
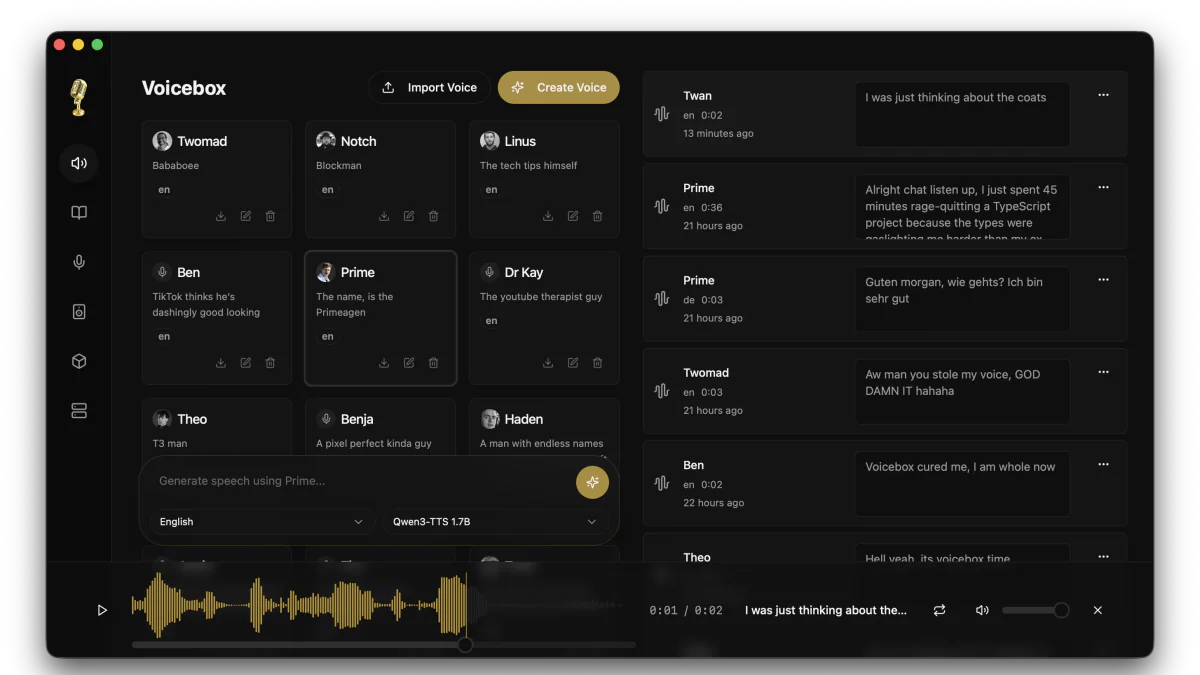
- Voicebox is a free, MIT-licensed voice studio that runs entirely on your machine.
- Clone any voice from 3 seconds of audio, generate speech in 23 languages across 7 TTS engines, and drive it all through a local REST API on port 17493 — no subscriptions, no rate limits, no cloud.
TL;DR
Voicebox is a free, open-source desktop app by Jamie Pine that turns your laptop into a full voice-AI studio. Clone any voice from 3 seconds of audio, generate speech in 23 languages across 7 TTS engines, and drive everything through a local REST API at http://127.0.0.1:17493. The repo just crossed 23k stars with v0.4.5 shipping two days ago, and it's positioned as a direct, MIT-licensed replacement for ElevenLabs — minus the subscriptions, rate limits, and cloud dependency.
What's new
Voicebox bundles seven state-of-the-art open-source TTS models behind one Tauri (Rust) desktop client. You can switch engines per generation, mix multiple voices on a timeline, and ship voice lines through a localhost API — all without leaking a single byte to a third-party server.
