
- IceCache (ICLR 2026) group token theo ngữ nghĩa qua DCI-tree rồi offload sang CPU, chỉ giữ top-k page trên GPU.
- Kết quả: 99% accuracy full-cache ở budget 256 token, ngang hoặc vượt 6 SOTA baseline với 25% KV budget.
TL;DR
IceCache là phương pháp quản lý KV-cache mới cho LLM long-context, vừa được accept tại ICLR 2026 (poster). Thay vì evict token theo attention score như SnapKV/StreamingLLM, nó group các token có key-embedding gần nhau vào cùng memory page (qua một cấu trúc gọi là DCI-tree), offload phần lớn sang CPU, rồi chỉ kéo top-k page liên quan nhất về GPU trong mỗi decode step. Số liệu đáng chú ý: giữ 99% accuracy so với full KV-cache ở budget 256 token trên LongBench, và chỉ cần 25% KV budget để sánh ngang hoặc vượt 6 SOTA baseline.
What's new
Vấn đề cũ: khi LLM sinh câu trả lời dài (chain-of-thought, agent loop, multi-turn chat), KV-cache phình tuyến tính theo độ dài sequence và ăn sạch VRAM. Cách phổ biến là offload sang CPU rồi kéo về GPU một subset token, nhưng các method hiện tại (SnapKV, StreamingLLM, OmniKV, MagicPig, PQCache, ArkVale) đều chọn token theo attention score gần đúng — imprecise khi context dài, gây hallucination hoặc lỗi reasoning.
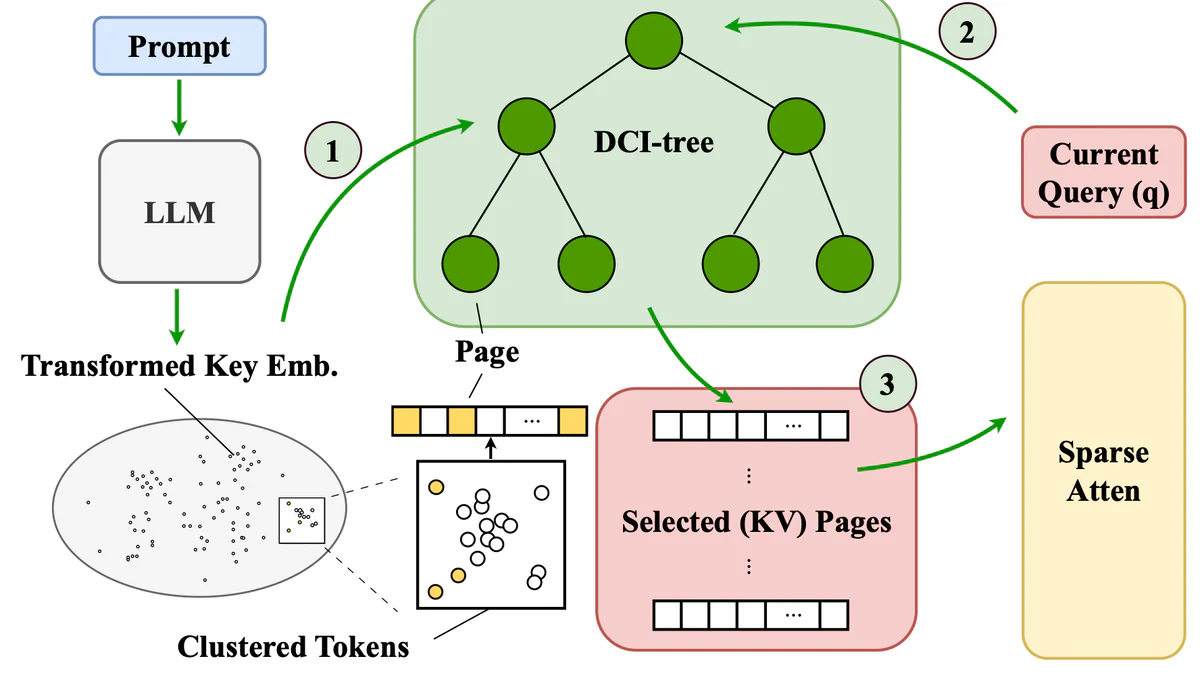
IceCache đổi góc nhìn: thay vì hỏi "token nào quan trọng?", nó group trước các token có semantic gần nhau (đo bằng key embedding), đẩy cùng nhóm vào một memory page, rồi dùng ANN search (P-DCI) để lấy top-k page khớp với query hiện tại. Hit rate cao hơn vì các token liên quan co-located trên cùng page, memory bandwidth CPU↔GPU cũng tận dụng tốt hơn.
