.3% | 89.3% | +9.0 |
| Tables | 88.0% | 89.9% | +1.9 |
| Multi column | 81.2% | 83.5% | +2.3 |
| Headers/Footers | — | 92.5% | — |
| Overall | 83.1% | 85.9% | +2.8 |
Multilingual (benchmark internal của Datalab):
- Top 43 ngôn ngữ: 77.8% (Chandra 1: 69.4%, Gemini 2.5 Flash: 67.6%, GPT-5 Mini: 60.5%)
- Full 90 ngôn ngữ: 72.7% (Gemini 2.5 Flash: 60.8%)
Throughput: ~2 trang/giây trên một NVIDIA H100 80GB với vLLM, 96 concurrent sequences (peak 4 trang/s). Max output 8,192 tokens. Có MTP head để giảm latency thêm.
So với các đối thủ
Trên olmOCR-bench overall, Chandra 2 (open) bỏ xa hầu hết open-source và proprietary models:
| Model | olmOCR overall | Loại |
|---|---|---|
| Datalab API (Chandra 2 hosted) | 86.7% | API |
| Chandra 2 (open) | 85.9% | Open |
| dots.ocr 1.5 | 83.9% | Open |
| Chandra 1 | 83.1% | Open |
| olmOCR 2 | 82.4% | Open |
| DeepSeek OCR | 75.4% | Open |
| Mistral OCR API | 72.0% | API |
| GPT-4o (Anchored) | 69.9% | API |
| Qwen 3 VL 8B | 64.6% | Open |
| Gemini Flash 2 (Anchored) | 63.8% | API |
Lưu ý: dots.ocr 1.5 nhỉnh hơn Chandra 2 ở Tables (90.7 vs 89.9) và Multi-column (85.3 vs 83.5), nhưng kém ở mọi hạng mục còn lại.
Phần multilingual mới là chỗ gap rõ nhất — đặc biệt Indic và RTL scripts:

| Ngôn ngữ | Chandra 1 | Chandra 2 | +/- |
|---|---|---|---|
| Malayalam | 18.1% | 64.3% | +46.2 |
| Kannada | 20.6% | 63.2% | +42.6 |
| Telugu | 19.5% | 58.6% | +39.1 |
| Arabic | 34.0% | 68.4% | +34.4 |
| Hebrew | 38.9% | 70.4% | +31.5 |
| Bengali | 45.6% | 72.8% | +27.2 |
| Tamil | 50.8% | 77.7% | +26.9 |
Ai hưởng lợi?
- AI agents & RAG pipelines: JSON kèm bounding box feed thẳng retriever, không cần post-processing.
- Y tế: prior-auth forms, lab reports, ghi chú bác sĩ viết tay, discharge summaries có bảng thuốc.
- Tài chính & kế toán: invoice, sao kê, báo cáo tài chính có merged cells (subtotal trải nhiều cột). Một user trên Purchaser.ai báo tiết kiệm sáu chữ số nhờ tự động hoá khâu này.
- Pháp lý: hợp đồng, phán quyết, văn bản pháp quy — giữ được số điều, đoạn thụt lề, bảng tham chiếu.
- Giáo dục & nghiên cứu: paper khoa học, sách giáo khoa, đề thi — math ra LaTeX, flowchart ra Mermaid.
- Lưu trữ & sử ký: bản chép tay cổ, văn bản đa ngữ — handwriting + 90 ngôn ngữ là combo hiếm.
Hạn chế & pricing
License hai tầng:
- Code: Apache 2.0 (free hoàn toàn).
- Weights: modified OpenRAIL-M — free cho cá nhân, research, và startup dưới $2M doanh thu / funding hằng năm. Trên ngưỡng đó cần commercial license. Không được dùng để build sản phẩm cạnh tranh trực tiếp với Datalab API.
Hardware:
- 1 GPU consumer chạy được cho dev / volume thấp (HuggingFace Transformers).
- Production: H100 80GB + vLLM. Quantized 8B / 2B có cho on-prem qua commercial license.
Datalab API: $5 free credit, paid tiers cho production. Tuần trước chạy 300M trang qua API.
Limitation thật sự: Arabic 68.4% (đã +34.4 nhưng vẫn còn cải thiện được — connected scripts + diacritics khó), Urdu 43.2%, một số low-resource languages chưa cover; long-document handling và edge-case bảng vẫn đang được fix.
Roadmap
Datalab công bố hướng tiếp theo: mở rộng ngôn ngữ low-resource, giảm latency, ra model variants nhỏ hơn nữa, fix edge case bảng/form, và xử lý long document tốt hơn. Ngoài ra sẽ có write-up chi tiết về quy trình train multilingual và phương pháp benchmark.
Tự thử ngay: datalab.to/playground (free), hoặc pip install chandra-ocr. Repo: github.com/datalab-to/chandra (9.6k stars). Model: huggingface.co/datalab-to/chandra-ocr-2 (192k+ downloads tháng đầu).
Nguồn: Datalab blog, HuggingFace model card, GitHub.




