
- Google Cloud AI Research vừa công bố ReasoningBank — một memory framework cho LLM agent, chuyển trải nghiệm (bao gồm cả lỗi) thành chiến lược tái sử dụng được.
- Kết quả: +8.3 điểm success rate trên WebArena, -16% interaction steps, mở ra một chiều scaling mới cho AI agent.
TL;DR
ReasoningBank là agent memory framework mới từ Google Cloud AI Research (ICLR 2026, arXiv:2509.25140) giúp LLM agent học liên tục sau khi deploy — từ cả trải nghiệm thành công lẫn thất bại — mà không cần retrain. Kết quả: tăng success rate tới +34.2% relative, giảm 16% số interaction step trên các benchmark web browsing và software engineering. Cặp đôi với MaTTS (Memory-aware Test-Time Scaling), nó mở ra một chiều scaling mới cho agent — scaling bằng kinh nghiệm, không phải bằng params.
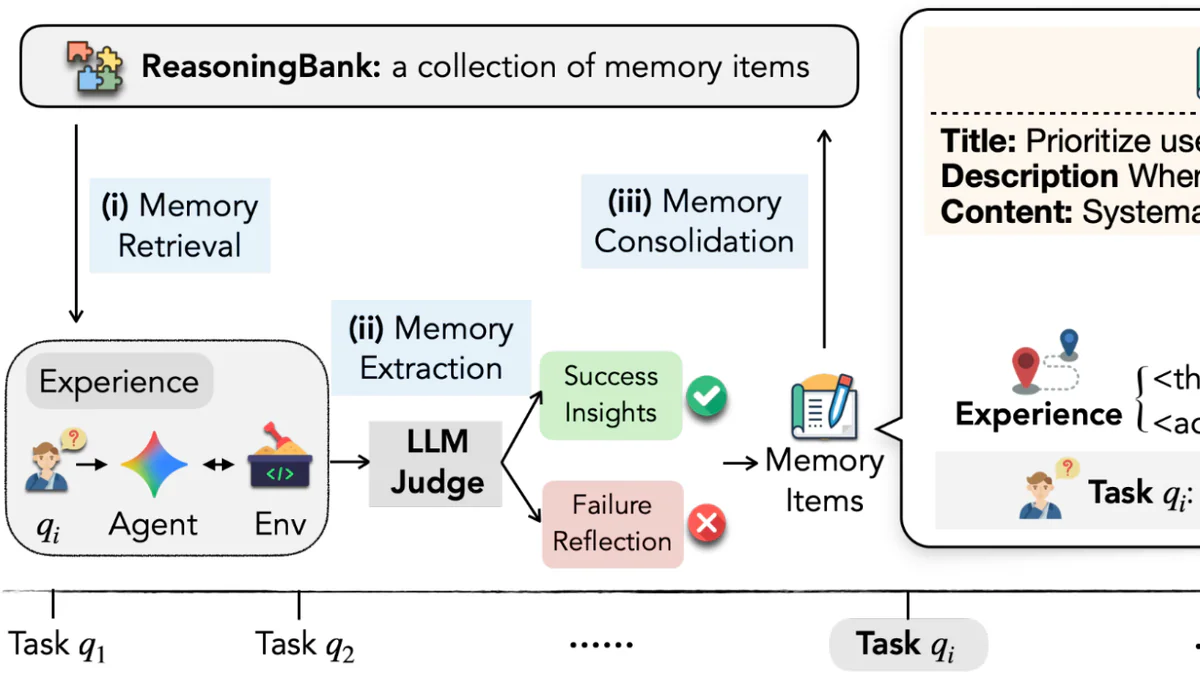
What's new
Trước ReasoningBank, "memory" cho agent có hai trường phái chính và cả hai đều bỏ qua thất bại:
- Synapse (raw-trajectory memory): lưu đầy đủ log action step-by-step. Đầy, nhiễu, khó transfer sang task khác.
- AWM — Agent Workflow Memory: lưu workflow rút gọn nhưng chỉ từ run thành công. Cứng, dễ vỡ khi đổi môi trường.
