
- LimX Dynamics vừa open-source FluxVLA Engine — framework full-stack gom data, training, sim, và deploy robot về một config duy nhất.
- Hỗ trợ GR00T, Pi0.5, OpenVLA, Qwen-VL; tăng tốc inference 5–10× nhờ Triton + CUDA Graph; LIBERO avg 98.4.
- Training-to-deploy chỉ ~30 phút.
TL;DR
FluxVLA Engine là framework engineering full-stack cho Vision-Language-Action models, vừa được LimX Dynamics open-source trên GitHub dưới giấy phép Apache-2.0. Nó giải quyết 3 nỗi đau lớn nhất của embodied AI hiện nay: dữ liệu phân mảnh giữa các giai đoạn, code train–sim–deploy bị coupling chặt, và khoảng cách sim-to-real khi triển khai lên robot thật. Một file config duy nhất chạy toàn bộ pipeline từ data đến robot, tăng tốc inference 5–10×, đạt 98.4 điểm trung bình trên LIBERO — và đưa policy từ training đến deployment trong khoảng 30 phút.

Có gì mới
Cho tới trước FluxVLA, mỗi lab robotics tự viết một mớ script để dán ba thế giới lại với nhau: dataset training (HuggingFace / LeRobot format), môi trường sim (LIBERO, Isaac Sim), và stack deploy trên robot thật (UR, ALOHA). Mỗi lần đổi vision encoder hay action head là phải viết lại pipeline — tốn tuần, dễ sai.
FluxVLA gom tất cả về một config file YAML duy nhất, điều khiển data → model → training → evaluation → inference → deployment. Interface chuẩn hoá cho phép swap module như LEGO: đổi backbone từ Qwen 2.5 sang Llama 2, hoặc đổi action head từ Diffusion Transformer sang Flow Matching Head mà không phải chạm training loop.
Vì sao quan trọng
Embodied AI đang ở đúng thời điểm NLP năm 2019 — trước khi HuggingFace Transformers xuất hiện. Research chạy nhanh, nhưng mỗi nhóm viết lại infrastructure từ đầu, khiến benchmarks không so sánh được và policy khó tái sản xuất. FluxVLA đặt cược vào chuẩn hoá như con đường để cộng đồng cùng đi nhanh hơn.
Với startup robotics, lợi ích cụ thể: một dev có thể đưa demo từ Isaac Sim lên cánh tay UR thật trong cùng buổi chiều, thay vì mất 2 tuần viết adapter. Với lab nghiên cứu, ablation study giờ là đổi 3 dòng config thay vì fork cả repo.
Thông số kỹ thuật
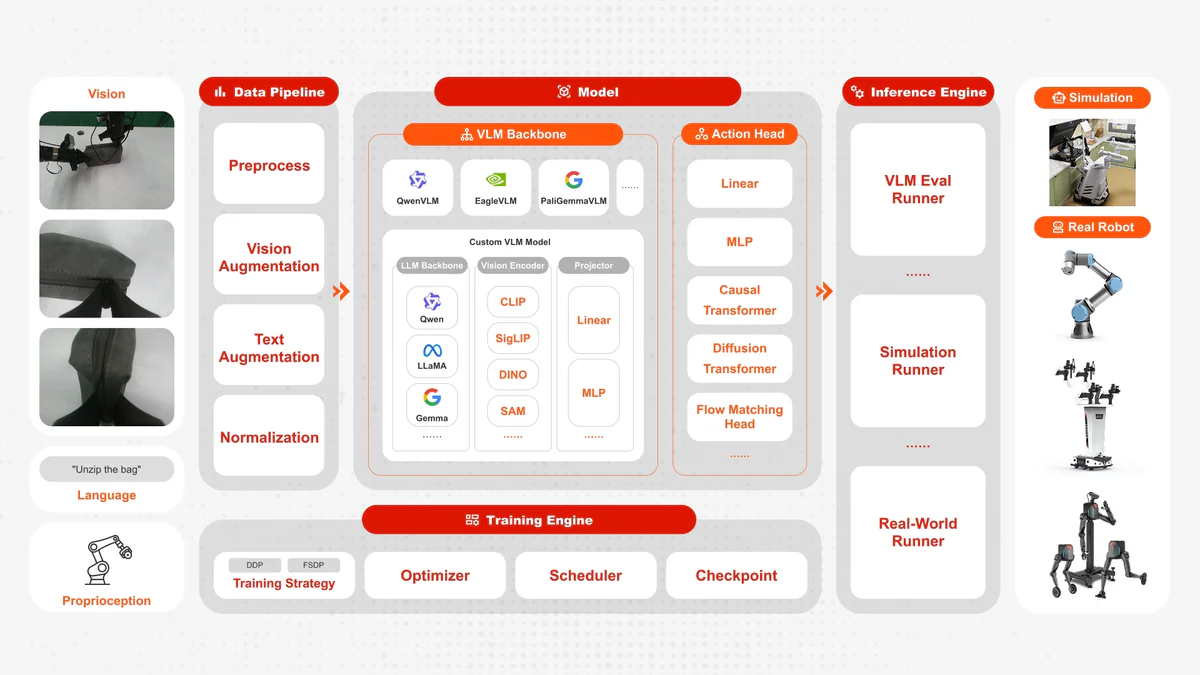
Framework chia 4 tầng — Data Pipeline, Model, Training Engine, Inference Engine — giao tiếp qua interface chuẩn.
| Thành phần | Tuỳ chọn hỗ trợ |
|---|---|
| VLA models | OpenVLA (7B), LlavaVLA, GR00T N1.5 (3B), Pi0, Pi0.5 |
| LLM backbones | Qwen 2.5 (3B/7B), Llama 2 (7B), Gemma |
| Vision backbones | DINOv2, SigLIP, SigLIP2, PaliGemma |
| VLM backbones | Qwen2.5-VL (3B), Qwen-VL |
| Training | FSDP + DDP, LoRA, eval-after-train, resume checkpoint |
| Inference | Triton fused kernels, CUDA Graph capture, CUDA custom ops |
| Simulation | LIBERO (multi-GPU, không cần ray tracing) |
| Robots | UR3, ALOHA, AgileX ALOHA, LimX TRON 2 |
Điểm nhấn là RTC (Real-Time Chunking) — kỹ thuật smoothing trajectory giữa các chunk inference, giúp robot chuyển động mượt khi policy sinh action theo từng đoạn, khép lại khoảng cách sim-to-real.
