
- Microsoft Research vừa công bố MEMENTO — phương pháp huấn luyện cho phép LLM tự cắt chuỗi suy luận thành từng khối, nén mỗi khối thành một bản tóm tắt dày đặc rồi tiếp tục "nghĩ" chỉ dựa trên các bản tóm tắt đó.
- Kết quả: peak KV cache giảm ~2.5×, throughput tăng ~1.75× trên vLLM, độ chính xác gần như không đổi.
- Đây là lần đầu một mô hình học cách tự quản lý context thay vì chỉ mở rộng nó.
TL;DR
Ngày 8/4/2026, Microsoft Research phát hành MEMENTO — kỹ thuật huấn luyện LLM tự chia chuỗi suy luận thành các khối, nén mỗi khối thành một memento (tóm tắt trạng thái dày đặc), rồi xoá khối gốc khỏi KV cache và tiếp tục suy luận chỉ dựa trên các memento. Kèm theo là dataset OpenMementos 228K, công thức SFT 2 giai đoạn, và bản vLLM fork hỗ trợ block masking — toàn bộ MIT-licensed.

Điểm mới
Các mô hình reasoning hiện tại (o1, DeepSeek-R1, Qwen3-Thinking…) sinh ra hàng chục nghìn token chain-of-thought rồi giữ toàn bộ trong KV cache. Bộ nhớ phình tuyến tính, chi phí serving đội lên, và nhiều thông tin trong chuỗi thực ra đã hết giá trị ở bước sau.
MEMENTO làm ngược lại. Mô hình được dạy để tự phát hiện ranh giới ngữ nghĩa giữa các khối suy luận, rồi với mỗi khối đã xong, sinh ra một memento — không phải là "tóm tắt" theo nghĩa kể lại, mà là nén trạng thái: đủ cô đọng để mô hình có thể tiếp tục lập luận chỉ từ memento, không cần nhìn lại khối gốc nữa. Sau khi memento xuất hiện, khối gốc bị mask khỏi attention và xoá vật lý khỏi KV cache, tạo ra mẫu "răng cưa" đặc trưng: bộ nhớ leo lên trong mỗi khối rồi rơi mạnh tại điểm memento.
Vì sao điều này quan trọng
Đây không phải là thêm một mẹo nén KV cache theo kiểu thống kê (H2O, SnapKV, quantize). Các kỹ thuật đó nén sau khi mô hình đã sinh token. MEMENTO dịch chuyển việc nén vào bên trong quá trình suy luận, và bản thân mô hình là thứ quyết định giữ gì, bỏ gì.
Nói cách khác: mô hình bắt đầu quản lý context của chính nó. Đây là một bước nhỏ nhưng rõ rệt từ "LLM là bộ sinh token" sang "LLM là tác nhân có khả năng tổ chức bộ nhớ làm việc". Với nền reasoning-model đang trở thành mặc định, thay đổi này chạm trực tiếp vào chi phí serving — thứ đang là nút thắt lớn nhất của cả ngành.
Số liệu kỹ thuật
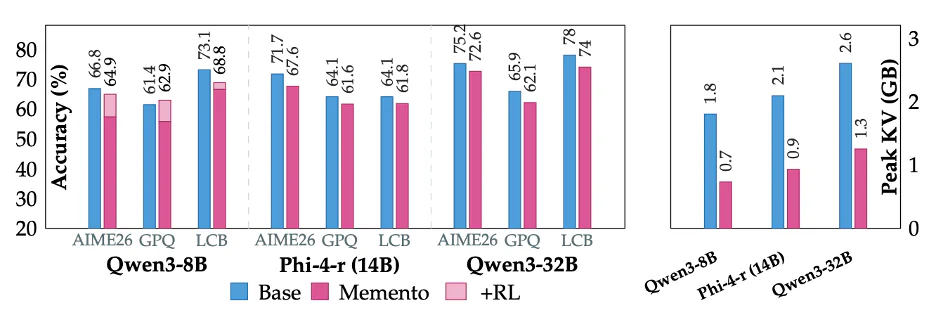
- ~2.5× giảm peak KV cache (báo cáo chi tiết: 2–3× tuỳ mô hình).
- ~1.75× throughput trên vLLM — 4,290 tok/s vs 2,447 tok/s baseline trên GPU B200, duy trì 240 request đồng thời ở 32K max tokens.
- ~6× nén ở mức trace: ~10,900 token suy luận → ~1,850 token memento mỗi trace.
- Chỉ cần ~30K mẫu SFT để dạy được kỹ năng này.
- Độ chính xác trên AIME26, GPQA, LiveCodeBench gần như bám baseline; RL fine-tuning ở Stage 3 thu hẹp hoặc vượt gap còn lại.
