
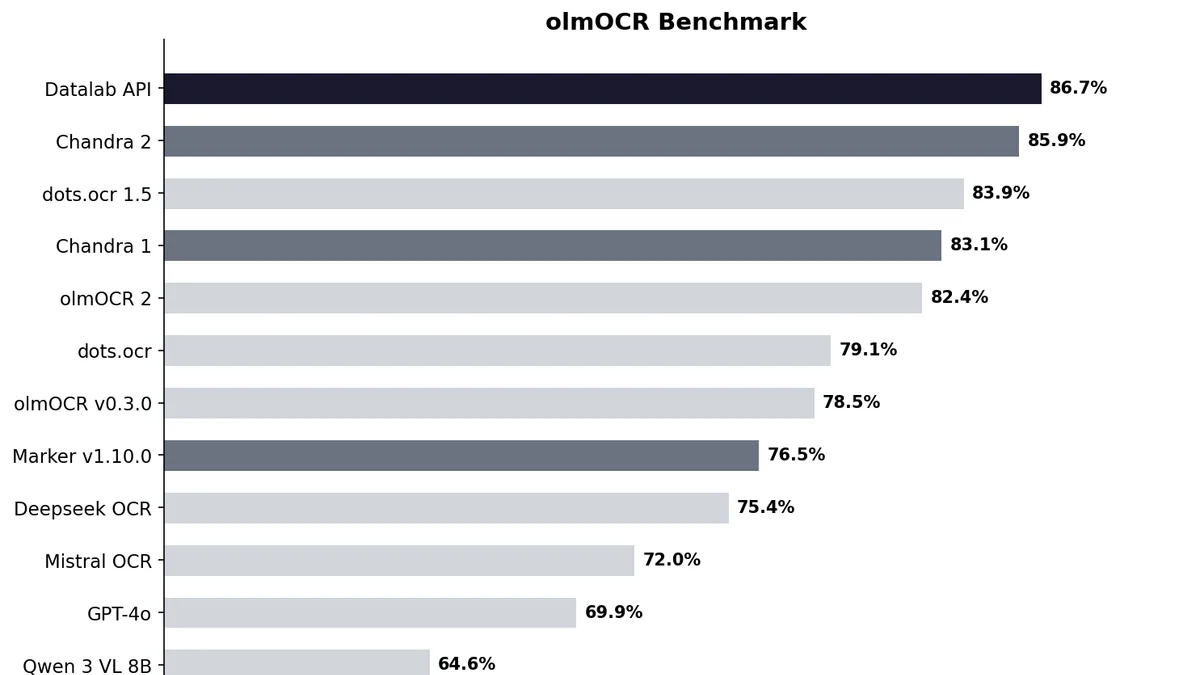
- Datalab vừa phát hành Chandra OCR 2 — mô hình OCR open-weight 4B đạt 85.9% trên olmOCR bench (SOTA), nhỏ hơn nửa so với v1 nhưng chính xác hơn.
- Hỗ trợ 90+ ngôn ngữ, bảng phức tạp, viết tay, công thức LaTeX, và caption ảnh tự động.
TL;DR
Chandra OCR 2 là mô hình OCR open-weight do Datalab phát hành tháng 3/2026. Chỉ 4B tham số (giảm từ 9B ở v1) nhưng đạt 85.9% trên olmOCR benchmark — state-of-the-art trong nhóm open-source, vượt dots.ocr 1.5 (83.9%), olmOCR 2 (82.4%), Deepseek OCR (75.4%) và GPT-4o (69.9%).
Output thẳng ra Markdown / HTML / JSON với layout đầy đủ, hỗ trợ 90+ ngôn ngữ, bảng có merged cell, viết tay, công thức LaTeX, và auto-caption ảnh/diagram. Code Apache 2.0, weights free cho startup dưới $2M doanh thu.
Có gì mới ở Chandra 2
Khác biệt lớn nhất so với pipeline OCR truyền thống: Chandra 2 dùng full-page decoding. Thay vì segment trang thành từng block (text / table / image) rồi xử lý riêng — cách mà mọi pipeline OCR cổ điển và cả Marker/Surya của chính Datalab đang làm — Chandra 2 đẩy nguyên trang vào một vision-language model (build trên Qwen3 VL / Qwen 3.5) và decode trong một forward pass duy nhất.
4B params, max output 8,192 tokens.
Output:
markdown,html, hoặcjson— chọn theo workflow.Layout giữ nguyên: multi-column, sidebar, header phân cấp, không bị flatten thành text stream.
Bảng giữ
colspan/rowspan, form giữ liên kết label ↔ checkbox.Equation render thành LaTeX; ảnh/biểu đồ embed được auto-caption.
Vì sao đáng chú ý
Mọi đội đang xây RAG pipeline hoặc agent xử lý document đều biết: text dump không đủ. Bạn cần bảng vẫn là bảng, form vẫn có label, ảnh có caption, và layout không bị xáo trộn. Một file PDF báo cáo tài chính, một form bảo hiểm tích checkbox, một note viết tay của bác sĩ - đây là chỗ OCR truyền thống vỡ trận và GPT-4o cũng chỉ đạt 69.9% trên olmOCR bench.
Chandra 2 đẩy ngưỡng open-source lên 85.9% - gần với hosted API của Datalab (86.7%) - đồng thời chạy được local trên 1 GPU H100. Với startup dưới $2M doanh thu, nó miễn phí.
