
- LlamaIndex vừa công bố ParseBench — benchmark document parsing đầu tiên thiết kế riêng cho AI agents, với 2.000 trang enterprise, 169k+ test rules và metric mới ChartDataPointMatch chấm đúng điểm dữ liệu trong biểu đồ thay vì chỉ OCR caption.
TL;DR
ParseBench là benchmark document parsing đầu tiên được thiết kế riêng cho AI agents — không phải cho người đọc caption. LlamaIndex release Apache-2.0, gồm ~2.000 trang tài liệu enterprise, 169k+ test rules và 5 chiều đánh giá. Điểm mới đáng chú ý: metric ChartDataPointMatch chấm parser có thực sự đọc được các điểm dữ liệu trong biểu đồ hay chỉ OCR chữ xung quanh. Kết quả cho thấy charts là nơi phân hoá mạnh nhất: chỉ 4/14 phương pháp vượt 50%, nhiều parser chuyên dụng rớt dưới 6%.

What's new
Hầu hết benchmark OCR cũ đo một tác vụ mà con người quan tâm: trích đúng text, layout, reading order. Nhưng agent thì cần dữ liệu có thể hành động được — bảng cấu trúc, số liệu cụ thể trong chart, vị trí trên trang để audit. ParseBench đóng gói đúng góc nhìn đó, chia parser theo 5 dimension task-specific:
- Tables — metric
TableRecordMatch, coi bảng như tập record keyed theo header. - Charts — metric
ChartDataPointMatch, so tới 10 điểm dữ liệu mỗi chart, exact match hoặc tolerance 1%. - Content Faithfulness — bắt omission, hallucination, sai reading order.
- Semantic Formatting — strikethrough, superscript, bold, hierarchy (những dấu hiệu mang nghĩa chứ không chỉ trang trí).
- Visual Grounding — truy vết element về toạ độ trang để agent audit được nguồn.

Why it matters
Gap mà LlamaIndex nhấn mạnh trên X rất ngắn gọn: “Most documents look at a chart and OCR the caption. Agents need the actual numbers.” Khi bạn xây agent phân tích báo cáo tài chính, hợp đồng bảo hiểm hay hồ sơ y tế, số trong biểu đồ mới là thứ có giá trị. Một parser đọc được caption nhưng trả về chart như ảnh mờ sẽ làm agent xuống tiền hoặc ra quyết định sai. ParseBench là cái thước đầu tiên chấm đúng thứ đó.
Technical facts
- ~2.000 trang do người verify từ 1.200+ tài liệu công khai (finance, insurance, government, contracts).
- 169.000+ test rules — granular đủ để chỉ ra chính xác parser gãy ở đâu.
- 14 phương pháp đánh giá (21 baseline trong paper) gồm VLM đa dụng, parser chuyên dụng và LlamaParse.
- Stack chạy benchmark gói sẵn 90+ pipeline:
uv run parse-bench run <pipeline>. - Apache-2.0 — code, dataset và evaluation hoàn toàn mở.
Comparison
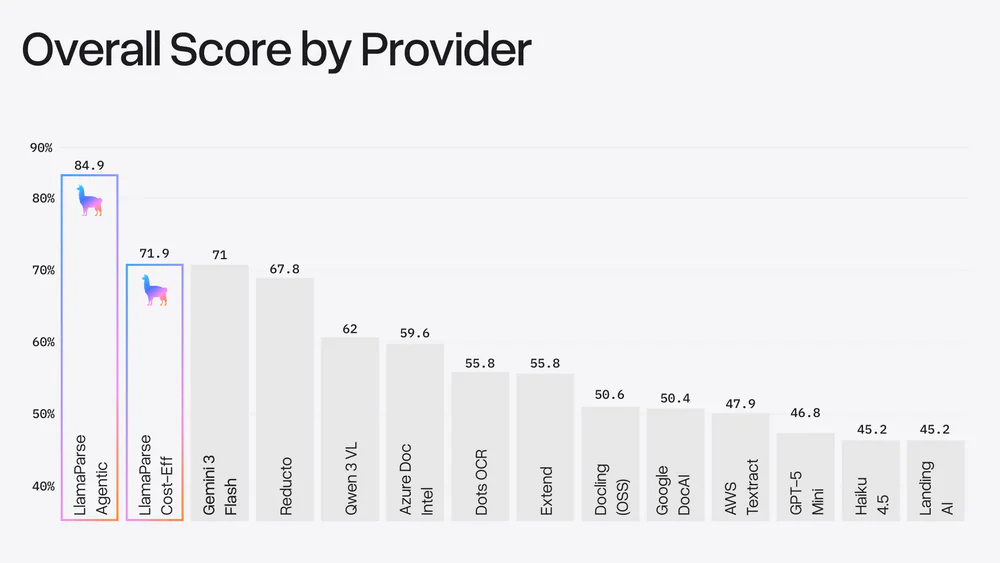
Charts đúng như LlamaIndex gọi là “the great divider”. Nhìn bảng tổng, khoảng cách giữa nhóm dẫn đầu và phần còn lại rất rõ:
| Method | Overall score | Nhóm |
|---|---|---|
| LlamaParse Agentic | 84.9% | Agentic parser |
| LlamaParse Cost-Eff | 71.9% | Agentic parser |
| Gemini 3 Flash | 71.0% | VLM |
| Reducto | 67.8% | Specialized |
| Qwen 3 VL | 62.0% | VLM |
| Azure Doc Intelligence | 59.6% | Specialized |
| Dots OCR / Extend | 55.8% | Specialized |
| Docling (OSS) | 50.6% | Specialized |
| Google DocAI | 50.4% | Specialized |
| AWS Textract | 47.9% | Specialized |
| GPT-5 Mini | 46.8% | VLM |
| Haiku 4.5 / Landing AI | 45.2% | VLM / Specialized |
Một vài pattern đáng chú ý theo từng dimension:
- Charts: chỉ 4/14 provider vượt 50%; hầu hết parser chuyên dụng <6% vì không bao giờ chuyển chart thành bảng dữ liệu.