Tác giả: Yuzhen Mao (Simon Fraser University), Qitong Wang (Harvard), Martin Ester và Ke Li (SFU). Code + demo: yuzhenmao.github.io/IceCache.
Vì sao đáng chú ý
Long-context reasoning là một trong những bottleneck đắt nhất của serving LLM hiện tại. Mô hình càng "suy nghĩ nhiều" (CoT, agent, ReAct) thì KV-cache càng phình, VRAM càng cạn, batch size càng nhỏ, chi phí/request càng cao. Nếu IceCache giữ được kết quả tốt với 25% budget, đó là giảm 4× memory mà không đổi mô hình — tức có thể batch cao hơn, hoặc chạy context 100k+ trên GPU 24GB thay vì phải nhảy lên H100 80GB.
Điểm mới về mặt kỹ thuật: DCI-tree dynamic-updatable — không cần rebuild khi token mới xuất hiện, khớp thẳng với pattern autoregressive generation của LLM. Đây là điểm nhiều method ANN trước đó chết (FAISS/HNSW phải rebuild).
Chi tiết kỹ thuật
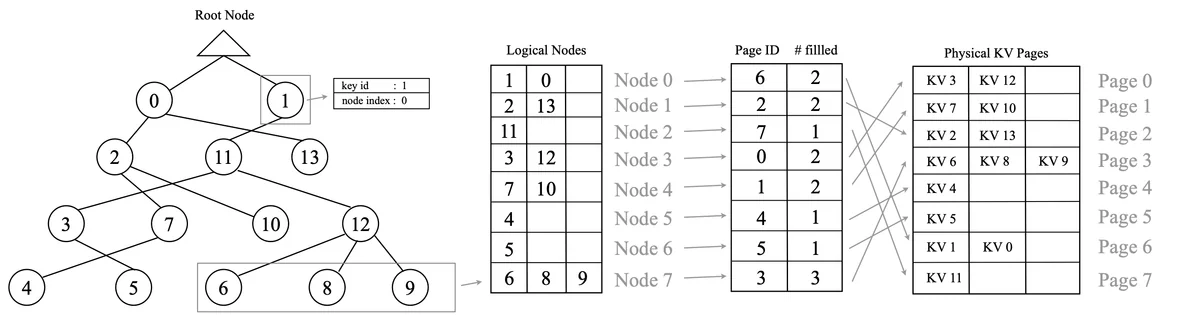
DCI-tree là cấu trúc hierarchical tree cho mỗi attention head, cluster key embeddings theo semantic similarity, mỗi node map 1:1 với một memory page trong PagedAttention. P-DCI (Prioritized DCI) là ANN search algorithm chạy per-head, chọn top-k page liên quan nhất cho query hiện tại.
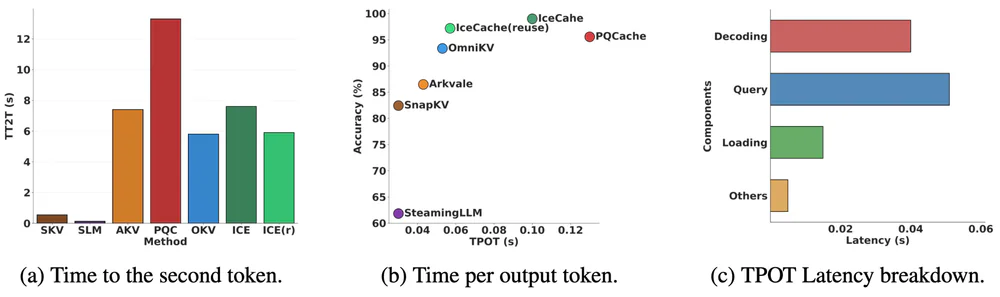
Latency breakdown trên sequence 36k token (TPOT — time per output token):
| Giai đoạn | Thời gian | % tổng |
|---|---|---|
| DCI-query (ANN search) | 0.050 s | 45% |
| Decoding (forward pass) | 0.040 s | 36% |
| GPU↔CPU offloading | 0.015 s | 14% |
| Misc | 0.005 s | 5% |
| Tổng TPOT | 0.110 s | 100% |
Benchmark suite: LongBench, RULER (150k–250k context), Passkey Retrieval, GSM8K Chain-of-Thought. Models test: Llama-3.1-8B-Instruct, Mistral-7B-Instruct, Qwen3-4B-Instruct-2507.
