
- LlamaIndex công bố ParseBench — benchmark đầu tiên đánh giá khả năng parse tài liệu (bao gồm chart) của AI agent trên ~2.000 trang enterprise document với 167.000+ test rule.
- LlamaParse Agentic dẫn đầu 84.9% trong khi hầu hết specialized parser chết dưới 6% ở hạng mục chart.
TL;DR
ParseBench là benchmark đầu tiên đánh giá chất lượng document parsing cho AI agent trên tài liệu enterprise thực tế — và đặc biệt, là benchmark đầu tiên có hạng mục VLM chart understanding trong bối cảnh document (không phải chart cô lập như ChartQA/ChartXiv). LlamaIndex phát hành 13-04-2026, open-source toàn bộ.
- ~2.000 trang enterprise đã human-verify, 167.000+ test rule
- 568 trang chứa chart đa dạng nhúng trong doc thực tế
- Đánh giá 14 phương pháp trên 5 chiều: Tables, Charts, Content Faithfulness, Semantic Formatting, Visual Grounding
- LlamaParse Agentic 84.9% — phương pháp duy nhất cạnh tranh ở cả 5 chiều
- Chart là điểm yếu cả ngành: chỉ 4/14 provider vượt 50%, phần lớn parser specialized dưới 6%

Điểm mới: Chart benchmark trong context enterprise
Jerry Liu (CEO LlamaIndex) nhấn mạnh trên X rằng đây là benchmark đầu tiên đưa VLM chart understanding vào đúng bối cảnh enterprise document. Các benchmark hiện tại như ChartQA và ChartXiv chỉ test chart độc lập, không kiểm tra khi chart nằm trong báo cáo tài chính, hợp đồng bảo hiểm, hoặc government filing — nơi model phải vừa hiểu layout document vừa trích xuất số liệu chart.
ParseBench cover 568 trang chart với đủ biến thể thực tế:
- Discrete series (cột, điểm)
- Continuous series (đường)
- Bar, point, line graph
- Chart không có marker rõ
- Chart có axis phức tạp, legend overlap
Mỗi chart đều có ground-truth datapoints — được bootstrap bằng model frontier rồi human annotator verify lại với tolerance. Điều này cho phép scoring bằng exact data-point verification chứ không phải so sánh text overlap như cách cũ.
Vì sao quan trọng?
Enterprise document là nơi chart cực kỳ phổ biến: báo cáo tài chính có bar chart doanh thu, báo cáo y tế có biểu đồ xét nghiệm, hợp đồng bảo hiểm có biểu đồ tỉ lệ bồi thường. Nếu RAG pipeline hoặc agent không parse được chart thành structured data, toàn bộ downstream reasoning sẽ thiếu 30-50% thông tin định lượng quan trọng.
ParseBench là nỗ lực đầu tiên đo chính xác khoảng cách này — và kết quả khá shock: phần lớn specialized OCR parser scored dưới 6% vì họ chỉ OCR text chứ không trích chart data ra table.
Fact kỹ thuật chi tiết

| Thông số | Giá trị |
|---|---|
| Tổng số trang human-verified | ~2.000 |
| Trang chứa chart | 568 |
| Số test rule | 167.000+ |
| Số phương pháp evaluated | 14 |
| Số pre-configured pipeline | 90+ |
| Nguồn document gốc | 1.200+ public docs (insurance, finance, government) |
| 5 chiều đánh giá | Tables, Charts, Content Faithfulness, Semantic Formatting, Visual Grounding |
Ground-truth pipeline
- Frontier VLM sinh annotation ban đầu
- Human annotator review + sửa từng trang
- Workflow tailored riêng cho từng chiều (chart dùng tolerance numeric, text dùng rule-based)
So sánh: Ai đang thắng?
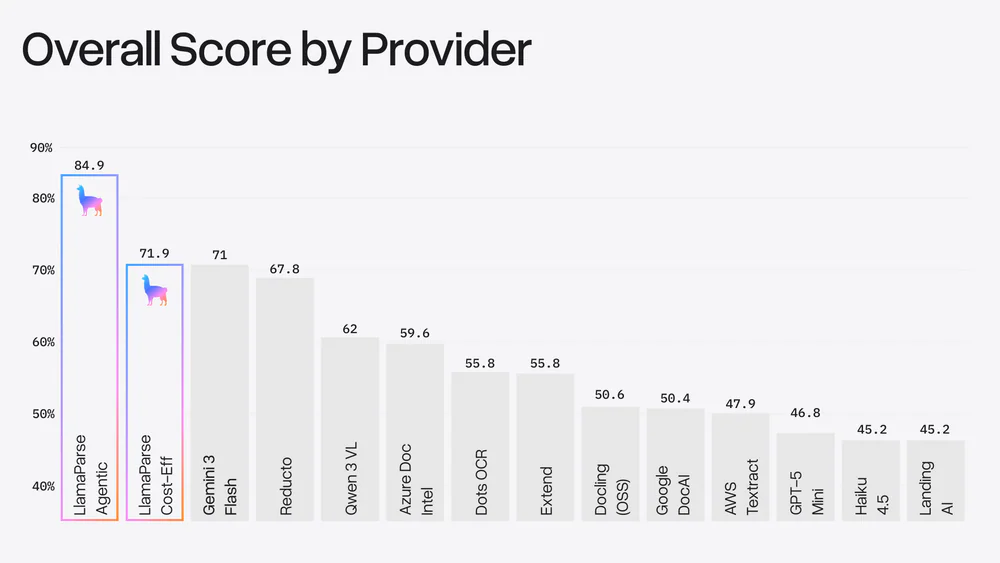
| Method | Overall | Nhóm |
|---|---|---|
| LlamaParse Agentic | 84.9% | LlamaIndex |
| LlamaParse Cost-Eff | 71.9% | LlamaIndex |
| Gemini 3 Flash | 71.0% | VLM |
| Reducto | 67.8% | Specialized |
| Qwen 3 VL | 62.0% | VLM |
| Azure Doc Intelligence | 59.6% | Specialized |
| Dots OCR | 55.8% | Specialized |
| Google DocAI | 50.4% | Specialized |
| AWS Textract | 47.9% | Specialized |
| GPT-5 Mini | 46.8% | VLM |
| Claude Haiku 4.5 | 45.2% | VLM |
| LandingAI | 45.2% | Specialized |
Điểm đáng chú ý từng chiều:
- Charts: Chỉ 4 provider vượt 50%. Specialized parsers phần lớn <6% — vì họ không extract chart data ra table.