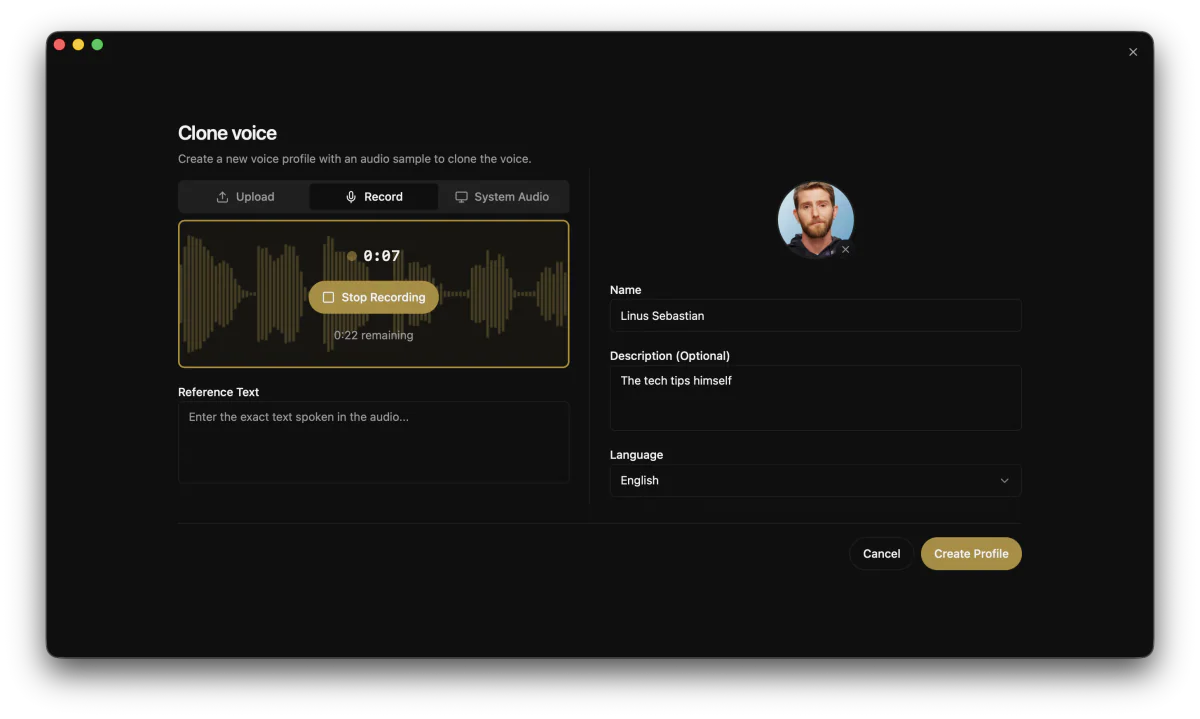
- Zero-shot voice cloning from a 3-second sample (upload, mic, or system audio capture from a YouTube clip).
- 50+ preset voices via Kokoro and 9 premium speakers via Qwen CustomVoice for those who don't want to clone.
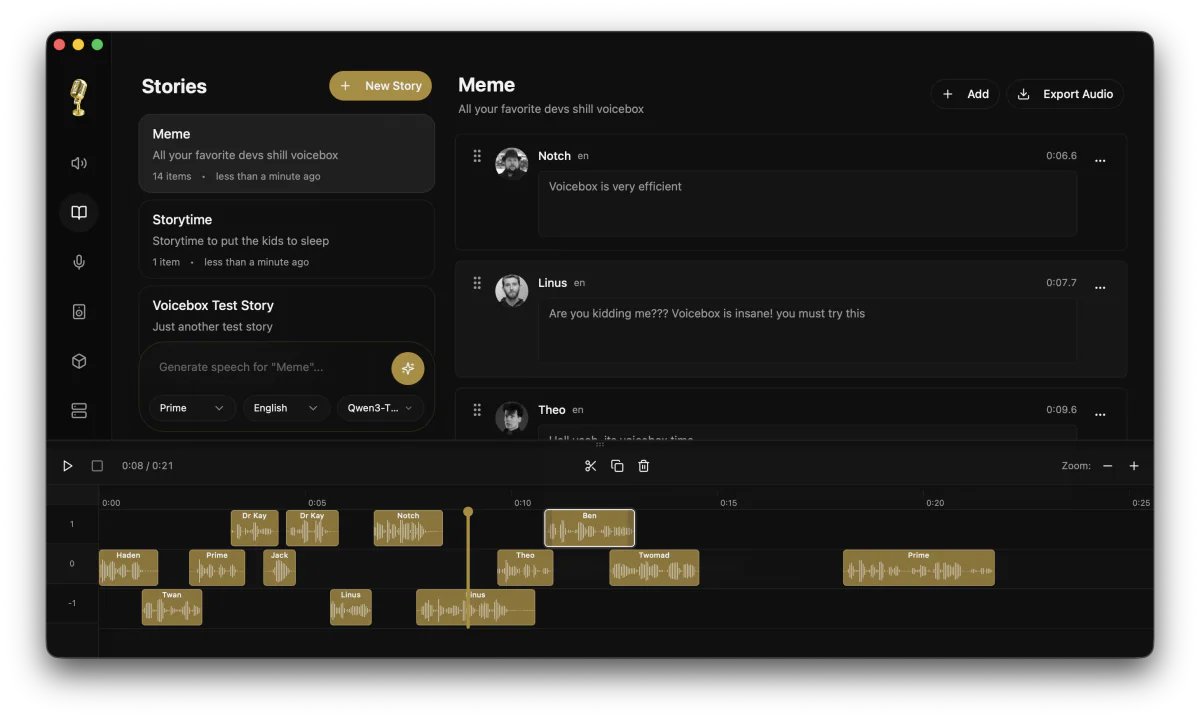
- Stories editor — multi-track timeline for podcasts, NPC dialogue, and multi-character narration.