- Semantic Formatting: trải rộng từ 1.0% (Docling) tới 85.2% (LlamaParse Agentic). Đa số parser coi strikethrough/superscript là “cosmetic” và xoá — trong khi trong hợp đồng, strikethrough = điều khoản đã xoá.
- Visual Grounding: VLM <8% (GPT-5 Mini, Haiku 4.5); parser truyền thống 55–80% nhờ có pipeline layout chuyên biệt.
- Content Faithfulness: top ~90% — vẫn ~1 lỗi mỗi 10 trang. High-stakes workflow phải tính.
Use cases
- Phân tích báo cáo tài chính (10-K, S-1): giá trị nằm trong biểu đồ và bảng — đúng hai dimension ParseBench chấm khó nhất.
- Review hợp đồng / bảo hiểm: semantic formatting quan trọng vì điều khoản bị gạch ngang khác hoàn toàn điều khoản còn hiệu lực.
- Compliance / tài liệu chính phủ: visual grounding giúp agent trả lời “số này lấy từ đâu trên trang nào?” — yêu cầu audit bắt buộc.
- Research copilot: đọc paper khoa học nơi insight nằm trong chart; caption không đủ.
Limitations & pricing
- Không method nào top ở cả 5 dimension — chọn parser vẫn là bài toán trade-off theo workload.
- VLM yếu về spatial reasoning → visual grounding kém; tables phức tạp (merged cell, hierarchical header, multi-page) còn gãy nhiều.
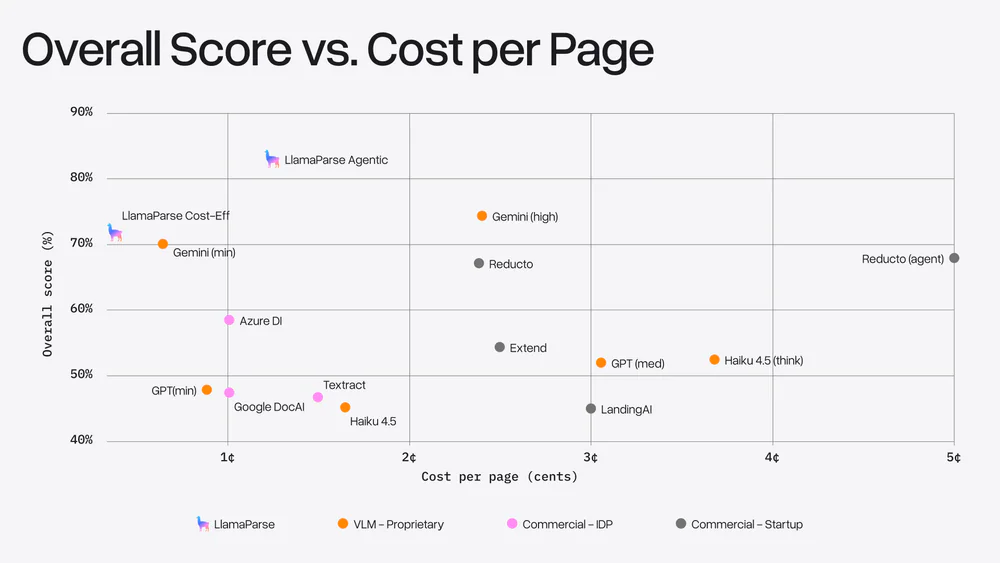
- Về chi phí: LlamaParse Agentic ~1,2¢/trang @ 84.9%; Cost-Effective <0,4¢/trang cạnh tranh với Gemini minimal thinking. VLM diminishing returns: tăng 3–4× chi phí chỉ +5 pp.
- 10.000 credit miễn phí tại cloud.llamaindex.ai. Dataset + code hoàn toàn mở, ai cũng chạy được trên parser của mình.
What's next
Hướng đi hợp lý cho team đang xây agent trên tài liệu: (1) chạy ParseBench trên parser hiện tại, soi điểm số theo dimension mình quan tâm — rất có thể chart hoặc semantic formatting đang là gót chân Achilles; (2) đóng góp pipeline mới vào repo để so sánh công khai; (3) theo dõi các split adversarial mà LlamaIndex hint sẽ bổ sung để benchmark không bị saturate như OmniDocBench.
Nguồn: llamaindex.ai/blog/parsebench, GitHub run-llama/ParseBench, Hugging Face dataset, arXiv 2604.08538.