Số liệu kỹ thuật
Chi tiết olmOCR Benchmark (Chandra 2):
Hạng mục | Score |
|---|---|
ArXiv (papers học thuật) | 90.2 |
Old Scans Math | 89.3 |
Tables | 89.9 |
Old Scans | 49.8 |
Headers & Footers | 92.5 |
Multi-column | 83.5 |
Long tiny text | 92.1 |
Base | 99.6 |
Overall | 85.9 ± 0.8 |
Throughput (vLLM trên 1× NVIDIA H100 80GB):
Peak: 4 pages/sec (~345,000 pages/ngày).
96 concurrent sequences: 1.44 pages/sec/instance, latency trung bình 60s, P95 156s, failure rate 0%.
Real-world thực tế: ~2 pages/sec.
Trên HuggingFace, model card datalab-to/chandra-ocr-2 ghi nhận 192,099 lượt tải tháng vừa rồi. GitHub repo có 4,700+ sao.
So sánh với phần còn lại
Trên cùng olmOCR benchmark:
Model | olmOCR Overall | Ghi chú |
|---|---|---|
Datalab API (hosted) | 86.7 | Endpoint thương mại |
Chandra 2 | 85.9 | 4B, open weights |
dots.ocr 1.5 | 83.9 | Open |
Chandra 1 | 83.1 | 9B, v1 |
olmOCR 2 | 82.4 | Open (AI2) |
Deepseek OCR | 75.4 | Open |
Mistral OCR API | 72.0 | Closed |
GPT-4o (Anchored) | 69.9 | Closed |
Qwen 3 VL 8B (raw) | 64.6 | Backbone gốc |
Gemini Flash 2 (Anchored) | 63.8 | Closed |
Đáng chú ý: Chandra 2 chỉ nhỏ bằng nửa v1 (4B vs 9B) nhưng vẫn cộng thêm 2.8 điểm. Và bản thân Qwen 3 VL 8B raw chỉ đạt 64.6% - chứng tỏ phần lớn lift đến từ post-training của Datalab, không phải từ backbone.
Hỗ trợ đa ngôn ngữ
Đây là chỗ Chandra 2 vượt mặt cả Gemini 2.5 Flash. Trên benchmark 43 ngôn ngữ phổ biến: Chandra 2 đạt 77.8% trung bình, Gemini 2.5 Flash chỉ 67.6%, GPT-5 Mini 60.5%. Trên benchmark đầy đủ 90 ngôn ngữ: Chandra 2 72.7% vs Gemini 60.8% - chênh gần 12 điểm.

Chandra 2 đặc biệt mạnh ở các ngôn ngữ low-resource mà Gemini hay GPT vẫn chật vật: tiếng Bengali (72.8% vs Gemini 55.3%), Kannada (63.2% vs 24.5%), Malayalam (64.3% vs 23.8%), Tamil (77.7% vs 53.9%), Trung Quốc giản thể (88.7% vs 70.0%).
Use cases thực tế
Healthcare: form prior-auth bảo hiểm có checkbox, intake questionnaire, lab report với reference range, ghi chú viết tay của bác sĩ, discharge summary có bảng thuốc đính kèm. Đây là chỗ stress-test khắc nghiệt nhất cho OCR - và là lý do form reconstruction + handwriting + table cùng lúc là yêu cầu bắt buộc.
Tài chính / kế toán: hoá đơn, sao kê, báo cáo tài chính. Chandra giữ nguyên cấu trúc merged cell - cực kỳ quan trọng với báo cáo tài chính nơi subtotal span nhiều cột. Một user trên cộng đồng (Purchaser.ai) báo cáo tiết kiệm 6 chữ số USD nhờ tự động hóa quy trình này.
Pháp lý: hợp đồng, phán quyết toà, văn bản pháp quy - Chandra giữ nguyên phân cấp điều/khoản/bảng tham chiếu.
Nghiên cứu & lưu trữ: thư từ, sổ tay lịch sử (cursive handwriting + 90+ ngôn ngữ), bài báo khoa học (LaTeX equation).
Giới hạn & pricing
Điểm yếu:
Old Scans (tài liệu lịch sử xuống cấp): chỉ 49.8% - mảng yếu nhất, sub-50.
Không phải nhanh nhất: 4 pages/s peak so với LightOn OCR 5.55 pages/s, DeepSeek-OCR 4.65 pages/s. Đánh đổi tốc độ lấy độ chính xác.
Output cap 8,192 tokens/page - trang siêu dày có thể bị truncate.
Quantized 8B và 2B chỉ có với commercial license.
License:
Code: Apache 2.0 - dùng tự do.
Weights: modified OpenRAIL-M - free cho research, personal, và startup dưới $2M doanh thu/funding. Trên ngưỡng đó cần commercial license. Không được dùng để cạnh tranh trực tiếp với hosted API của Datalab.
Cài đặt & chạy:
pip install chandra-ocr
chandra input.pdf output/Hoặc dùng vLLM cho production. Có playground miễn phí ở datalab.to/playground - không cần đăng ký, kéo thả PDF và xem ngay output.
Bottom line
Chandra 2 không phải bước đột phá kiểu "đổi cuộc chơi" - nó là steady progress với +2.8 điểm so với v1, nhưng đạt được điều đó trong khi giảm size 56%. Quan trọng hơn, đây là mô hình OCR open-source đầu tiên thực sự có thể thay thế GPT-4o và Gemini cho production document pipeline mà không phải đánh đổi quality.
Với AI agent ăn document làm input và RAG pipeline xử lý PDF, đây là default choice mới ở tier open-source.
Áp lực bây giờ ở phía Datalab: DeepSeek, Google, OpenAI và cộng đồng open-source đều đang đầu tư mạnh vào VLM-based OCR. Bước nhảy 2.8 điểm v1→v2 sẽ phải tăng tốc nếu Chandra muốn giữ ngôi vương.
Nguồn: HuggingFace model card, Datalab blog, GitHub repo, The Menon Lab.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