ReasoningBank thay đổi cách đặt vấn đề: thay vì lưu cái agent làm, lưu cái agent học được. Mỗi trải nghiệm (thành công HAY thất bại) được distill thành một memory item 3 phần:
- Title — tên chiến lược ngắn gọn
- Description — tóm tắt 1 câu
- Content — reasoning steps, heuristics, guardrails, negative constraints
Vòng lặp: retrieve → inject → execute → LLM-as-judge → distill → append. Không có ground-truth label — agent tự phán xét trajectory của chính nó bằng một LLM-judge, và paper chứng minh framework robust với judgment noise.
Điểm đột phá thực sự: từ thất bại, agent không chỉ học "đừng lặp lại" mà học preventative logic. Ví dụ nổi tiếng trong paper: thay vì ghi nhớ "click nút Load More", agent học được "luôn verify page identifier trước để tránh bẫy infinite scroll trước khi cố load more results". Đó là một guardrail, không phải một bước bấm nút.
Why it matters
Mô hình hiện tại đang đâm vào hai bức tường:
- Pretraining scaling đang cạn — thêm params và data không còn trả về gain tuyến tính như trước.
- Agent deploy ngoài thực tế vẫn lặp lại lỗi cũ — mỗi task như một trang giấy trắng, mọi insight ở task trước bị vứt đi.
ReasoningBank chỉ ra một chiều scaling thứ ba: experience scaling. Không cần thêm data train. Không cần retrain model. Agent tự tích luỹ chiến lược qua chính các lần run trong production và dùng lại. Đây là điều rất nhiều đội deploy agent (coding assistant, browser agent, support agent) đang cần nhưng thiếu công cụ làm đúng.
Thêm nữa, vì memory item là reasoning pattern chứ không phải DOM-specific action, nó transfer được cross-website, cross-domain — điều mà workflow memory truyền thống làm rất tệ (AWM thậm chí degrade khi nạp thêm failure trajectory vào).
Technical facts
Paper test trên 3 backbone (Gemini-2.5-flash, Gemini-2.5-pro, Claude-3.7-sonnet) qua 3 benchmark: WebArena (684 task web nav), Mind2Web (1.341 task, cross-task/site/domain), và SWE-Bench-Verified (500 repo-level bug-fix).
WebArena — success rate (%) + avg steps:
| Backbone | No Memory | ReasoningBank | Gain | Steps (no-mem → RB) |
|---|---|---|---|---|
| Gemini-2.5-flash | 40.5 | 48.8 | +8.3 | 9.7 → 8.3 |
| Gemini-2.5-pro | 46.7 | 53.9 | +7.2 | 8.8 → 7.4 |
| Claude-3.7-sonnet | 41.7 | 46.3 | +4.6 | 8.0 → 7.3 |
SWE-Bench-Verified: Gemini-2.5-flash 34.2 → 38.8 (+4.6), giảm 30.3 → 27.5 step mỗi task. Gemini-2.5-pro 54.0 → 57.4 (+3.4).
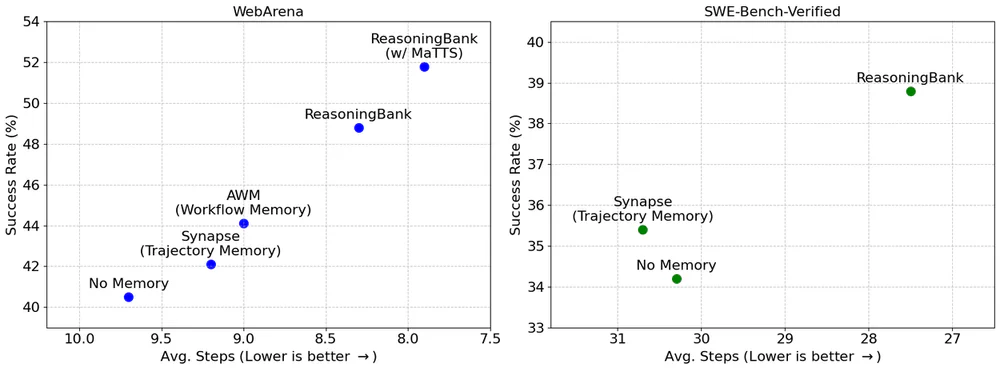
Đáng chú ý: việc giảm step chủ yếu xảy ra ở successful trials (tới 2.1 step ít hơn, giảm 26.9% tương đối), chứng tỏ agent đi thẳng tới đáp án đúng hơn, không phải bỏ cuộc sớm.
