
- MetaClaw biến mỗi cuộc hội thoại thành tín hiệu học.
- Vừa chèn skill vào prompt tức thời, vừa fine-tune LoRA trên cloud trong lúc bạn ngủ hoặc họp.
- Kimi-K2.5 nhảy từ 21.4% lên 40.6%, gần bằng GPT-5.2 baseline.
TL;DR
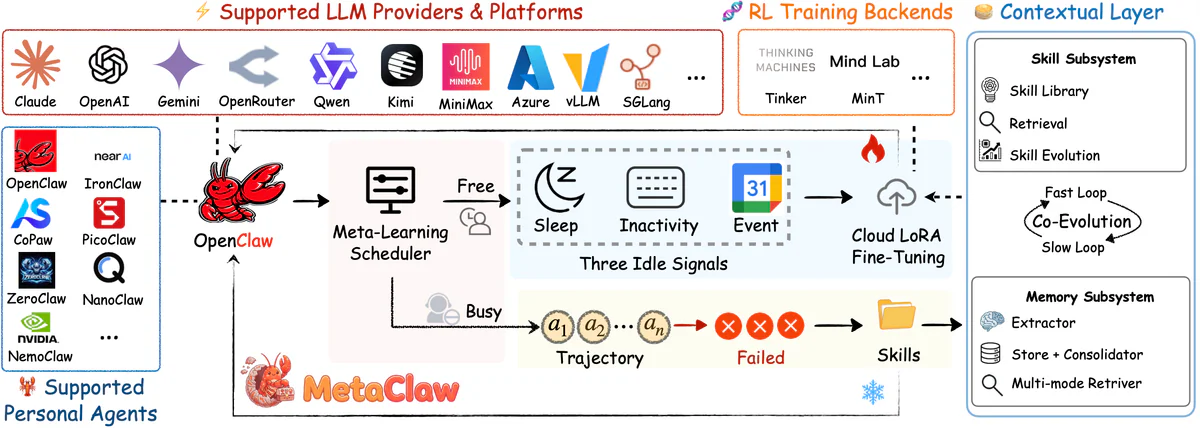
MetaClaw là framework meta-learning liên tục cho LLM agent, vừa release mã nguồn mở (MIT) bởi AIMING Lab (UNC-Chapel Hill, CMU, UC Santa Cruz, UC Berkeley). Nó đứng trước model của bạn như một proxy OpenAI-compatible, phân tích mọi trajectory thất bại để sinh skill mới chèn vào prompt tức thì, và định kỳ fine-tune LoRA trên cloud bằng GRPO — nhưng chỉ chạy khi bạn ngủ, rời bàn phím, hoặc đang họp theo Google Calendar. Không cần GPU local. Không cần dataset. Không downtime.
Kết quả: Kimi-K2.5 nhảy từ 21.4% lên 40.6% accuracy (gần bằng GPT-5.2 baseline 41.1%) và tỉ lệ hoàn thành task end-to-end tăng 8.25×. Paper đạt #1 HuggingFace Daily Papers, repo 3.5k stars sau hơn 1 tháng.

Cái gì mới
Đa số agent framework hiện nay chỉ loay hoay ở lớp prompt: Reflexion lưu self-reflection, Voyager tích luỹ code skill, Mem0 giữ memory hierarchy. Tất cả đều không chạm vào trọng số model. RL khác (GRPO, DAPO) thì cập nhật trọng số nhưng hoạt động offline, yêu cầu dataset có annotation và GPU cluster.
MetaClaw là framework đầu tiên kết hợp cả hai theo một kiến trúc thực tế có thể deploy ngay:
- Fast loop (prompt-level): một LLM evolver đọc trajectory thất bại, chắt lọc thành rule behavioural ngắn gọn (kiểu "backup .bak trước khi xoá", "chuẩn hoá time về ISO 8601", "tuân thủ naming convention"), rồi inject vào system prompt cho mọi turn sau. Zero downtime.
- Slow loop (weight-level): cloud LoRA fine-tuning với GRPO + process reward model (PRM) chấm từng bước trung gian. Chỉ trigger khi bạn vắng mặt.
Hai cơ chế củng cố lẫn nhau: model tốt hơn → failure trajectory thông tin hơn → skill sắc hơn → query data chất lượng hơn cho RL round tiếp theo.
Vì sao đáng quan tâm
Vấn đề cốt lõi của agent production: user ngày nào cũng dùng, task distribution trôi dạt theo ngày, nhưng model thì đứng yên từ lúc deploy. OpenClaw — platform CLI agent kết nối 20+ kênh messaging — là ví dụ điển hình: tuần này là file system ops, tuần sau là multi-agent workflow. Một frozen model nhanh chóng fail trên các dạng task ít xuất hiện khi pretraining.
MetaClaw xử lý bài toán này theo cách kỹ sư — không yêu cầu bạn huấn luyện lại model, không yêu cầu bạn mua GPU, không yêu cầu bạn ngắt dịch vụ. Nó thiết kế cho trường hợp thực tế: agent phải online 24/7, nhưng vẫn phải học được trên tay user.
Chi tiết kỹ thuật
Meta-model được định nghĩa là cặp M = (θ, S): θ là trọng số policy LLM, S là skill library ở dạng natural-language instruction.
- Skill retrieval: embedding-based top-k (cosine similarity trên sentence embedding), inject vào prompt trước mỗi turn.