So sánh
| Phương pháp | Kiểu nén | Giảm KV | Ảnh hưởng accuracy |
|---|---|---|---|
| Baseline CoT | Không | 1× | Mốc |
| Token eviction (H2O, SnapKV) | Post-hoc thống kê | 2–4× | Giảm rõ ở reasoning |
| KV quantization | Post-hoc độ chính xác | 2–4× | Nhỏ, đều |
| MEMENTO | Học trong lúc sinh | ~2.5× | Gần bằng / vượt sau RL |
Điểm khác biệt cốt lõi: nén của MEMENTO biết về nhiệm vụ. Memento giữ kết luận, công thức, giá trị trung gian, và quyết định chiến lược — đúng những gì cần để đi tiếp. Token eviction thì không có khái niệm đó.
Ứng dụng
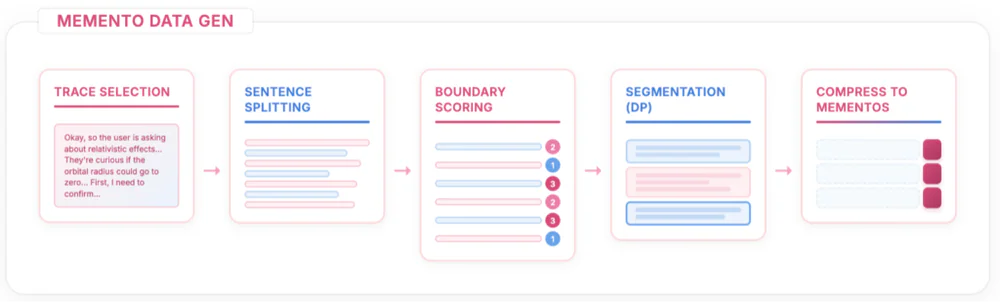
- Reasoning dài hạn: toán olympic (AIME), QA khoa học, competitive programming — những nơi mô hình phải sinh 10K+ token suy luận.
- Giảm chi phí serving: gần 2× throughput trên cùng phần cứng, nghĩa là hoá đơn GPU cho reasoning workload có thể chia đôi.
- Agent đa lượt: nhóm tác giả khẳng định đây là hướng tiếp theo — "pattern block-and-compress áp dụng được cho mọi tình huống mô hình tích luỹ trajectory trung gian dài".
- Kéo dài output hiệu quả: vì KV không còn tăng tuyến tính với trace, mô hình có thể "nghĩ" lâu hơn trong cùng ngân sách bộ nhớ.
Đối tượng hưởng lợi rõ nhất: nhà cung cấp inference, team fine-tune open-weight (Qwen3, Phi-4, OLMo3), và builder framework agent.
Hạn chế & pricing
- Không có checkpoint pre-trained — phải tự mang base model và chạy SFT 2 giai đoạn. Dataset và recipe có, trọng số thì không.
- Lệch phân phối huấn luyện: OpenMementos được sinh với QwQ-32B làm teacher, nên khi áp lên họ mô hình khác có gap nhỏ do dữ liệu, không phải do bản thân kỹ thuật nén.
- Cần curriculum: Stage 1 (causal attention, học format) → Stage 2 (full block masking) → Stage 3 tuỳ chọn (RL). Bỏ Stage 1 là hỏng.
- Phụ thuộc "dual information stream": trạng thái KV của các memento sau vẫn mang dấu vết khối đã xoá. Nếu restart cache cưỡng bức giữa các khối thì mất ~15 điểm phần trăm accuracy trên AIME24.
- Giá: hoàn toàn mở, MIT license. Không API, không tier trả phí. Muốn dùng phải tự tích hợp qua vLLM fork.
Điều gì tiếp theo
Tác giả nêu rõ agent applications là biên giới kế tiếp — mở rộng block-and-compress sang trajectory tool-use nhiều lượt. Về phía hệ sinh thái, cần chú ý: vLLM upstream có thể merge block masking natively, và cộng đồng nhiều khả năng sẽ public các checkpoint Qwen3-Memento / Phi-4-Memento trên Hugging Face trong vài tuần tới.
Bức tranh lớn: chúng ta đang chứng kiến LLM không còn chỉ "được cung cấp" context, mà bắt đầu định hình context của chính nó. Với reasoning-model đã là mặc định và agent-model đang là làn sóng kế tiếp, một kỹ thuật dạy mô hình tự quyết định nhớ gì — quên gì — đi tiếp thế nào có thể sẽ là nền tảng, không phải optimization phụ trợ.
Nguồn: Microsoft Research, arXiv 2604.09852, HuggingFace OpenMementos, GitHub microsoft/memento.