- Built-in REST API on port 17493 with OpenAPI docs — the real unlock for AI agents and games.
- Whisper transcription baked in, so reference text is auto-extracted from voice samples.
Why it matters
Commercial voice tools like ElevenLabs gate the good stuff behind subscriptions and per-character meters. That's fine for a one-off ad read, brutal for an audiobook, an indie game with 5,000 NPC lines, or an AI agent that talks all day. Voicebox flips the economics: download once, generate forever, on your own GPU.
The privacy angle is just as load-bearing. Unreleased game scripts, internal training narration, and confidential client voiceovers never leave the machine. Qwen team benchmarks even show their 1.7B model beating ElevenLabs in Word Error Rate on Chinese, English, Italian, and Spanish — so the “open-source = lower quality” assumption no longer holds.
Technical facts
The seven engines are not interchangeable — each has a niche. Pick the one that fits the workload:
| Engine | Size | Strength |
|---|---|---|
| Qwen3-TTS | 0.6B / 1.7B | Highest-quality multilingual cloning, 10 languages |
| Qwen CustomVoice | 0.6B / 1.7B | 9 preset voices, natural-language delivery (“warm, slow, cinematic”) |
| Chatterbox Multilingual | — | Broadest coverage: 23 languages |
| Chatterbox Turbo | 350M | Only engine that interprets [laugh], [sigh], [gasp] tags |
| HumeAI TADA | 1B / 3B | Long-form coherent audio, 700s+ without drift |
| LuxTTS | — | 150x realtime on CPU, ~1GB VRAM, 48kHz output |
| Kokoro | 82M | Tiny, CPU-realtime, 50 preset voices |
Other hard numbers worth knowing: max 50,000 characters per generation (auto-chunked at sentence boundaries with a 0–200ms crossfade), 8 audio effects via Spotify's Pedalboard library, and a model footprint of 2–4 GB for Qwen3-TTS that auto-downloads from HuggingFace on first use.
Comparison vs ElevenLabs
| Dimension | Voicebox | ElevenLabs |
|---|---|---|
| Cost | $0 forever, MIT license | Subscription + per-character meter |
| Privacy | 100% local, no network after model download | Cloud upload required |
| Quality (WER) | Qwen3-TTS 1.7B beats EL on zh/en/it/es | Slight edge on de/pt |
| Real-time streaming | Not yet (on roadmap) | Yes |
| Hardware | Your GPU (or CPU) | Their cloud cluster |
| Expressive control | Natural-language instruct + paralinguistic tags | Limited preset emotions |
Use cases
- Game devs: generate NPC dialogue on the fly, localize characters into 23 languages, ship expressive lines without booking a studio.
- AI agents: POST to
/generateon localhost and your agent has a voice — zero per-character cost, zero rate limits, runs on the user's machine. - Podcasters: use the Stories timeline to mix multi-character conversations from a single keyboard.
- Audiobook authors: batch-generate up to 50,000 chars per run with auto-chunking and crossfade.
- Accessibility devs: ship offline screen-readers that use a familiar voice, no network required.
For developers, the killer detail is that Voicebox is “just a localhost URL.” A minimal generation call:
curl -X POST http://127.0.0.1:17493/generate \
-H "Content-Type: application/json" \
-d '{"text":"Welcome to the game, player one.","profile_id":"...","engine":"qwen_custom_voice","instruct":"warm, slow, cinematic"}' \
--output line.wavLimitations & pricing
Pricing is the easy part: free, MIT license, forever. The trade-offs sit elsewhere.
- No real-time streaming yet. Audio is generated chunk-by-chunk; word-by-word streaming is on the roadmap.
- Linux: no prebuilt binaries (blocked by GitHub Actions disk-space limits) — build from source for now. macOS (Apple Silicon + Intel), Windows MSI, and Docker Compose are first-class.
- CPU-only inference on Windows/Intel is noticeably slow. NVIDIA CUDA or Apple MLX recommended.
- Paralinguistic tags (
[laugh],[sigh]) only work in Chatterbox Turbo — other engines read them literally. - No mobile companion app and no live conversation mode — both planned.
What's next
The roadmap is unusually crisp: real-time streaming, voice design from text-only descriptions, live conversation mode, mobile remote control, a plugin architecture for custom models, and XTTS + Bark engine support. Linux prebuilt binaries land as soon as the CI disk-space issue is unblocked. With 24 releases shipped in roughly three months, the velocity is real.
If you've been waiting for a moment to stop paying per-character for synthetic voice, this is it. Grab the installer from voicebox.sh, point your AI agent at http://127.0.0.1:17493, and own your voice stack.
Sources: github.com/jamiepine/voicebox, voicebox.sh, QwenLM/Qwen3-TTS, scriptbyai.