- Skill evolver: LLM tách biệt, phân tích failure trajectory → sinh skill mới → append vào library. Gradient-free theo thiết kế (không gian skill là discrete natural language).
- Cloud LoRA + GRPO: backend mặc định là Tinker; MinT và Weaver hỗ trợ qua package riêng.
- OMLS (Opportunistic Meta-Learning Scheduler) — background daemon canh 3 tín hiệu idle:
- Sleep window: user cấu hình (vd 23:00–07:00).
- System inactivity: poll OS input-device idle timer (macOS
ioreg HIDIdleTime), default δ = 30 phút. - Google Calendar: trong khung giờ meeting thì coi như user vắng mặt.
- Skill Generation Versioning: mỗi trajectory gắn version
gcủa skill library khi sample. Khig → g+1, trainer flush toàn bộ sample version ≤ g khỏi RL buffer. Ngăn gradient phạt θ vì lỗi mà skill mới đã fix — tránh "stale reward contamination".
Benchmark
MetaClaw-Bench: 934 câu hỏi qua 44 workday giả lập (file edit, JSON structuring, shell scripting). AutoResearchClaw: pipeline research tự động 23 stage.
| Metric (Kimi-K2.5, MetaClaw-Bench Part I) | Baseline | Skills only | Full (Skills+RL) |
|---|---|---|---|
| Accuracy | 21.4% | 28.3% | 40.6% |
| Task completion | 2.0% | — | 16.5% (8.25×) |
GPT-5.2 baseline trên cùng benchmark là 41.1% — nghĩa là mid-tier Kimi-K2.5 sau khi qua MetaClaw gần ngang ngửa frontier GPT-5.2 chưa adapt. Part II file-check completion: 18.2% → 51.9% (+185% relative).
AutoResearchClaw chỉ dùng skill injection (không RL): stage retry giảm 24.8%, refine cycle giảm 40%, composite robustness 0.714 → 0.845 (+18.3%).
So sánh nhanh
| Hướng tiếp cận | Cập nhật weight? | Idle-aware? | Chống stale reward? |
|---|---|---|---|
| Reflexion, Mem0, Voyager | Không | — | — |
| GRPO / RLHF offline | Có (offline) | Không | Không có cơ chế |
| OpenClaw-RL (Princeton) | Có (online, không pause) | Không | Một phần |
| MetaClaw | Có (cloud LoRA) | Có (OMLS) | Có (skill versioning) |
Khác biệt triết lý với OpenClaw-RL: thay vì đẩy mọi tín hiệu vào training real-time, MetaClaw tách rõ fast rule injection và delayed weight update, chấp nhận trade-off latency để giảm rủi ro regression trong session.
Use case thực tế
- DevOps / SRE copilot: học backup-before-destroy, validate JSON schema từ failed run.
- Data engineering: ETL validator học schema mismatch, timestamp format từ pipeline lỗi.
- Customer support agent: ticket escalation → skill chính sách, agent không lặp lỗi cũ.
- Developer productivity: repo-specific lint rule, unit test fail làm PRM.
- Autonomous research: AutoResearchClaw đã chứng minh skill-only giảm retry/refine đáng kể trên pipeline 23-stage.
- Compliance (finance/health/legal): PII redaction, retention rule dưới dạng versioned skill.
Biggest win: indie dev + startup cost-sensitive. Mid-tier LLM (Kimi-K2.5) + MetaClaw ≈ frontier GPT-5.2 baseline — cắt inference cost mà vẫn giữ capability.
Giới hạn & pricing
- License MIT, framework free. Nhưng cần cloud LoRA endpoint (Tinker/MinT/Weaver) — paper không tiết lộ chi phí Tinker cloud.
- Benchmark là simulation có thiết kế, không phải live user traffic. Các số trên không chuyển thẳng sang production.
- OMLS phụ thuộc Google Calendar + OS idle API — yếu trên headless server, shared workstation, hoặc môi trường doanh nghiệp hạn chế network.
- Full pipeline chỉ được test với Kimi-K2.5 (do sẵn cloud LoRA endpoint); các backbone khác chưa có dữ liệu.
- Trade-off task-type: RL nâng file-check execution nhưng giảm nhẹ multi-choice accuracy do policy shift.
- Skill evolver có thể sinh rule sai/trùng/xung đột — chưa có pipeline validate + dedup tự động.
- Rủi ro prompt injection: adversarial trajectory có thể "seed" skill xấu và được áp dụng lâu dài. Chưa có safety-vetting pipeline.
- Privacy: framework đọc file system state, calendar, conversational trajectory — chưa có on-device alternative hoặc PII safeguard chính thức.
Timeline & roadmap
- 09/03/2026: v0.1 release.
- 13/03: v0.3 — OMLS + support/query versioning.
- 16/03: v0.3.2 — multi-claw (IronClaw, PicoClaw, NanoClaw, NemoClaw...).
- 18/03: technical report — #1 HuggingFace Daily Papers.
- 25/03: v0.4.0 — Contexture (cross-session memory layer).
- 11/04: v0.4.1 — incremental memory ingestion.
Hướng nghiên cứu tiếp: finer event-driven scheduling, hierarchical skill retrieval, federated skill sharing cross-org, on-device LoRA hot-swap, và "SkillOps" marketplace chuẩn hoá. Đáng theo dõi với ai đang xây personal agent hoặc vertical copilot.
Nguồn: GitHub aiming-lab/MetaClaw, arXiv 2603.17187, metaclaw.bot, The Decoder.