- Content Faithfulness: Top methods đạt ~90% — nhưng nghĩa là vẫn 1/10 trang có lỗi đáng kể (missing, hallucination, sai reading order).
- Semantic Formatting: Dải điểm cực rộng, từ 1.0% tới 85.2%.
- Visual Grounding: VLM <8%; specialized parser 55-80% — specialized thắng rõ ở chiều này.
Use cases thực tế
- Financial due diligence: trích số liệu từ 10-K, earnings report để feed vào agent phân tích
- Insurance claims: parse biểu đồ xét nghiệm y tế trong hồ sơ bồi thường
- Contract analysis: extract bảng điều khoản, chart penalty structure
- Invoice processing: đảm bảo line item + total khớp, không miss field
- RAG enterprise: đảm bảo chart data vào vector store dưới dạng structured, không lost trong text blob
Giá & availability
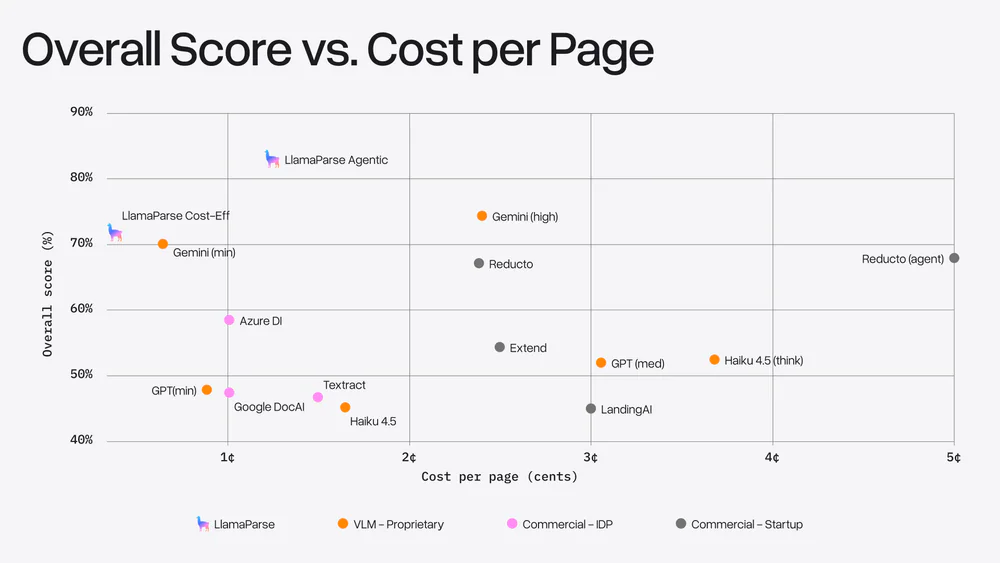
- LlamaParse Agentic: ~1.2¢/trang — quality 84.9%, outperform mọi competitor ở mọi mức giá
- LlamaParse Cost-Effective: <0.4¢/trang — cạnh tranh với Gemini 3 Flash nhưng rẻ hơn đáng kể
- ParseBench dataset + code: hoàn toàn open-source (HuggingFace + GitHub)
- Community có thể submit pipeline custom để đánh giá
Điều sắp tới
LlamaIndex sẽ ra mắt public leaderboard trên parsebench.ai để track điểm real-time khi có pipeline mới. Benchmark được thiết kế mở: bạn có thể clone repo, chạy evaluation script với model của mình, và compare thẳng với 14 baseline đã có.
Với hiện trạng 90% AI agent enterprise đều phải "ăn" PDF có chart/table, ParseBench nhiều khả năng sẽ thành standard de-facto giống cách MTEB làm với embedding hoặc HumanEval làm với code. Nếu bạn đang xây RAG pipeline trên enterprise document, đây là benchmark bắt buộc kiểm tra trước khi chốt vendor.
Nguồn: LlamaIndex blog, arXiv 2604.08538, HuggingFace dataset, GitHub, Jerry Liu on X.