So sánh với các lựa chọn khác
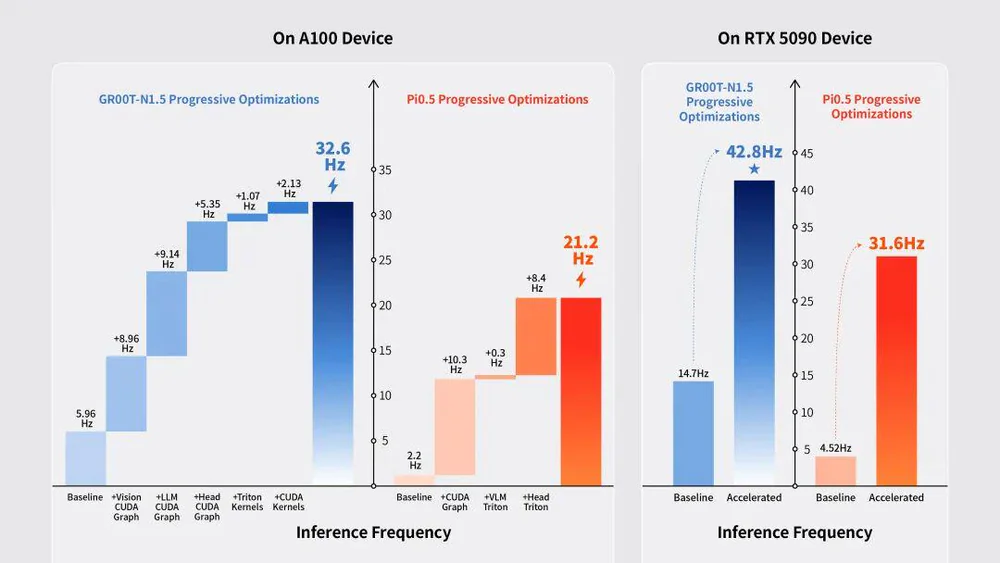
Trên A100, GR00T N1.5 baseline chạy 5.96 Hz — sau khi bật tuần tự Vision CUDA Graph, LLM CUDA Graph, Head CUDA Graph, và Triton Kernels thì đạt 32.6 Hz (≈5.5×). Pi0.5 từ 2.2 Hz lên 21.2 Hz (~9.6×). Trên RTX 5090, con số còn cao hơn: GR00T đạt 42.8 Hz, Pi0.5 đạt 31.6 Hz.
| Khung | Điểm mạnh | Khác biệt của FluxVLA |
|---|---|---|
| OpenVLA (Stanford) | Một model + recipe training | FluxVLA host OpenVLA như 1 trong nhiều backbone, bổ sung deploy path |
| NVIDIA Isaac GR00T | Foundation model cho humanoid | FluxVLA wrap GR00T N1.5 và tăng tốc 5.5–7× qua Triton + CUDA Graph |
| StarVLA | Codebase kiểu LEGO | FluxVLA ship thêm deploy tới UR/ALOHA/TRON 2 out-of-the-box |
Trên benchmark LIBERO, FluxVLA(Pi) đạt 99.4 Spatial, 99.4 Object, 98.0 Goal, 96.8 Long — trung bình 98.4. Biến thể FluxVLA(Qwen3VL+GR00T) đạt 98.0–99.2.
Use cases
- Lab nghiên cứu VLA: thử kiến trúc mới (ví dụ thay Causal Transformer bằng Flow Matching) mà không viết lại training loop.
- Startup robotics: đưa policy demo từ LIBERO sim lên UR3 hoặc ALOHA bimanual rig trong một chiều.
- Humanoid builder: dùng TRON 2 adapter cùng GR00T N1.5, chạy real-world runner mà không cần custom infra.
- Industrial integrator: pipeline tái sản xuất được từ demonstration data đến triển khai nhà máy, rút workflow từ vài tuần xuống ~30 phút.
Giới hạn & chi phí
Framework hoàn toàn miễn phí, Apache-2.0. Yêu cầu GPU CUDA 12.4; OpenVLA 7B cần multi-GPU. Các cánh tay ngoài danh sách (UR3, ALOHA, AgileX, TRON 2) sẽ phải viết adapter riêng. LIBERO là sim native; Isaac Sim integration đã được announce nhưng docs sâu vẫn đang hoàn thiện. Ưu tiên Linux, chưa có Windows chính thức.
Sắp tới
LimX Dynamics định vị FluxVLA là "HuggingFace Transformers cho VLA" — lớp chuẩn hoá để nghiên cứu embodied AI tiến nhanh hơn. Roadmap theo cấu trúc repo cho thấy hướng mở rộng: thêm VLA backbones, tích hợp sim sâu hơn với Isaac Sim, adapter cho nhiều robot khác, và backbone LLM lớn hơn cho tác vụ phức tạp.
Nguồn: GitHub limxdynamics/FluxVLA, ModelScope LimXDynamics/FluxVLAEngine, ModelScope X announcement.