So sánh với 6 SOTA baseline
IceCache đấu trực tiếp với toàn bộ nhóm KV-cache offloading/compression đang được dùng phổ biến:
| Baseline | Cơ chế chính | Điểm yếu so với IceCache |
|---|---|---|
| SnapKV (SKV) | Evict theo attention pattern | Imprecise ở long-gen, drop token quan trọng |
| StreamingLLM (SLM) | Giữ sink + recent | Mất thông tin giữa context |
| OmniKV (OKV) | Layer-wise selective offload | Chưa group theo semantic |
| MagicPig (MPG) | LSH-based top-k retrieval | Hash collision, precision thấp |
| PQCache (PQC) | Product quantization | Lossy, recall kém ở budget thấp |
| ArkVale (AKV) | Value-aware caching | Không tận dụng semantic locality |
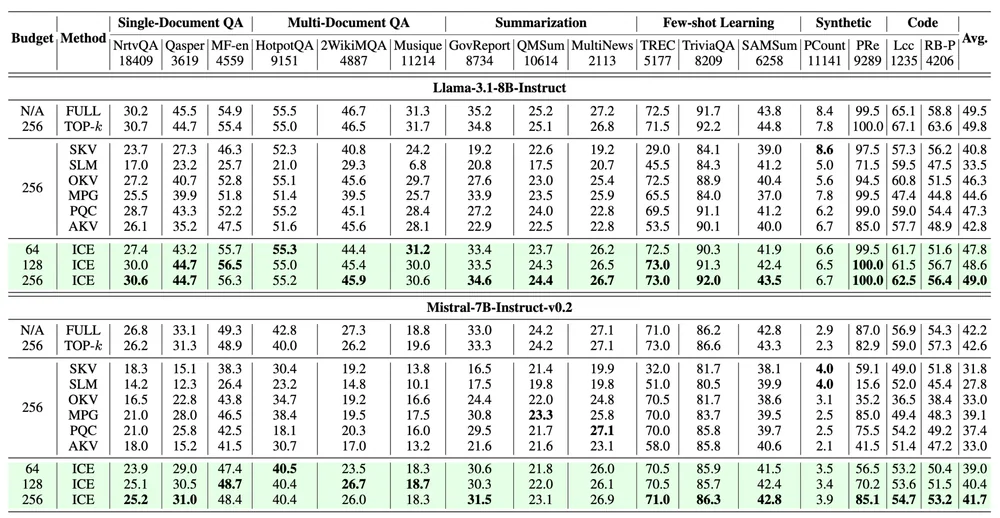
Paper báo cáo IceCache và variant IceCache(r) generally outperform cả 6 baseline trên LongBench ở mọi budget thử, khoảng cách lớn nhất ở budget nhỏ (128–256 token) — đúng chỗ các method cũ rơi rụng.
Use cases
- Self-host LLM trên consumer GPU (24GB): chạy context 100k+ với Llama-3.1-8B mà không cần nhảy lên H100.
- Chain-of-thought / reasoning dài: nơi KV cache phình nhanh nhất và token selection sai gây lỗi logic (GSM8K CoT là benchmark có trong paper).
- Agent loop / multi-turn chat: session dài tích luỹ context, offload bền vững quan trọng.
- Serving cost reduction: 4× VRAM headroom = batch size gấp 2–4 trên cùng GPU, giảm $/request.
Limitations & pricing
- DCI-query overhead: module ANN ăn ~45% TPOT. Trên GPU yếu có thể bottleneck ngược.
- Scale: benchmark chính ở model ≤ 8B. Chưa có số cho 70B+ trong paper.
- Runtime: cần PagedAttention backend (vLLM-style). Không plug-n-play với llama.cpp hay mọi runtime.
- Budget floor: con số "99% accuracy" là ở budget 256 token trên LongBench. Dưới nữa thì curve sẽ rơi.
- Giá: research open-source — code public trên project site, paper free trên arXiv/OpenReview.
What's next
Paper đã accepted ICLR 2026 (poster), sẽ present tại conference. Hướng mở rộng rõ ràng: scale lên 70B model, kết hợp với KV quantization (INT8/INT4) để combo saving, và integrate vào vLLM production stack. Với 6 SOTA baseline bị vượt cùng lúc, nhiều khả năng IceCache sẽ được các team self-host (Ollama wrapper, vLLM fork) thử nghiệm trong vài tháng tới.
Nguồn: arXiv 2604.10539, OpenReview (ICLR 2026), project website, announcement X/Twitter.



