
- Pulse AI vừa mở mã nguồn PulseBench-Tab — benchmark frontier cho table extraction với 1.820 bảng được human-annotate trên 9 ngôn ngữ, kèm metric T-LAG đánh giá cả structure lẫn nội dung trong một con số duy nhất.
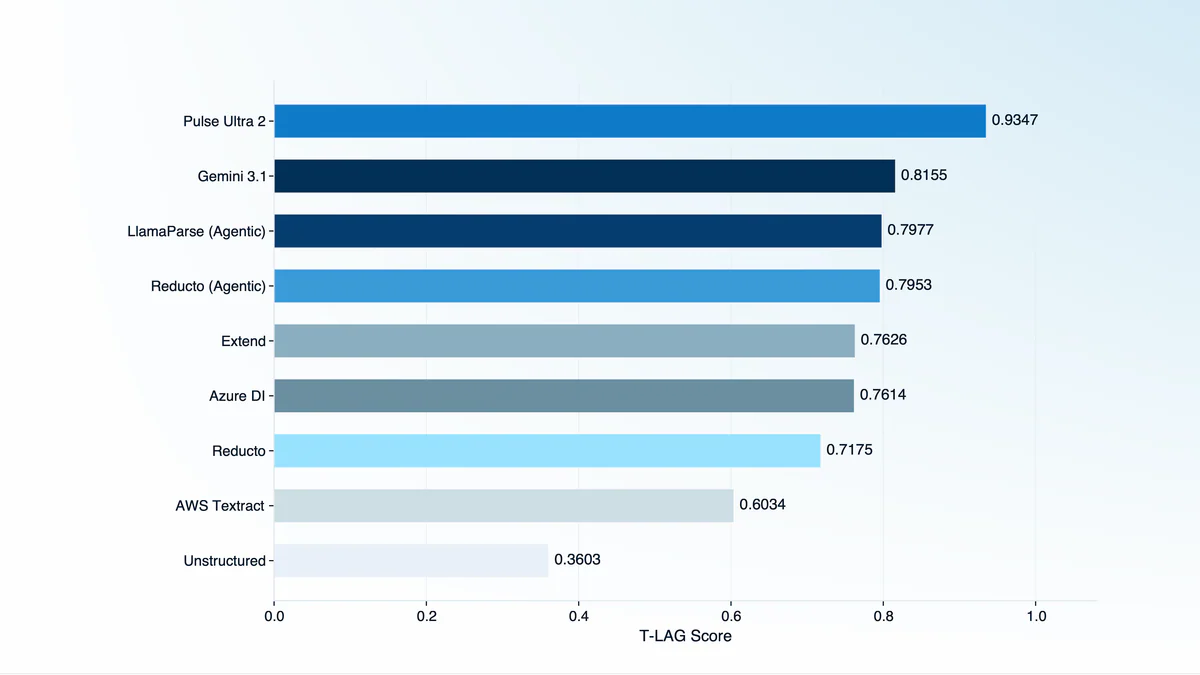
- Pulse Ultra 2 dẫn đầu leaderboard với 0.9347, bỏ xa Gemini 3.1 (0.8155) và các agentic pipeline như LlamaParse, Reducto.
TL;DR
Pulse AI vừa open-source PulseBench-Tab — benchmark frontier cho table extraction với 1.820 bảng do người annotate thủ công trên 9 ngôn ngữ (4 hệ chữ viết), và T-LAG — metric mới đánh giá đồng thời structural accuracy và OCR quality trong một unified score. Đây là lần đầu Pulse công khai toàn bộ evaluation harness nội bộ sau khi xử lý hàng tỷ trang tài liệu cho Fortune 50, các quỹ đầu tư lớn và startup AI hàng đầu. Trên leaderboard, Pulse Ultra 2 đạt 0.9347, bỏ xa Gemini 3.1 (0.8155), LlamaParse (0.7977) và Reducto (0.7953).
Có gì mới?
PulseBench-Tab không phải dataset programmatic được sinh ra từ PDF sạch đẹp. Pulse chọn tables khó — có chữ viết tay, bảng xoay lệch, ảnh scan chất lượng thấp, merged cells phức tạp — chính những thứ mà 48.1% real-world business documents chứa, và hầu hết benchmark cũ bỏ qua.