MaTTS scaling (WebArena-Shopping, Gemini-2.5-flash):
- Parallel, k=1 → k=5: 49.7% → 55.1% SR
- Sequential, k=1 → k=5: 49.7% → 54.5% SR
- Ở k=5, MaTTS đánh bại vanilla TTS (no memory aggregation): 55.1 vs 52.4 (parallel), 54.5 vs 51.9 (sequential)
Comparison
Câu hỏi quan trọng: failure có thực sự giúp được? Ablation trên WebArena-Shopping cho thấy sự khác biệt rất rõ:
| Method | Success-only | Success + failures |
|---|---|---|
| Synapse | 40.6 | 41.7 (tăng không đáng kể) |
| AWM | 44.4 | 42.2 (tụt) |
| ReasoningBank | 46.5 | 49.7 (tăng) |
AWM thực sự bị hại khi có failure data — vì nó được thiết kế để sao chép workflow thành công, thất bại chỉ là noise. Chỉ ReasoningBank biến failure thành signal xây dựng.

Use cases
Ai được lợi nhiều nhất?
- Lifelong autonomous agent: coding assistant, browser-use agent, support bot — mọi agent phải chạy liên tục và không được lặp lại sai lầm cũ.
- Agent cross-domain: memory là reasoning pattern ("verify pagination mode", "prefer account pages cho user-specific data"), không phải DOM-specific. Transfer tốt cross-website, cross-domain.
- Hệ thống dùng test-time scaling: MaTTS biến các rollout vốn bị vứt đi thành nhiên liệu cho memory — scaling hiệu quả hơn nhiều lần.
Paper ghi nhận một hiện tượng đẹp: emergent strategic maturity. Qua thời gian, memory items tự tiến hoá — từ checklist thủ tục ("tìm navigation link") → self-reflection ("verify identifier") → adaptive check ("leverage search/filter trước khi result") → compositional strategy ("cross-reference task spec với active filter"). Động lực học giống RL nhưng không có training.
Limitations & availability
- Retrieval & consolidation tối giản: paper cố ý giữ embedding-based similarity + append-only để isolate hiệu ứng của content quality. Chưa có merging, forgetting, pruning.
- Phụ thuộc LLM-as-a-judge: có nguy cơ noise nếu judge model sai. Thực nghiệm cho thấy robust, nhưng future work sẽ thêm ensemble judge hoặc human-in-the-loop.
- Chưa so sánh với episodic/hierarchical memory: paper nhấn mạnh đây là đóng góp về nội dung memory, không phải kiến trúc.
- Availability: open-source trên GitHub (link từ blog Google Research và arXiv), chưa phải sản phẩm thương mại. Bring-your-own agent + LLM. Đã test với Gemini-2.5 và Claude-3.7.
What's next
Roadmap tương lai (Appendix D của paper):
- Compositional memory: retrieval biết kết hợp nhiều item thành macro cho long-horizon task.
- Layered memory stack: episodic (per-task) + short-term working memory + long-term consolidated với decay/refresh policy.
- Reasoning-intensive retrieval controller: multi-hop lookup, chọn memory dựa trên uncertainty/recency/cost thay vì cosine similarity.
- Stronger verifier: ensemble judge, human-in-the-loop, giảm noise của self-judgment.
- Mục tiêu cuối: biến ReasoningBank + MaTTS thành deployable memory service dùng chéo nhiều domain và team.
Thông điệp lớn hơn: memory-driven experience scaling có thể là chiều scaling tiếp theo của AI agent, bên cạnh data scaling và compute scaling. Nó biến mỗi agent đã deploy thành một "học sinh" thay vì một "cỗ máy lặp lại".
Nguồn: Google Research Blog, arXiv 2509.25140 (ICLR 2026), VentureBeat.