Song song với dataset là T-LAG (Table Localized Adjacency Graph). Thay vì so từng ô text một cách ngây thơ, T-LAG convert mỗi bảng HTML thành directed graph, mã hoá quan hệ rowspan/colspan giữa các cell thành cạnh, rồi dùng thuật toán Hungarian để match tối ưu giữa graph predicted và ground-truth. Score cuối là một số trong [0, 1] phản ánh cả cấu trúc lẫn nội dung.
Vì sao điều này quan trọng?
Benchmark cũ như PubTabNet hay FinTabNet được gắn nhãn tự động từ metadata, data đồng nhất, không thử thách được model trong môi trường production. RD-TableBench của Reducto (2024) cải thiện bằng human-annotation nhưng vẫn scoring hàng-độc-lập bằng Needleman-Wunsch — không model đủ sâu mối quan hệ giữa các ô.
Hệ quả: một model có thể đạt điểm cao trên benchmark cũ nhưng vẫn merge nhầm hai cột hoặc mất adjacency khi gặp bảng thật. T-LAG phạt đúng vào lỗi đó. Với teams đang build RAG trên PDF tài chính, agent pipeline đọc báo cáo, hay training DocVQA model — đây là metric gần nhất với chất lượng họ thực sự cần.
Technical facts
Dataset gồm 1.820 bảng, phân bố đủ các mức độ phức tạp:
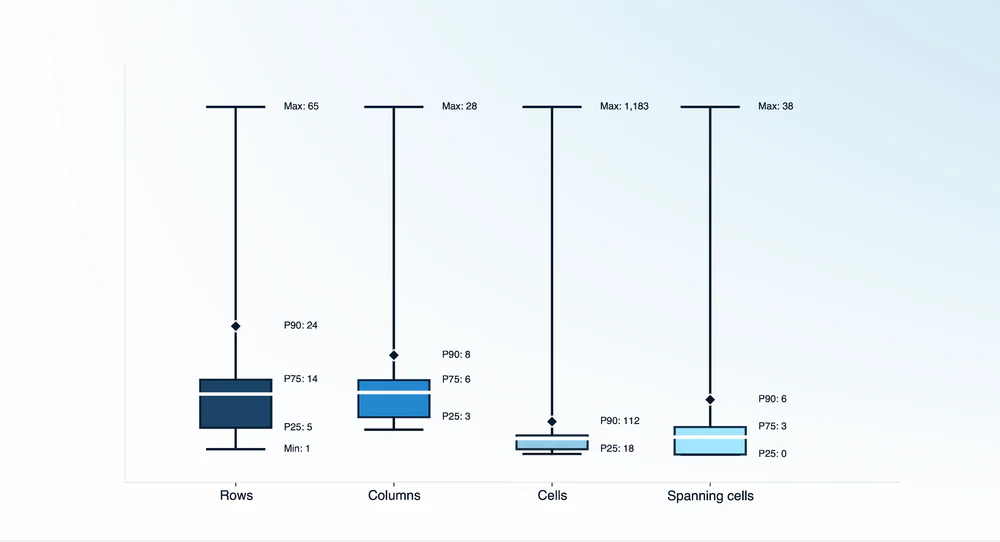
| Chiều | P25 | P75 | P90 | Max |
|---|---|---|---|---|
| Rows | 5 | 14 | 24 | 65 |
| Columns | 3 | 6 | 8 | 28 |
| Cells | 18 | — | 112 | 1.183 |
| Spanning cells | 0 | 3 | 6 | 38 |
- 27.5% bảng có ≤20 cells (đơn giản)
- 4.0% bảng có trên 200 cells (cực phức tạp)
- 48.1% có merged/spanning cells
- Bao gồm chữ viết tay, ảnh scan chất lượng thấp, và bảng xoay
T-LAG hoạt động bằng cách convert HTML table thành graph có hướng, mỗi cell là một node và quan hệ cell-adjacency (rowspan, colspan) là cạnh. Thuật toán Hungarian match cạnh giữa prediction và ground-truth, score cuối blend giữa structural matching và OCR text similarity.
Sample tables trong dataset — chú ý độ đa dạng về hệ chữ, chất lượng ảnh, và layout:

So sánh với các hệ thống hiện có
Kết quả trên leaderboard T-LAG (càng cao càng tốt):
| Hạng | Hệ thống | T-LAG | Coverage |
|---|---|---|---|
| 1 | Pulse Ultra 2 | 0.9347 | 100% |
| 2 | Gemini 3.1 | 0.8155 | 99.5% |
| 3 | LlamaParse (Agentic) | 0.7977 | 94.0% |
| 4 | Reducto (Agentic) | 0.7953 | 78.8% |
| 5 | Extend | 0.7626 | 91.9% |
| — | AWS Textract | 0.6034 | — |
| — | Unstructured | 0.3603 | — |
Khoảng cách giữa Pulse Ultra 2 và Gemini 3.1 là ~12 điểm T-LAG — rộng hơn rất nhiều so với thường thấy ở các leaderboard LLM frontier. Unstructured tụt sâu dưới 0.4, cho thấy open-source generic parser không đủ cho production tables.
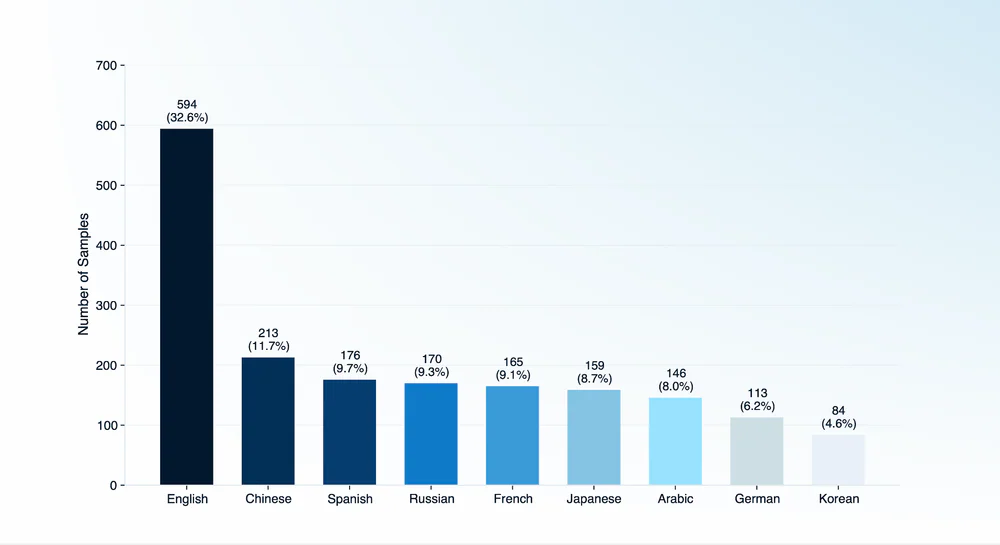
Về phân bố ngôn ngữ — English vẫn chiếm ~33% nhưng 8 ngôn ngữ còn lại đều có trên 80 samples, đủ để đánh giá riêng:
Use cases
- Finance: 10-K, earnings tables, fund factsheets — nơi sai một ô có thể kéo theo decision sai hàng triệu đô
- Healthcare: lab reports, clinical trial tables đa ngôn ngữ
- Legal: hợp đồng có schedule phức tạp, merged cells
- Insurance: claim forms, policy schedules
- Supply chain: invoice, packing list, chứng từ hải quan
- RAG pipelines: teams đang build retrieval trên PDF enterprise
- AI startups: lần đầu có benchmark công khai đáng tin để validate model nội bộ
Limitations & pricing
- Đây là benchmark, không phải model. Dataset + code mở, nhưng Pulse Ultra 2 vẫn closed-source (API-only).
- Chỉ tables. Không bao gồm charts, figures, form-field extraction hay full-page layout — những stage khác trong pipeline của Pulse.
- 9 ngôn ngữ, skew English (~33% samples). Chưa cover long-tail như Hindi, Thai, Hebrew.
- Pricing: dataset + code free (Hugging Face + GitHub). Pulse Ultra 2 API pricing không công khai — contact sales cho enterprise.
What's next
Benchmark và leaderboard live tại benchmark.runpulse.com. Pulse cam kết cập nhật khi có model mới. Kỳ vọng tiếp theo: mở rộng language coverage, thêm benchmark cho charts/figures, và tiếp tục công khai internal eval harness.
Đây là nước đi tiếp nối chiến lược mà Reducto đã bắt đầu năm 2024 — các doc-AI startup YC-backed đang cạnh tranh nhau trên "transparency of eval". Với PulseBench-Tab, rất có thể các frontier VLM (Gemini, Claude, GPT-5) sẽ submit kết quả và biến đây thành Arena of Tables cho 2026.
Chúc mừng Sid Mnk và Ritvik Pandey cùng team Pulse với launch này.
Nguồn: runpulse.com, benchmark leaderboard, Reducto RD-TableBench, Y Combinator.
